一、继承nn.Module类并自定义层
我们要利用pytorch提供的很多便利的方法,则需要将很多自定义操作封装成nn.Module类。
首先,简单实现一个Mylinear类:
from torch import nn # Mylinear继承Module class Mylinear(nn.Module): # 传入输入维度和输出维度 def __init__(self,in_d,out_d): # 调用父类构造函数 super(Mylinear,self).__init__() # 使用Parameter类将w和b封装,这样可以通过nn.Module直接管理,并提供给优化器优化 self.w = nn.Parameter(torch.randn(out_d,in_d)) self.b = nn.Parameter(torch.randn(out_d)) # 实现forward函数,该函数为默认执行的函数,即计算过程,并将输出返回 def forward(self, x): x = x@self.w.t() + self.b return x
这样就可以将我们自定义的Mylinear加入整个网络:
# 网络结构 class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( #nn.Linear(784, 200), Mylinear(784,200), nn.BatchNorm1d(200, eps=1e-8), nn.LeakyReLU(inplace=True), #nn.Linear(200, 200), Mylinear(200, 200), nn.BatchNorm1d(200, eps=1e-8), nn.LeakyReLU(inplace=True), #nn.Linear(200, 10), Mylinear(200,10), nn.LeakyReLU(inplace=True) )
我们可以看出,MLP网络实际上也是继承自Module,这就说明了,nn.Module实际上可以实现一个嵌套的结构,我们的整个网络就是由一个嵌套的树形结构组成的。例如:
# Mylinear继承Module class Mylinear(nn.Module): # 传入输入维度和输出维度 def __init__(self, in_d, out_d): # 调用父类构造函数 super(Mylinear, self).__init__() # 使用Parameter类将w和b封装,这样可以通过nn.Module直接管理,并提供给优化器优化 self.w = nn.Parameter(torch.randn(out_d, in_d)) self.b = nn.Parameter(torch.randn(out_d)) # 实现forward函数,该函数为默认执行的函数,即计算过程,并将输出返回 def forward(self, x): x = x @ self.w.t() + self.b return x # 将几个nn.Module组件综合成一个 class Mylayer(nn.Module): def __init__(self, in_d, out_d): super(Mylayer, self).__init__() # 包含一个全连接层,一个BN层,一个Leaky Relu层 self.lin = Mylinear(in_d, out_d) self.bn = nn.BatchNorm1d(out_d, eps=1e-8) self.lrelu = nn.LeakyReLU(inplace=True) # 按顺序跑一遍3种网络,返回最终结果 def forward(self, x): x = self.lin(x) x = self.bn(x) x = self.lrelu(x) return x # 网络结构 class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( Mylayer(784, 200), Mylayer(200, 200), # nn.Linear(200, 10), Mylinear(200, 10), nn.LeakyReLU(inplace=True) )
上述代表表示的结构如下图所示:
