参考地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
环境准备:
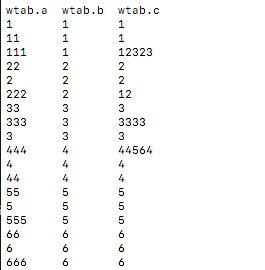
CREATE TABLE `wtab`( `a` int, `b` int, `c` int);
数据:
1、LEAD函数
LEAD (scalar_expression [,offset] [,default]) OVER ([query_partition_clause] order_by_clause); The LEAD function is used to return data from the next row.
lead函数主要是返回窗口中列名为:scalar_expression偏移为offset的值,如果不存在则返回NULL,窗口使用over划分,具体划分参考示例:
SELECT a, LEAD(a,1,9999) OVER (PARTITION BY b ORDER BY C) from wtab;
PARTITION BY 表示根据字段b划分窗口,就是b值相同的划分到一个窗口,ORDER BY 表示窗口内部按照字段C进行排序。此条查询结果为:
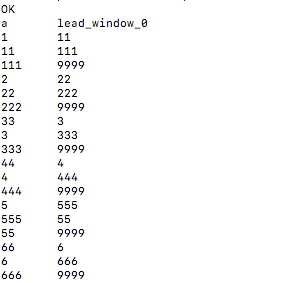
以b=1为例讲解,b相同的都在一个窗口按照c排序之后结果为:
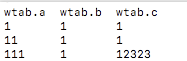
这个就是b=1的窗口,a=1下面offset=1的数据为11,所以查询结果为:1 11 ;其他同理。
2、LAG函数
LAG (scalar_expression [,offset] [,default]) OVER ([query_partition_clause] order_by_clause); The LAG function is used to access data from a previous row.
lag函数与lead函数相反,是向上offset取row,如果row不存在则返回默认值。示例:
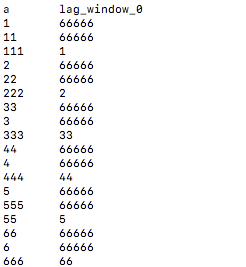
SELECT a, LAG(a, 2, 66666) OVER (PARTITION BY b ORDER BY C) from wtab;
根据字段b划分窗口之后向上offset=2取row,没有的话返回6666
3: FIRST_VALUE(columnName,isSkipNull) 函数
划分窗口之后,取columnName第一个值,第二个参数指定是否忽略null,默认false,示例:
SELECT a, FIRST_VALUE(a,true) OVER (PARTITION BY b ORDER BY C) from wtab;
查询结果
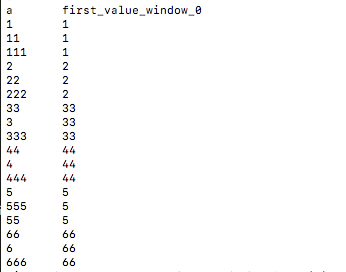
同理LAST_VALUE取当前窗口的最后一个值!如果只是select last_value(a) from table 这种事窗口内全部元素到达之后采取;如果是 select a, last_value(a) from table这种形式是当前a的值的当前窗口取最后一个,当排序的key存在重复值的时候,取值存在不确定。例如数据为:
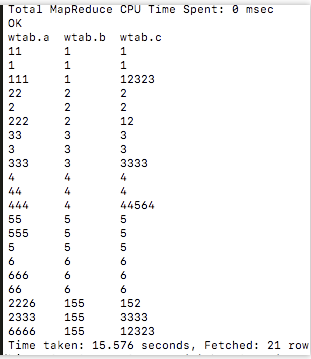
查询为:
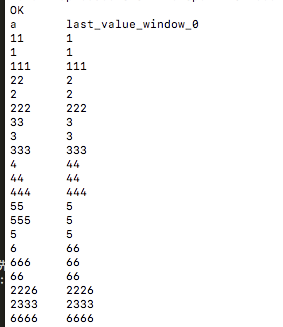
会发现b=1的窗口的last_value有点与预期不一样,这就是由于排序的字段c存在相同的值,由于每一row到达顺序不一样导致结果存在不确定性。但是对于b=155的窗口,字段c不存在重复值,这样就不会存在不确定性!!!!first_value同理,当半路来一个更小的值可能就存在不确定性,
因此:first_value与last_value不要和函数内部使用的字段联合查询:例如select last_value(a),a 这种就是联合查询了,函数内部字段a,外面还有字段a,此时窗口是根据当前字段a的值确定的当前窗口取first或者last.
3:
- COUNT
- SUM
- MIN
- MAX
- AVG
这几个函数就是窗口内的聚集函数,没有特别之处,partition by 可以按照多个字段划分窗口
待补充:https://blog.csdn.net/qq_20641565/article/details/52841345