已有的介绍linux管理的文章很多,有些对内存管理的实现也讲解的非常透彻;但是多数文章对内存管理体系为什么会形成这样一个体系缺乏相应的简短介绍;或者介绍的过于繁杂,对入门者极不友好。本文试图以自己有限的理解,尽量以入门者的角度提出自己的困惑并一一解决,在解决困惑的过程中加深对内存管理的理解。
多数文章对虚拟内存映射到物理内存的实现介绍的极为详细,却在最基本的几个问题上吝惜笔墨;从我自身经历而言,刚接触到内存管理时,看到相应的文章至少有三个困惑:究竟什么是映射,什么是虚拟内存,为什么要采用虚拟内存映射这种方式;不清楚这三个问题去看内存管理的实现,很容易被复杂的处理吓到,未入门即放弃;而理解了这三个问题再去分析其实现过程,就像从土里挖到了一个鼎:你已经知道了它大概的轮廓,分析代码的过程就是用小铲和毛刷去除它周边泥土的过程,只要假以时日总能看清楚它的棱角甚至表面的纹路。
请记住一点:复杂系统设计时的出发点通常很简单。下面我们就从设计的出发点开始,先解决上述三个困惑,随后粗略认识内存管理的体系结构,后续逐步补充实现细节。
1.什么是虚拟映射;
为了对“映射”的概念有一个直观的认识,先回顾一个小故事。我们知道庆祝新中国成立的开国大典上,刚刚成立的中国空军由于飞机不够,为了达到检阅效果采取了飞两遍的策略。受检阅飞机按下图箭头所示方向依次飞过:检阅准备区,检阅可视区,检阅完成区。三个区中只有可视区能够被参加检阅的首长和群众看到;我们的目标是在可视区营造出这样一种效果:每三架飞机编成一排,连续四排飞机飞过可视区;在飞机充足的情况下达到上述检阅效果没有任何问题,只需要派出12架飞机按规定编队依次飞过检阅可视区即可。
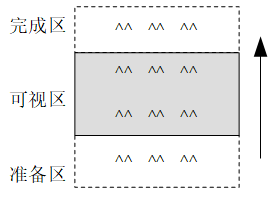
问题在于我们只有6架飞机,怎么在可视区营造出12架飞机的效果呢?可供我们利用的一个条件是可视区有限的视野(注意这个条件,下文说明局部性原理会再次提到):可视区只能看到两排飞机,这样第一排飞机飞出可视区进入完成区后立刻从旁边绕回准备区,与前方飞机保持等间距再次飞入可视区就可以在可视区营造出一排排飞机飞过的效果。对我们看到的飞过检阅区的飞机进行编号:第一排(1,2,3),第二排(4,5,6),第三排(7,8,9),第四排(10,11,12);对实际执行任务的飞机进行编号A,B,C,D,E,F。
实际执行检阅任务的过程为:A,B,C先飞进检阅区,让检阅群众看到第一排飞机(1,2,3),随后D,E,F与A,B,C保持一定间距飞进检阅区让检阅群众看到第二排飞机(4,5,6)。A,B,C飞出可视区进入完成区后迅速从周边绕回准备区,与前方的D,E,F三架飞机保持相同间距再次飞入可视区让检阅群众看到第三排飞机(7,8,9);D,E,F第一次飞出检阅区后再绕回准备区,与前方的A,B,C三架飞机保持相同间距再次飞入可视区让检阅群众看到第四排飞机(10,11,12);
实际上第三排飞机(7,8,9)和第四排飞机(10,11,12)并不存在,只是A,B,C和D,E,F第二次进入检阅区营造出的一种效果;按这个思路严格来说第一排飞机(1,2,3)和第二排飞机(4,5,6)也不存在,只是A,B,C和D,E,F第一次进入检阅区营造出的一种效果。
我们看到的检阅效果,飞过检阅区的编号为1,2,3...12的飞机是虚拟飞机,实际执行任务的A,B,C,D,E,F是物理飞机;1,2,3...12与A,B,C,D,E,F的对应关系就是映射。如下图所示:
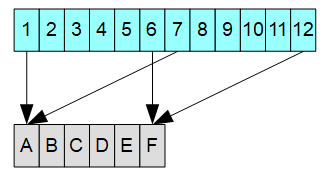
为什么需要映射:原因显而易见:飞机不够!我们的核心目标是达到四排12架飞机飞过检阅区的效果,而不关心具体用几架飞机达到检阅效果。需要1,2,3飞过天空就让A,B,C去充当1,2,3; 需要4,5,6就让D,E,F去充当4,5,6; 需要需要7,8,9就再让A,B,C去充当7,8,9;
