0 背景概述
Doris完全兼容了mysql协议,并且Doris FE本身通过多follower选举机制选举出master,可以保证fe本身的高可用性,也可以通过加入observer fe节点来提高fe的读并发能力。但是对于前端连接来讲,还是需要显示执行要连接的fe的url(jdbc)或host ip地址.通过这种方式,如果要访问的fe挂掉的话,上面的应用层就会出错。通过这种方式来访问Doris提供的服务,应用层代码是不够健壮的。Doris官方提供了几种fail over和load balance的方案,总结如下:
1. 自己在应用层代码进行重试和负载均衡。比如发现一个连接挂掉,就自动在其他连接上进行重试。应用层代码重试需要应用自己配置多个doris前端节点地址。
2. 如果使用 mysql jdbc connector 来连接Doris,可以使用 jdbc 的自动重试机制:
jdbc:mysql://[host:port],[host:port].../[database][?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]...
3. 应用可以连接到和应用部署到同一机器上的mysql proxy,通过配置mysql proxy的failover和loadbalance功能来达到目的。
对比这几种方案
1. 有点是不需要部署复杂的组件来支持,直接在应用层进行处理,缺点是将fe节点的部署情况和应用层代码进行了耦合,不利于系统的扩展。
2. 同方案1,只是将这种耦合转移到了jdbc的连接字符串上面了,而且这种方案还不通用,仅限于使用mysql jdbc jar包的方式来进行访问的Dodis的情况,对于其他的访问方式,如odbc,这种方案就不可用了。
3. 此方案个人认为是这几种方案中最好的解决方案,对上层应用处理来讲,透明化了,扩展性也比较强,缺点是必须部署更多的组件。
本文将通过构建一个haproxy+keepalived 组合的FE负载均衡集群的方式来讲方案3的具体应用。
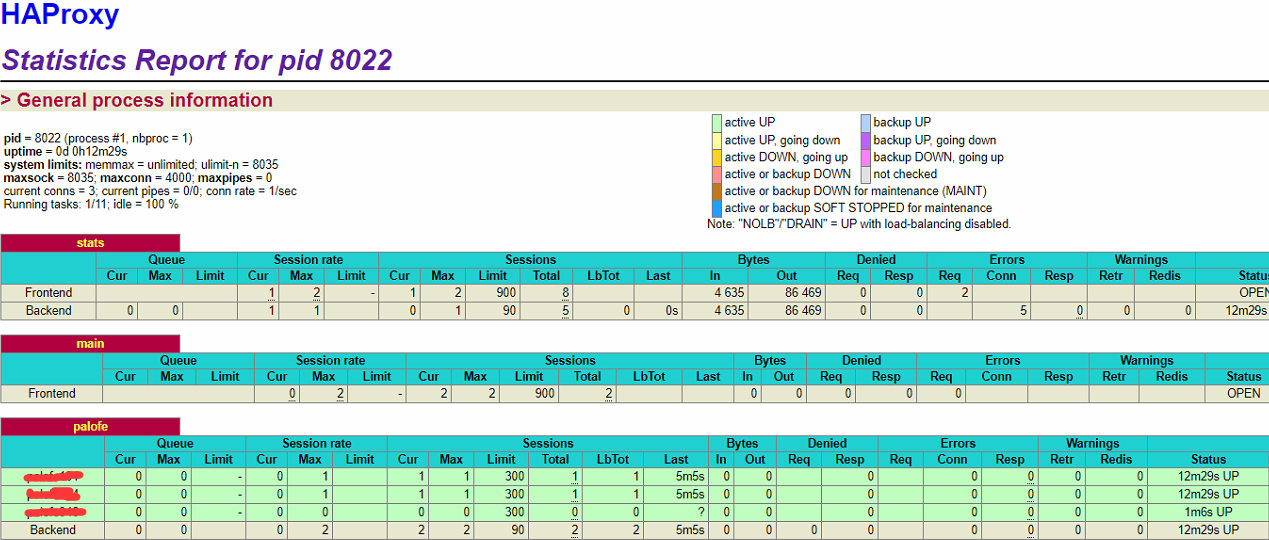
1. 集群规划:
192.168.1.101 palo101 CentOS 7.4 FE observer + BE+Haproxy 192.168.1.102 palo102 CentOS 7.4 FE observer + BE+Haproxy+KeepAlived 192.168.1.103 palo103 CentOS 7.4 FE observer + BE+Haproxy+KeepAlived 192.168.1.104 LoadBalancer VIP
说明:
a) 其中 192.168.1.101, 192.168.1.102,192.168.1.103上的Doris FE和Doris BE均已安装好,具体安装请参见Doris官方文档或者本人的前期博文,这里不再赘述。本文的范畴是构建fe的负载均衡器。
b) 192.168.1.104仅仅是一个可用的ip地址资源,没有被任何主机占用。负载均衡器在主备的时候会选举一个vip loadbalance,并在此地址上提供负载均衡服务,也就是说上层应用层代码均通过连接此地址来使用Doris提供的服务。
2. 安装HaProxy
Haproxy是一个开源的高性能的反向代理或者说是负载均衡服务软件之一,它支持双机热备、虚拟主机、基于TCP和HTTP应用代理等功能。其配置简单,而且拥有很好的对服务器节点的健康检查功能(相当于keepalived健康检查),当其代理的后端服务器出现故障时,Haproxy会自动的将该故障服务器摘除,当服务器的故障恢复后Haproxy还会自动将RS服务器。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
Haproxy软件引入了frontend,backend的功能,frontend(acl规则匹配)可以根据任意HTTP请求头做规则匹配,然后把请求定向到相关的backend(server pools等待前端把请求转过来的服务器组)。通过frontend和backup,我们可以很容易的实现haproxy的7层代理功能,haproxy是一款不可多得的优秀代理服务软件。
2.1 在192.168.1.101,192.168.1.102,192.168.1.103三台机器上分别安装haproxy
yum -y install haproxy
配置如下:
