bilibili莫烦scikit-learn视频学习笔记
1.使用KNN对iris数据分类
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # 从datasets中导入iris数据,包含150条样本,每条样本4个feature iris_data = datasets.load_iris() # 获取feature iris_x = iris_data.data # 获取标签 iris_y = iris_data.target print(iris_x.shape) print(iris_y) # 将数据集分为训练集和测试集,比例是70%:30% train_x, test_x, train_y, test_y = train_test_split(iris_x, iris_y, test_size=0.3) # 使用knn分类器(n_neighbors表示通过附近的几个邻居来确定分类,一般为单数) knn = KNeighborsClassifier(n_neighbors = 5) # 训练 knn.fit(train_x, train_y) # 测试 print(knn.predict(test_x)) print(test_y)
2.使用线性回归预测Boston房价
from sklearn import datasets from sklearn.linear_model import LinearRegression # 从datasets中载入Boston房价数据集 loaded_data = datasets.load_boston() # 包含506条样本,每条样本13个feature data_x = loaded_data.data # 标签,即房价(万) data_y = loaded_data.target # 线性回归器 lr = LinearRegression() # 训练 lr.fit(data_x, data_y) # 预测前6条样本的房价 print(lr.predict(data_x[:6, :])) # 与标签对比,可以看出准确度 print(data_y[:6])
3.如何创建线性数据(实验数据)
from sklearn import datasets import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression # 使用make_regression函数生成线性回归数据集,100个样本,1个feature,noise控制噪声即偏移度 made_data_x, made_data_y = datasets.make_regression(n_samples=100, n_features=1, n_targets=1, noise=30) # 使用matplotlib画散点图 plt.scatter(made_data_x, made_data_y) # 显示图像 plt.show() # 使用线性回归器来进行训练和预测 lr = LinearRegression() lr.fit(made_data_x, made_data_y) print(lr.predict(made_data_x[:5, :])) print(made_data_y[:5]) # 打印学习到的参数集,y = wx + b print(lr.coef_) # output w,w是一个向量,数量和n_features一致 print(lr.intercept_) # output b,b即bias
4.输出模型的一些参数
# 打印学习到的参数集,y = wx + b print(lr.coef_) # output w,w是一个向量,数量和n_features一致,w = [28.44936087] print(lr.intercept_) # output b,b即bias = -2.787101732423871 # 打印LinearRegression的参数值,未手工设置则打印默认参数 print(lr.get_params()) # 打印{'copy_X': True, 'fit_intercept': True, 'n_jobs': 1, 'normalize': False} # 使用数据进行测试,并打分,在回归中使用R^2 coefficient of determination print(lr.score(test_x, test_y))
5.使用SVC进行分类(数据伸缩)
