update语句:

本例中由于看到的是update执行完的锁情况,因此无法看到IU锁,但其实针对要修改的数据页和索引页会先加IU锁,记录和键先加U锁,然后再转化为IX和X锁。
如果想要看到IU锁和U锁,可以在update中使用索引列的过滤条件但不更新索引列来实现,这样你可以通过sp_lock看到索引页和索引键上的IU/U锁。
Ps:好像with (uplock)也可以看到U锁,这里提一下就懒得自己去测啦。

其上锁情况为:


可以看到加锁情况如下:
1.添加了表级IX锁
2.针对数据页3105添加了IX锁,以便更新其中数据行
3.对数据页3105中对应的数据行添加了X模式的KEY锁
4.更新完数据后要更新包含ClinicID列的相关索引,我们先看一下涉及到这个列的索引有哪些:(可以看到确实是60号索引)

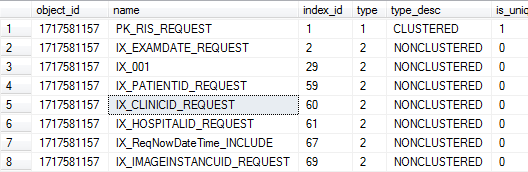
select * from sys.indexes where object_id=OBJECT_ID('RIS_REQUEST')
对索引页50160、1458239添加了IX锁,以便更新其中索引行
5.对以上2个索引页内的索引行添加X模式KEY锁,更新索引行完成。
这里有个疑问:我是按主键进行更新的,这意味着只涉及到一个数据行,索引也应该只有一行对应才对,为何会导致2个索引记录的X模式KEY锁出现?
只能去看50160、1458239这两个页的具体内容了,这里我把两个页的具体内容全部用dbcc page转储出来:
50160页只截取了可能包含主键2012121218060024的部分:


1458239页总共只有这么多行的记录:


可以看到主键值为2012121218060024的索引就是在1458239索引页的第2行,其对应的hash值也是sp_lock中看到的7be5a319785d,而另一个hash值fcee1248c8e6对应的索引行则没有找到,这可以预见,因为ClinicID被更新后其HASH值必定发生变化。