1: 先阅读这边文章:http://www.importnew.com/21517.html
2:被transient修饰真的会被序列化吗?
反例:java.util.ArrayList中底层存储数组就是transient,但是实际上还是可以被成功序列化。具体原因如下:
transient Object[] elementData;
我的测试代码:
class ArrayListDemo implements Serializable {
public static void main(String[] args) throws Exception {
ArrayList<Integer> data = new ArrayList<>();
data.add(1);
data.add(1);
data.add(1);
data.add(1);
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream out = new ObjectOutputStream(bo);
out.writeObject(data);
byte[] dataData = bo.toByteArray();
FileOutputStream fo = new FileOutputStream("data.dat");
fo.write(dataData);
fo.close();
FileInputStream fi = new FileInputStream("data.dat");
ObjectInputStream in = new ObjectInputStream(fi);
ArrayList<Integer> newList = (ArrayList<Integer>) in.readObject();
System.out.println(newList.size());
for (int i = 0; i < newList.size(); i++) {
System.out.println(newList.get(i));
}
}
}
输出:
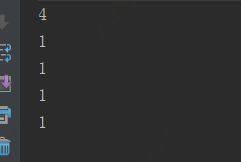
数据还是成功序列化了,为什么会被序列化呢?分析原因还是需要看源码,就以java.io.ObjectOutputStream#writeObject写对象为入手点,跟踪源码会跟中到如下方法java.io.ObjectStreamClass#invokeWriteObject:
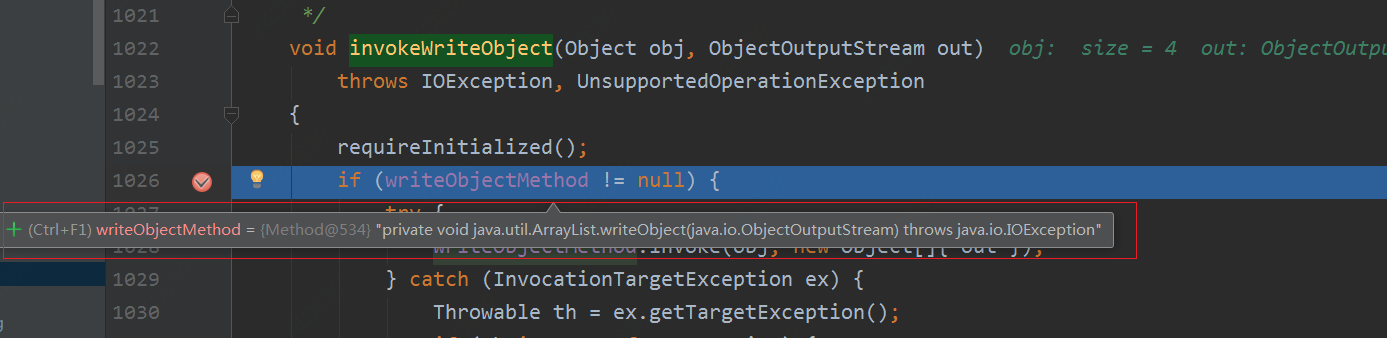
方法源码如下:
void invokeWriteObject(Object obj, ObjectOutputStream out)
throws IOException, UnsupportedOperationException
{
requireInitialized();
if (writeObjectMethod != null) {
try {
writeObjectMethod.invoke(obj, new Object[]{ out });
} catch (InvocationTargetException ex) {
Throwable th = ex.getTargetException();
if (th instanceof IOException) {
throw (IOException) th;
} else {
throwMiscException(th);
}
} catch (IllegalAccessException ex) {
// should not occur, as access checks have been suppressed
throw new InternalError(ex);
}
} else {
throw new UnsupportedOperationException();
}
}
通过debug可以看到最终调用的是java.util.ArrayList#writeObject ,java.util.ArrayList#writeObject源码如下:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}ke
可以看出最终将elementData写出去了。反序列化同理不在分析。
重点来了,name为什么JDK需要这么做呢?原因如下:
JDK为什么不直接用elementData来序列化,而采用上诉的方式来实现序列化呢?原因在于elementData是一个缓存数组,它通常会预留一些容量,等容量不足时再扩充容量,那么有些空间可能就没有实际存储元素,采用上诉的方式来实现序列化时,就可以保证只序列化实际存储的那些元素,而不是整个数组,从而节省空间和时间。
小提示:
java.io.ObjectOutputStream#writeObject中的enableOverride字段可以自行实现writeObjectOverride方法,对于enableOverride=true需要通过实现ObjectOutputStream的子类实现自定义写对象。