import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing from sklearn.model_selection import train_test_split from sklearn.datasets.samples_generator import make_classification # 从svm模块中导入support vector classifier from sklearn.svm import SVC # 创建数据集 X, y = make_classification(n_samples=3000, n_features=2, n_redundant=0, n_informative=2, random_state=22, n_clusters_per_class=1, scale=100) # 画图c=y的意思是颜色根据y来区分 plt.scatter(X[:, 0], X[:, 1], c=y) plt.show() # 将数据伸缩为[0,1] scales_x = preprocessing.scale(X) # 伸缩后的数据方差为1.0 print(np.std(scales_x)) # 使用SVC分类器分类 train_x, test_x, train_y, test_y = train_test_split(scales_x, y, test_size=0.3) model = SVC() model.fit(train_x, train_y) # 模型分类准确率大概为0.90 print(model.score(test_x, test_y))
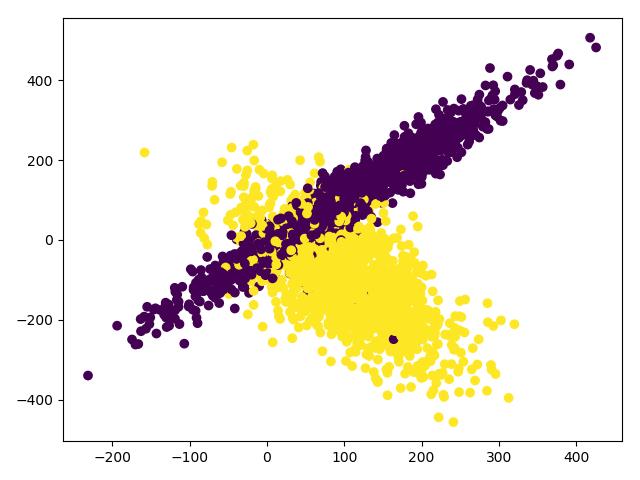
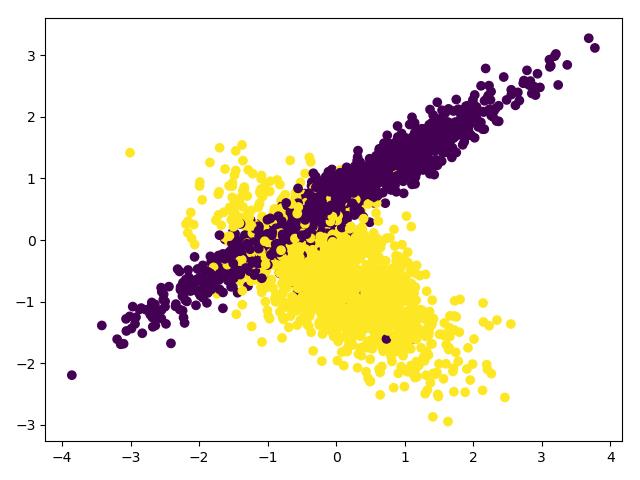
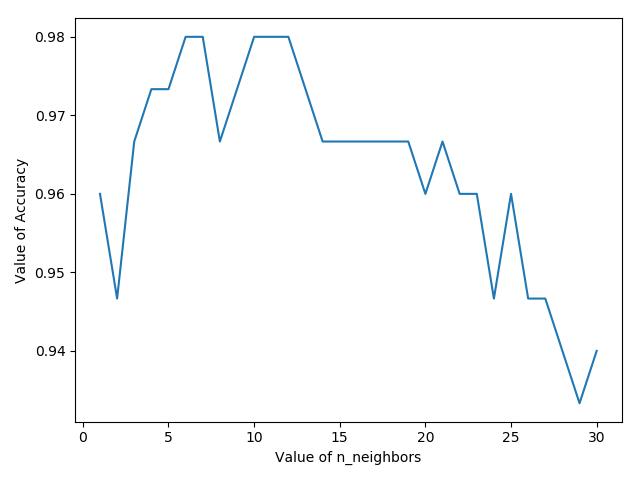
6.KNN分类iris,交叉验证,参数选择并可视化
import matplotlib.pyplot as plt from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier # 导入交叉验证 from sklearn.model_selection import cross_val_score # 从datasets中导入iris数据,包含150条样本,每条样本4个feature iris_data = datasets.load_iris() iris_x = iris_data.data iris_y = iris_data.target # 尝试n_neighbors为不同值时,模型准确度 nb = range(1, 31) # 保存每次n_neighbors对应准确率,用于plt画图 k_scores = [] for k in nb: # 使用KNN模型 knn = KNeighborsClassifier(n_neighbors=k) # 使用交叉验证,不需要自己去切分数据集,也不需要knn.fit()和knn.predict(),cv=5表示交叉验证5组 scores = cross_val_score(knn, iris_x, iris_y, cv=5, scoring='accuracy') # 取交叉验证集的平均值 k_scores.append(scores.mean()) # 画出n_neighbor于accuracy的关系图 plt.plot(nb,k_scores) plt.xlabel("Value of n_neighbors") plt.ylabel("Value of Accuracy") plt.show()
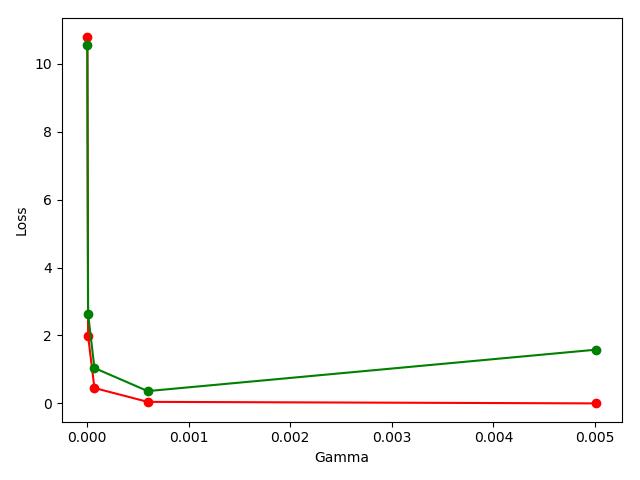
7.使用交叉验证,并画出学习曲线learning_curve,用于观察模型拟合情况
import numpy as np import matplotlib.pyplot as plt # 导入sklearn提供的损失曲线 from sklearn.model_selection import learning_curve from sklearn.datasets import load_digits from sklearn.svm import SVC # 导入数据 digits = load_digits() X = digits.data y = digits.target # 使用学习曲线获取每个阶段的训练损失和交叉测试损失,train_sizes表示各个不同阶段,从10%到100% train_sizes, train_loss, test_loss = learning_curve( SVC(gamma=0.001), X, y, cv=10, scoring='neg_mean_squared_error', train_sizes=np.linspace(0.1, 1, 10) ) # 将每次训练集交叉验证(10个损失值,因为cv=10)取平均值 train_loss_mean = -np.mean(train_loss, axis=1) print(train_loss_mean) # 