sudo vim /etc/haproxy/haproxy.cfg
输入如下内容:
global log 127.0.0.1 local2 #日志定义级别 chroot /var/lib/haproxy #当前工作目录 pidfile /var/run/haproxy.pid #进程id maxconn 4000 #最大连接数 user haproxy #运行改程序的用户 group haproxy daemon #后台形式运行 stats socket /var/lib/haproxy/stats defaults mode tcp #haproxy运行模式(http | tcp | health) log global option dontlognull option redispatch #serverId对应的服务器挂掉后,强制定向到其他健康的服务器 option tcp-smart-accept option tcp-smart-connect retries 3 #三次连接失败则服务器不用 timeout http-request 15s timeout queue 5m timeout connect 10s #连接超时 timeout client 480m #客户端超时 timeout server 480m #服务器超时 timeout http-keep-alive 10s timeout check 10s #心跳检测 maxconn 900 #最大连接数 listen stats #配置haproxy状态页(用来查看的页面) mode http bind :8888 #web前端监控页面的监听端口 stats enable stats hide-version #隐藏haproxy版本号 stats uri /haproxyadmin?stats #一会用于打开状态页的uri stats realm Haproxy Statistics #输入账户密码时的提示文字 stats auth admin:admin #用户名:密码 frontend main bind 0.0.0.0:3306 #使用3306端口。监听前端端口【表示任何ip访问3306端口都会将数据轮番转发到mysql服务器群组中】 default_backend palofe #后端服务器组名 backend palofe #balance leastconn //使用最少连接方式调度 balance roundrobin #设置默认负载均衡方式,轮询方式 server palofe161 192.168.1.101:9030 check port 9030 maxconn 300 inter 5000 fall 3 rise 3 #转发到101的9030端口,并监听9030端口,监听间隔为5秒钟,如果连续两次检测不到活跃,则从ha群组中剔除,如果连续两次成功,则恢复到群组中来 server palofe164 192.168.1.102:9030 check port 9030 maxconn 300 inter 5000 fall 3 rise 3 server palofe046 192.168.1.103:9030 check port 9030 maxconn 300 inter 5000 fall 3 rise 3
说明: Doris FE我们使用的默认端口9030,而mysql默认端口为3306,为了使mysql客户端连接负载均衡器时的使用习惯和mysql保持兼容,我们的设置haproxy的监听端口为3306.(使用mysql客户端连接时,如果不输入端口号,默认为3306)
这个体现在配置中就是:
bind 0.0.0.0:3306 #使用3306端口。监听前端端口【表示任何ip访问3306端口都会将数据轮番转发到doris fe集群群组中】
我们在haproxy的backend中进行了端口映射,把访问3306端口的请求转发到Doris FE的9030端口,采用的是轮询roundrobin 分配算法。
2.2 启动haproxy并设置开启启动
sudo systemctl start haproxy #启动 sudo systemctl enable haproxy #设置开机启动
2.3 测试haproxy
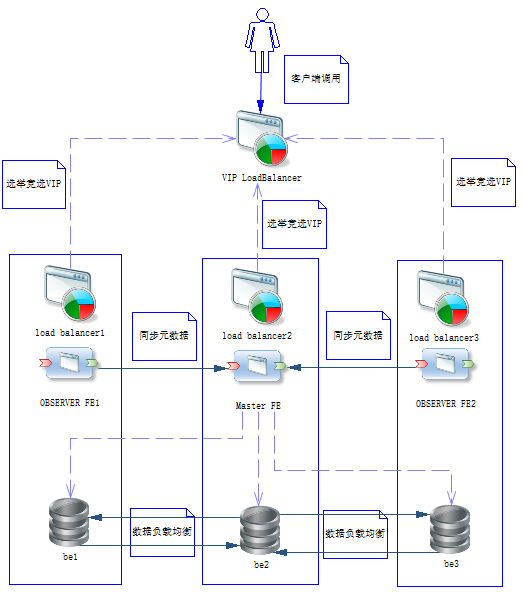