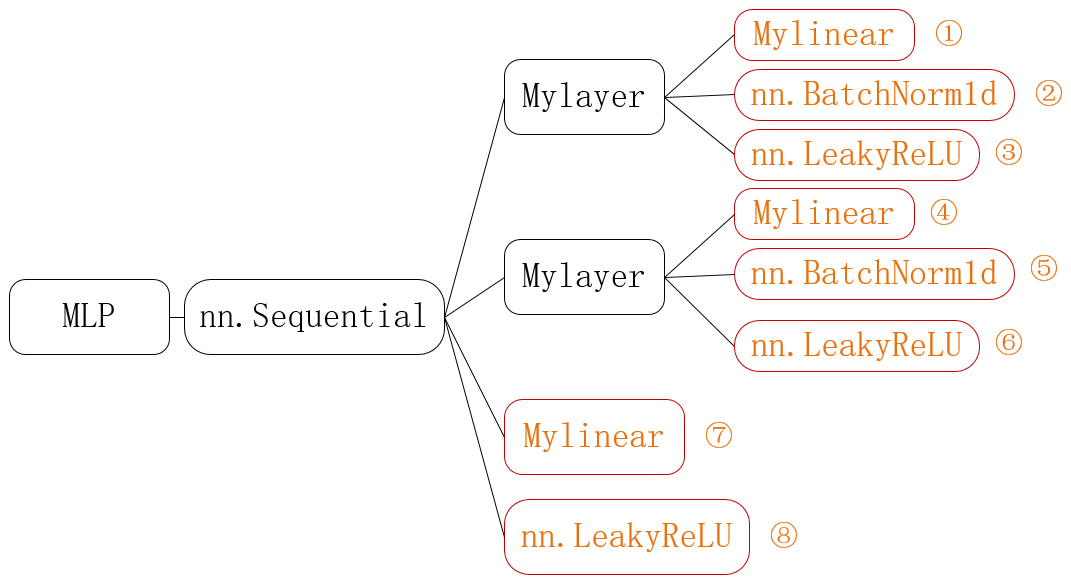
其中所有的类都继承自nn.Module,从前往后是嵌套的关系。在上述代码中,真正做计算的是橙色部分1-8,而其他的都只是作为封装。其中nn.Sequential、nn.BatchNorm1d、nn.LeakyReLU是pytorch提供的类,Mylinear和Mylayer是我们自己封装的类。
二、实现一个常用类Flatten类
Flatten就是将2D的特征图压扁为1D的特征向量,用于全连接层的输入。
# Flatten继承Module class Flatten(nn.Module): # 构造函数,没有什么要做的 def __init__(self): # 调用父类构造函数 super(Flatten, self).__init__() # 实现forward函数 def forward(self, input): # 保存batch维度,后面的维度全部压平,例如输入是28*28的特征图,压平后为784的向量 return input.view(input.size(0), -1)
三、nn.Module类的作用
1.便于保存模型:
# 每隔N epoch保存一次模型 torch.save(net.state_dict(),'ckpt_n_epoch.mdl') # 下次训练时可以直接导入接着训练 net.load_state_dict(torch.load('ckpt_n_epoch.mdl'))
2.方便切换train和val模式
### 不同模式对于某些层的操作时不同的,例如BN,dropout层等 # 切换到train模式 net.train() # 切换到validation模式 net.eval()
3.方便将网络转移到GPU上
# 定义GPU设备 device = torch.device('cuda') # 将网络转移到GPU,注意to函数返回的是net的引用(引用是不变的) # 不同的是net中的参数都转移到GPU上去了 net.to(device) # 不同于参数直接转移,转移后的w2(在GPU上)和转移前的w(在CPU上)两者完全是不一样的 # 我们要使之在GPU上运行,则必须使用w2 #w2 = w.to(device)
4.方便查看各层参数
# 获取由每一层参数组成的列表 para_list = list(net.parameters()) # 获取一个(name,每层参数)的tuple组成的列表 para_named_list = list(net.named_parameters()) # 获取一个{'model.0.weight': 参数,'model.0.bias': 参数, 'model.1.weight': 参数} para_named_dict = dict(net.named_parameters())
四、数据增强
torchvision提供了很方便的数据预处理工具,数据增强可以一次性搞定。
from torchvision import datasets, transforms train_data_trans = datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ # 水平翻转,50%执行 transforms.RandomHorizontalFlip(), # 垂直翻转,50%执行 transforms.RandomVerticalFlip(), # 随机旋转范围在正负15°之间,也可以写(-15,15) transforms.RandomRotation(15), # 旋转范围在90-270之间 #transforms.RandomRotation([90,270]), # 将图片方缩放到指定大小 transforms.Resize([32,32]), # 随机剪裁图片到指定大小 transforms.RandomCrop([28,28]), transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]))
如果pytorch没有提供需要的预处理类,我们可以参照源码仿造写一个自定义处理的类来进行处理。例如对图片添加白噪声,按通道变换颜色等等。