为什么可行:上文提到可供我们利用的一个条件是可视区有限的视野,实际就是局部性原理:要达到检阅效果需要的12架虚拟飞机中,我们每次只需要6架连续编号的虚拟飞机;1,2,3和7,8,9不会同时出现在检阅区,这样就可以A,B,C在不同时间分别充当1,2,3或者7,8,9(即物理飞机A,B,C映射到虚拟飞机1,2,3或7,8,9)。
现在让我们回归内存管理探究一下它之所以采用这样一套机制的原因;先考虑一个问题:假如CPU是大脑,那内存是什么?以我个人的理解,内存只是大脑执行运算的草稿纸。我们先看下代码示例:
#tmp.c
int sum(int a, int b) { return a + b; } int global_c = 0x1234; void main() { int a = 3; int b = 4; global_c = sum(a, b); }
利用gcc tmp.c对上述文件进行编译可得到二进制可执行文件a.out, 再执行命令“objdump -SD a.out >tmp_dump”可得到二进制可执行文件对应的汇编代码。
#tmp_dump
00000000000005fa <sum>: 5fa: 55 push %rbp //栈底入栈 5fb: 48 89 e5 mov %rsp,%rbp //重新准备栈区,将调用前的栈顶作为新函数的栈底 5fe: 89 7d fc mov %edi,-0x4(%rbp) // 601: 89 75 f8 mov %esi,-0x8(%rbp) 604: 8b 55 fc mov -0x4(%rbp),%edx 607: 8b 45 f8 mov -0x8(%rbp),%eax 60a: 01 d0 add %edx,%eax 60c: 5d pop %rbp //栈底出栈,恢复main函数的栈 60d: c3 retq //返回到调用函数的下条指令地址,0x633处 000000000000060e <main>: 60e: 55 push %rbp 60f: 48 89 e5 mov %rsp,%rbp 612: 48 83 ec 10 sub $0x10,%rsp 616: c7 45 f8 03 00 00 00 movl $0x3,-0x8(%rbp) //常量3写入变量a 61d: c7 45 fc 04 00 00 00 movl $0x4,-0x4(%rbp) //常量4写入变量b 624: 8b 55 fc mov -0x4(%rbp),%edx //变量b的值(4)写入edx寄存器 627: 8b 45 f8 mov -0x8(%rbp),%eax //变量a的值(3)写入edx寄存器 62a: 89 d6 mov %edx,%esi //edx 寄存器的值(4)写入esi寄存器 62c: 89 c7 mov %eax,%edi //eax 寄存器的值(3)写入edi寄存器 62e: e8 c7 ff ff ff callq 5fa <sum> //跳转到0x5fa调用sum函数 633: 89 05 d7 09 20 00 mov %eax,0x2009d7(%rip)//将求和的结果写入0x201010,
//rip指向下条指令地址0x639,
//偏移0x2009d7刚好为0x201010,
//也就是存放全局变量global_c的地址
//即将求和结果写入变量global_c 639: 90 nop 63a: c9 leaveq 63b: c3 retq 63c: 0f 1f 40 00 nopl 0x0(%rax) ... 0000000000201010 <global_c>: 201010: 34 12 xor $0x12,%al //global_c为int类型,使用四字节保存, ... //从0x201010开始的四个字节分别保存0x34 0x12 0x00 0x00;