在192.168.1.101上用浏览器打开http://192.168.1.101:8888/haproxyadmin?stats,用户名密码为admin:admin(在上面haproxy.conf文件中配置的),其他机器可以更换IP地址,操作亦同。如果出现以下界面,则表明haproxy安装成功。

注:如果是要通过tar包安装的haproxy,最好创建haproxy.service(通过rpm包或者yum安装的不需要做此操作),操作如下:
sudo /usr/lib/systemd/system/haproxy.service
填写以下内容:
[Unit] Description=Process Monitoring and Control Daemon After=rc-local.service nss-user-lookup.target [Service] LimitCORE=infinity LimitNOFILE=100000 LimitNPROC=100000 Type=forking ExecStart=/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg [Install] WantedBy=multi-user.target
其中ExecStart=/usr/sbin/haproxy -f /etc/haproxy/haproxy.cfg 记得修改成自己实际的路径
3. 安装Keepalived
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
3.1. 在192.168.1.101,192.168.1.102,192.168.1.103三台机器上分别安装keepalived
sudo yum install -y keepalived
3.2 配置keepalived
sudo vim /etc/keepalived/keepalived.conf
输入如下配置信息:
#简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了; global_defs { #notificationd LVS_DEVEL router_id palo101 } #预先定义一个脚本,方便后面调用,也可以定义多个,方便选择; vrrp_script chk_haproxy { script "/etc/keepalived/chk.sh" #具体脚本路径 interval 2 #脚本循环运行间隔 timeout 2 fall 3 } #VRRP虚拟路由冗余协议配置 vrrp_instance VI_1 { #VI_1 是自定义的名称; state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】 nopreempt #开启不抢占 interface ens192 #指定VIP需要绑定的物理网卡 virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同 priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台 advert_int 1 #生存检测时的组播信息发送间隔,组内一致 authentication { #设置验证信息,组内一致 auth_type PASS #有PASS 和 AH 两种,常用 PASS auth_pass edw #密码 } virtual_ipaddress { 192.168.1.104 #指定VIP地址,组内一致,可以设置多个IP } track_script { #使用在这个域中使用预先定义的脚本,上面定义的 chk_haproxy } notify_backup "/etc/keepalived/restart_haproxy.sh" #表示当切换到backup状态时,要执行的脚本
notify_fault "/etc/keepalived/restart_haproxy.sh" #故障时执行的脚本
}
注意: 几台机器的priority要设置为不同,以便可以进行抢占工作。 在本例中101-103的priority分别设置为 110,120,130
在上述配置中用到了chk.sh文件,用于检测本机的haproxy是否alive,并在检测haproxy死亡时出发处理动作,所以我们创建chk.sh文件
sudo vim /etc/keepalived/chk.sh
输入以下内容:
#!/bin/bash # if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ]; then /usr/bin/systemctl stop keepalived fi
授权chk.sh执行权限
sudo chmod +x /etc/keepalived/chk.sh
创建文件restart_haproxy.sh
sudo vim /etc/keepalived/restart_haproxy.sh
填写内容如下:
/usr/bin/systemctl restart haproxy
授权restart_haproxy.sh执行权限
sudo chmod +x /etc/keepalived/restart_haproxy.sh
这里对haproxy活跃检测失败的处理是停止掉本机的keepalived进程,出让vip。
3.3 设置keepalived开机启动并启动keepalived
sudo systemctl enable keepalived #设置开机启动 sudo systemctl start keepalived #启动keepalived
4. 负载均衡测试
4.1 测试通过3306端口可以访问到Doris
a) 所有三台机器的haproxy,keepalived,doris fe全部开启
b) 使用mysql客户端连接192.168.1.104,并且不带参数-P 3306指定端口
mysql -h 192.168.1.104 -uroot -proot
测试效果如下:
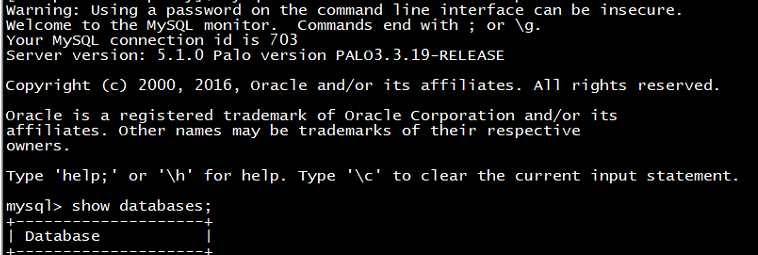
说明: 3306端口在虚拟机器上监听成功。(192.168.1.104实际上并没有安装任何实际的机器,完全由负载均衡器选举产生的访问资源,是一个虚拟的活跃vip负载均衡器)
4.2 停止掉102.168.1.102,192.168.1.103上的keepalived,并使用mysql客户端通过3306端口访问负载均衡器,连接失败
sudo systemctl stop keepalived #停止keepalived mysql -h 192.168.1.104 -uroot -proot Warning: Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.1.104' (113)
4.3 高可用测试
4.3.1 启动三台机器上的haproxy, 并启动192.168.1.102,192.168.1.103上的keepalived
首先查看三台机器的相关进程id
192.168.1.101
[edw@palo101 ~]$ ps -e | grep haproxy 9084 ? 00:00:00 haproxy-systemd 9085 ? 00:00:00 haproxy 9086 ? 00:00:04 haproxy
192.168.1.102
[edw@palo102 keepalived]$ ps -e | grep haproxy 16592 ? 00:00:00 haproxy-systemd 16593 ? 00:00:00 haproxy 16594 ? 00:00:00 haproxy [edw@palo102 keepalived]$ ps -e | grep keepalived 16580 ? 00:00:00 keepalived 16581 ? 00:00:00 keepalived 16582 ? 00:00:00 keepalived
192.168.1.103
[edw@palo103 keepalived]$ ps -e | grep haproxy 19910 ? 00:00:00 haproxy-systemd 19911 ? 00:00:00 haproxy 19912 ? 00:00:00 haproxy [edw@palo103 keepalived]$ ps -e | grep keepalived 19975 ? 00:00:00 keepalived 19976 ? 00:00:00 keepalived 19977 ? 00:00:00 keepalived
4.3.2 浏览器打开http://192.168.1.104:8888/haproxyadmin?stats
注意:我们打开的是104的url,也就是部署在102和103上的keepalived选举出的vip loadbalancer的ip地址.