将每次测试集交叉验证取平均值 test_loss_mean = -np.mean(test_loss, axis=1) print(test_loss_mean) # 画图,红色是训练平均损失值,绿色是测试平均损失值 plt.plot(train_sizes, train_loss_mean, 'o-', color='r', label='Training') plt.plot(train_sizes, test_loss_mean, 'o-', color='g', label='Cross_validation') plt.xlabel('Train sizes') plt.ylabel('Loss') plt.show()

8.使用交叉验证,并画出验证曲线validation_curve,用于观察模型参数不同时的准确率
import numpy as np import matplotlib.pyplot as plt # 导入sklearn提供的验证曲线 from sklearn.model_selection import validation_curve from sklearn.datasets import load_digits from sklearn.svm import SVC # 导入数据 digits = load_digits() X = digits.data y = digits.target # SVC参数gamma的范围 param_range = np.logspace(-6, -2.3, 5) # 使用validation曲线,指定params的名字和范围 train_loss, test_loss = validation_curve( SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='neg_mean_squared_error' ) # 将每次训练集交叉验证(10个损失值,因为cv=10)取平均值 train_loss_mean = -np.mean(train_loss, axis=1) print(train_loss_mean) # 将每次测试集交叉验证取平均值 test_loss_mean = -np.mean(test_loss, axis=1) print(test_loss_mean) # 画图,红色是训练平均损失值,绿色是测试平均损失值,注意这里的x坐标是param_range plt.plot(param_range, train_loss_mean, 'o-', color='r', label='Training') plt.plot(param_range, test_loss_mean, 'o-', color='g', label='Cross_validation') plt.xlabel('Gamma') plt.ylabel('Loss') plt.show()
9.使用pickle保存模型到文件
import pickle from sklearn.datasets import load_iris from sklearn.svm import SVC iris = load_iris() X = iris.data y = iris.target # # 使用SVC模型 # model = SVC() # # 训练模型 # model.fit(X,y) # # 使用pickle保存模型到文件中 # with open('save/model.pickle','wb') as fp: # pickle.dump(model,fp) # 从文件中load模型 with open('save/model.pickle', 'rb') as fp: model_read = pickle.load(fp) # 使用load出的模型预测 print(model_read.predict(X[0:1]))
10.使用joblib保存模型到文件
from sklearn.datasets import load_iris from sklearn.svm import SVC # 导入外部模块中得joblib用于存储模型 from sklearn.externals import joblib iris = load_iris() X = iris.data y = iris.target # # 使用SVC模型 # model = SVC() # # 训练模型 # model.fit(X,y) # # 使用joblib存放模型到model.jl中 # joblib.dump(model,'save/model.jl') # 从model.jl中读取模型 model_read = joblib.load('save/model.jl') # 用load的模型预测 print(model_read.predict(X[0:1]))