//由于X86采用小端字节序,因此global_c的值为0x1234
可执行二进制文件实际是保存在磁盘中的内存的映像,以sum函数为例,最左边的"5fa"是指令地址,中间列"55"是机器码,最右列"push %rbp"是机器码对应的汇编代码。运行二进制程序前需要先将二进制程序载入到内存中,CPU执行代码的过程就是从内存这个草稿纸中顺序读取并执行机器码的过程。如果物理内存足够大,可以直接按物理地址等于指令地址的方式将二进制映像载入物理内存,然后从0x60e(main函数起始)处逐条执行指令即可。
但是现实存在的几个问题使得我们无法采取直接按地址对齐载入物理内存的方式:
1.二进制文件的大小可能超过物理内存大小,无法全部装载到物理内存中。
2.多个程序并行执行的需要,假如两个程序的main函数都需要加载到0x60e处,就无法同时执行这两个程序;
3.安全性需求,要限定用户进程可以访问的内存,阻止其访问一些系统级程序需要的内存以免造成系统崩溃;
我们将要执行的程序类比为一个步骤很多的数学方程求解,每条指令类比为一个步骤;求解方程需要用到1,2,3,4,5,6页草稿纸,但是我们只有可擦写的A,B两页草稿纸;需要第1页草稿纸时,拿A来用,需要第2页草稿纸时拿B来用,需要第3页草稿时把A擦干净后再拿来用,直到将所有的步骤算完,求解出最终结果。
二进制程序的执行过程与上述数学计算过程基本一致,A,B两页草稿纸对应我们的物理内存,即我们买来的插在内存插槽上的实体;1,2,3,4,5,6页草稿纸对应我们为装载程序准备的虚拟空间。比如我们要执行sum函数对应的代码时,就从物理内存中申请一块空间A(假定申请了物理地址为0x10000--0x11000的这块空间),将指令地址0x5fa--0x60d间的代码段装载到空间A。执行指令地址0x5fa处的指令实际就是执行物理内存0x10000处的指令,执行指令地址(0x5fa + i)处的指令实际就是执行物理内存(0x10000 + i)处的指令,这样就完成了物理内存地址(0x10000 + i)向指令地址也就是虚拟地址(0x5fa + i)的映射。
现在我们看下上面提到的几个问题是怎样解决的:
1.二进制文件的大小可能超过物理内存大小,无法全部装载到物理内存中。
就像我们进行数学计算不会同时需要6张草稿纸一样,我们也不需要把整个的二进制文件全部加载进物理内存;仍然以上述例子进行说明,我们要执行sum函数对应的代码时,就从物理内存中申请一块空间A(假定申请了物理地址为0x10000--0x11000的这块空间),将指令地址0x5fa--0x60d间的代码段装载到空间A,实现完成了物理内存地址(0x10000 + i)向指令地址也就是虚拟地址(0x5fa + i)的映射。假定我们还有一个求最大数的max函数(指令地址为0x6fa--0x70d),执行完求和的sum函数后,空间A已经利用完毕,可以再次将指令地址0x6fa--0x70d间的代码段装载到空间A,实现完成了物理内存地址(0x10000 + i)向指令地址也就是虚拟地址(0x6fa + i)的映射。
2.多个程序并行执行的需要,假如两个程序CODE_A和CODE_B的main函数都需要加载到0x60e处,就无法同时执行这两个程序;使用虚拟内存机制就可以将CODE_A和CODE_B的main函数分别加载到(0x10000--0x11000)和(0x12000--0x13000)这两块物理空间,CPU从这两块空间逐条取指令执行就可以完成多个程序的并发运行。
3.安全性需求,要限定用户进程可以访问的内存,阻止其访问一些系统级程序需要的内存以免造成系统崩溃;系统使用的物理内存进行保留,只把特定的物理内存用来装载二进制文件,同时限定代码可访问的地址范围。
映射原理大概如此,实现细节后续补充。