目前是102获得了vip load balancer
4.3.3 在192.168.1.102上关闭haproxy
sudo kill -9 16594
刷新4.3.2中打开的浏览器页面,
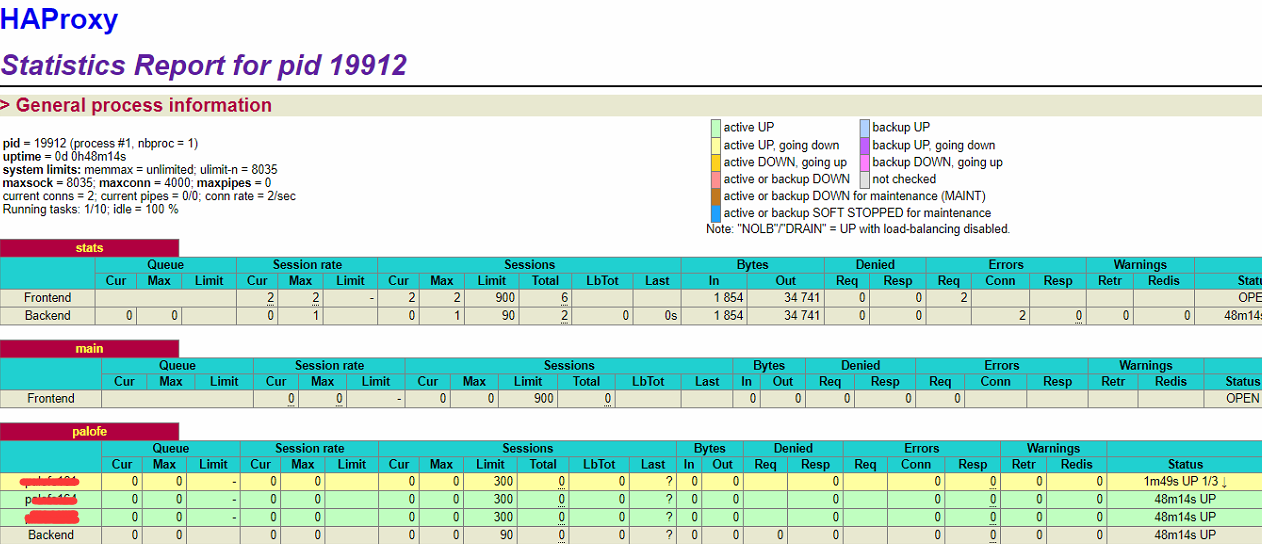
我们发现目前取得vip的地址转移到了103上,实现了高可用,一台机器上的负载均衡器挂了之后,另外一台依然可用。实现了对负载均衡器的vip主备功能。(实际上,http://192.168.1.104:8888/haproxyadmin?stats该url依然可以打开,就说明负载均衡器依然活着)
并且在三个haproxy中,发现了一台挂的,也就是图中黄色的条目,就是代表102的机器
4.3.4 在192.168.1.102上启动haproxy
[edw@palo102 keepalived]$ sudo systemctl start haproxy [edw@palo102 keepalived]$ ps -e | grep haproxy 20228 ? 00:00:00 haproxy-systemd 20229 ? 00:00:00 haproxy 20230 ? 00:00:00 haproxy
4.4.5 刷新4.3.2中打开的页面http://192.168.1.104:8888/haproxyadmin?stats
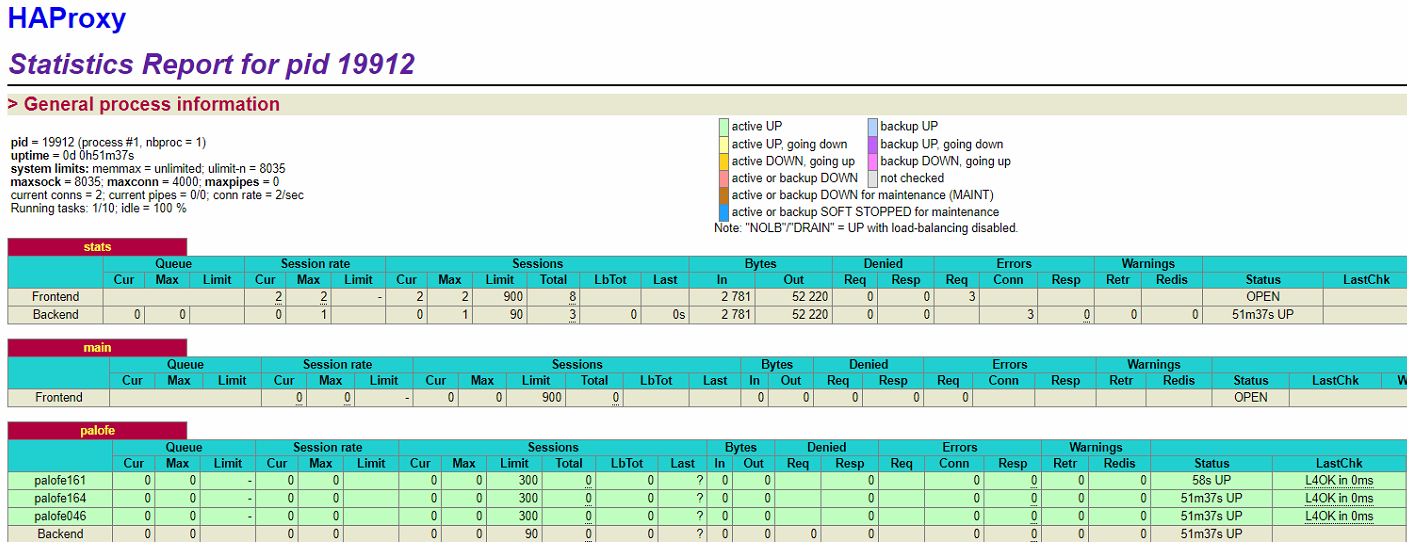
发现vip依然在103上,没有发生vip负载均衡器的更换,并且三个负载均衡器均处于活跃状态,即当vip宕机之后,vip发生转移,但是之前挂掉的vip(现在已经选举出了新的vip了)重新online后,不会发生控制权的转移。
4.4 负载测试
安装抓包工具tcpdump
sudo yum install -y tcpdump
在192.168.1.101,192.168.1.102,192.168.1.103分别启动抓包
sudo tcpdump -n -i ens192 host 192.168.1.101 and 192.168.1.104 #101机器上,注意ens192为当前机器的活跃mac网卡的名称,各个机器可能会不一样,请注意根据自己的实际情况修改 sudo tcpdump -n -i ens192 host 192.168.1.102 and 192.168.1.104 #102机器上,注意ens192为当前机器的活跃mac网卡的名称,各个机器可能会不一样,请注意根据自己的实际情况修改 sudo tcpdump -n -i ens192 host 192.168.1.103 and 192.168.1.104 #103机器上,注意ens192为当前机器的活跃mac网卡的名称,各个机器可能会不一样,请注意根据自己的实际情况修改
抓包结果:
192.168.1.101
[edw@palo101 ~]$ sudo tcpdump -n -i ens192 host 192.168.1.101 and 192.168.1.104 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
192.168.1.102
[edw@palo102 keepalived]$ sudo tcpdump -n -i ens192 host 192.168.1.102 and 192.168.1.104 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
192.168.1.103
[edw@palo103 keepalived]$ sudo tcpdump -n -i ens192 host 192.168.1.103 and 192.168.1.104 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on ens192, link-type EN10MB (Ethernet), capture size 262144 bytes
使用mysql客户端连接mysql -h 192.168.1.104 -uroot -proot 负载均衡器,并进行一些操作。由于我们采用的是roundrobin轮询算法,所以结果很明显,三台机器都抓到了请求包,说明负载均衡起作用了。
4.5 测试任意一台fe宕机,该fe会被移出haproxy群组
4.5.1 在192.168.1.101中,执行下面命令停止palo_fe
[edw@palo101 ~]$ sudo supervisorctl stop palo_fe palo_fe: stopped [edw@palo101 ~]$ sudo supervisorctl status palo_fe palo_fe STOPPED Dec 10 05:47 PM
刷新4.3.2中的页面http://192.168.1.104:8888/haproxyadmin?stats
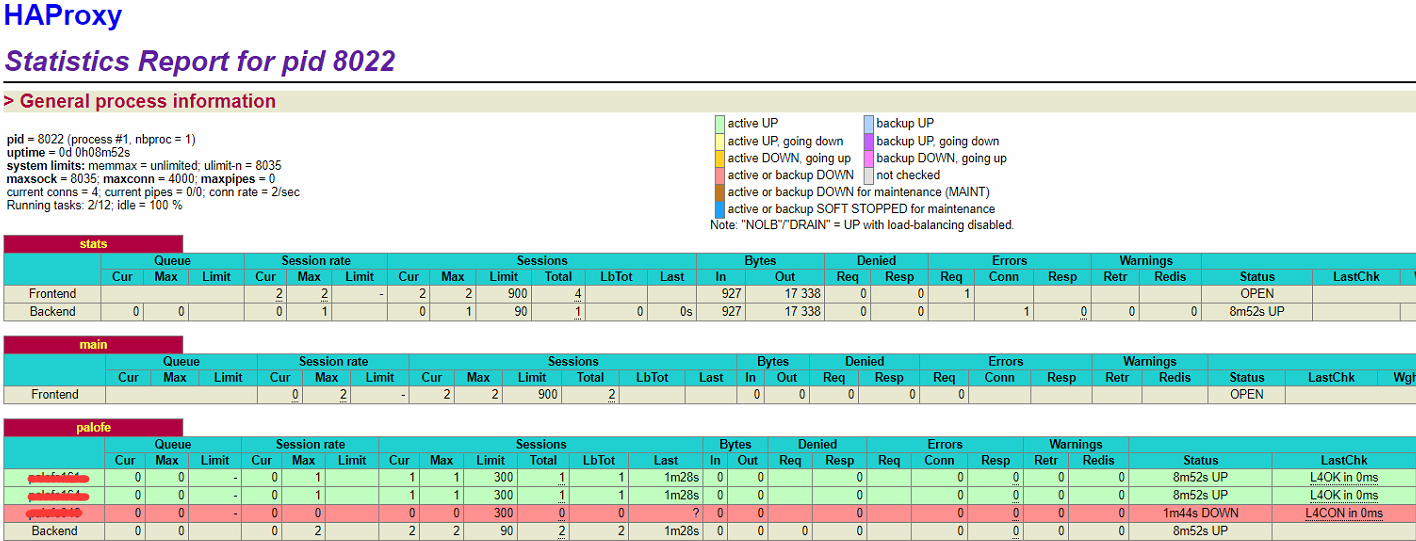
监控页面中101服务器显示为down状态,后续请求将不会转发到该节点。
4.5.2 在192.168.1.101中启动palo_fe,查看该节点的fe又重新已经被加入到服务群组中来了
[edw@palo101 ~]$ sudo supervisorctl start palo_fe palo_fe: started [edw@palo101 ~]$ sudo supervisorctl status palo_fe palo_fe RUNNING pid 31924, uptime 0:00:07