问题起因
最近要将一个文本分割成好几个topic,每个topic设计一个regressor,各regressor是相互独立的,最后汇总所有topic的regressor得到总得预测结果。没错!类似bagging ensemble!只是我没有抽样。文本不大,大概3000行,topic个数为8,于是我写了一个串行的程序,一个topic算完之后再算另一个topic。可是我在每个topic中用了GridSearchCV来调参,又要选特征又要调整regressor的参数,导致参数组合一共有1782种。我真是低估了调参的时间,程序跑了一天一夜最后因为忘记import一个库导致最终的预测精度没有算出来。后来想到,既然每个topic的预测都是独立的,那是不是可以并行呢?
Python中的多线程与多进程
但是听闻Python的多线程实际上并不能真正利用多核,所以如果使用多线程实际上还是在一个核上做并发处理。不过,如果使用多进程就可以真正利用多核,因为各进程之间是相互独立的,不共享资源,可以在不同的核上执行不同的进程,达到并行的效果。同时在我的问题中,各topic相互独立,不涉及进程间的通信,只需最后汇总结果,因此使用多进程是个不错的选择。
multiprocessing
一个子进程
multiprocessing模块提供process类实现新建进程。下述代码是新建一个子进程。
from multiprocessing import Process def f(name): print 'hello', name if __name__ == '__main__': p = Process(target=f, args=('bob',)) # 新建一个子进程p,目标函数是f,args是函数f的参数列表 p.start() # 开始执行进程 p.join() # 等待子进程结束
上述代码中p.join()的意思是等待子进程结束后才执行后续的操作,一般用于进程间通信。例如有一个读进程pw和一个写进程pr,在调用pw之前需要先写pr.join(),表示等待写进程结束之后才开始执行读进程。
创建多个子进程
import multiprocessing def worker(num): """thread worker function""" print 'Worker:', num return if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker, args=(i,)) jobs.append(p) p.start()
确定当前的进程,即是给进程命名,方便标识区分,跟踪
import multiprocessing import time def worker(): name = multiprocessing.current_process().name print name, 'Starting' time.sleep(2) print name, 'Exiting' def my_service(): name = multiprocessing.current_process().name print name, 'Starting' time.sleep(3) print name, 'Exiting' if __name__ == '__main__': service = multiprocessing.Process(name='my_service', target=my_service) worker_1 = multiprocessing.Process(name='worker 1', target=worker) worker_2 = multiprocessing.Process(target=worker) # default name worker_1.start() worker_2.start() service.start()
守护进程
守护进程就是不阻挡主程序退出,自己干自己的 mutilprocess.setDaemon(True)
就这句
等待守护进程退出,要加上join,join可以传入浮点数值,等待n久就不等了
import multiprocessing import time import sys def daemon(): name = multiprocessing.current_process().name print 'Starting:', name time.sleep(2) print 'Exiting :', name def non_daemon(): name = multiprocessing.current_process().name print 'Starting:', name print 'Exiting :', name if __name__ == '__main__': d = multiprocessing.Process(name='daemon', target=daemon) d.daemon = True n = multiprocessing.Process(name='non-daemon', target=non_daemon) n.daemon = False d.start() n.start() d.join(1) print 'd.is_alive()', d.is_alive() n.join()
终止进程
最好使用 poison pill,强制的使用terminate()
注意 terminate之后要join,使其可以更新状态
import multiprocessing import time def slow_worker(): print 'Starting worker' time.sleep(0.1) print 'Finished worker' if __name__ == '__main__': p = multiprocessing.Process(target=slow_worker) print 'BEFORE:', p, p.is_alive() p.start() print 'DURING:', p, p.is_alive() time.sleep(0.2) #模拟子进程没运行完就退出 p.terminate() print 'TERMINATED:', p, p.is_alive() p.join() print 'JOINED:', p, p.is_alive()
进程的退出状态
- == 0 未生成任何错误
-
0 进程有一个错误,并以该错误码退出
- < 0 进程由一个-1 * exitcode信号结束
import multiprocessing import sys import time def exit_error(): sys.exit(1) def exit_ok(): return def return_value(): return 1 def raises(): raise RuntimeError('There was an error!') def terminated(): time.sleep(3) if __name__ == '__main__': jobs = [] for f in [exit_error, exit_ok, return_value, raises, terminated]: print 'Starting process for', f.func_name j = multiprocessing.Process(target=f, name=f.func_name) jobs.append(j) j.start() jobs[-1].terminate() for j in jobs: j.join() print '%15s.exitcode = %s' % (j.name, j.exitcode)
日志
方便的调试,可以用logging
import multiprocessing import logging import sys def worker(): print 'Doing some work' sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr() logger = multiprocessing.get_logger() logger.setLevel(logging.INFO) p = multiprocessing.Process(target=worker) p.start() p.join()
派生进程
利用class来创建进程,定制子类
import multiprocessing class Worker(multiprocessing.Process): def run(self): print 'In %s' % self.name return if __name__ == '__main__': jobs = [] for i in range(5): p = Worker() jobs.append(p) p.start() for j in jobs: j.join()
多个子进程
如果要同时创建多个子进程可以使用multiprocessing.Pool类。该类可以创建一个进程池,然后在多个核上执行这些进程。
import multiprocessing import time def func(msg): print multiprocessing.current_process().name + '-' + msg if __name__ == "__main__": pool = multiprocessing.Pool(processes=4) # 创建4个进程 for i in xrange(10): msg = "hello %d" %(i) pool.apply_async(func, (msg, )) pool.close() # 关闭进程池,表示不能在往进程池中添加进程 pool.join() # 等待进程池中的所有进程执行完毕,必须在close()之后调用 print "Sub-process(es) done."
输出结果如下:
Sub-process(es) done.
PoolWorker-34-hello 1
PoolWorker-33-hello 0
PoolWorker-35-hello 2
PoolWorker-36-hello 3
PoolWorker-34-hello 7
PoolWorker-33-hello 4
PoolWorker-35-hello 5
PoolWorker-36-hello 6
PoolWorker-33-hello 8
PoolWorker-36-hello 9
上述代码中的pool.apply_async()是apply()函数的变体,apply_async()是apply()的并行版本,apply()是apply_async()的阻塞版本,使用apply()主进程会被阻塞直到函数执行结束,所以说是阻塞版本。apply()既是Pool的方法,也是Python内置的函数,两者等价。可以看到输出结果并不是按照代码for循环中的顺序输出的。
多个子进程并返回值
apply_async()本身就可以返回被进程调用的函数的返回值。上一个创建多个子进程的代码中,如果在函数func中返回一个值,那么pool.apply_async(func, (msg, ))的结果就是返回pool中所有进程的值的对象(注意是对象,不是值本身)。
import multiprocessing import time def func(msg): return multiprocessing.current_process().name + '-' + msg if __name__ == "__main__": pool = multiprocessing.Pool(processes=4) # 创建4个进程 results = [] for i in xrange(10): msg = "hello %d" %(i) results.append(pool.apply_async(func, (msg, ))) pool.close() # 关闭进程池,表示不能再往进程池中添加进程,需要在join之前调用 pool.join() # 等待进程池中的所有进程执行完毕 print ("Sub-process(es) done.") for res in results: print (res.get())
上述代码输出结果如下:
Sub-process(es) done.
PoolWorker-37-hello 0
PoolWorker-38-hello 1
PoolWorker-39-hello 2
PoolWorker-40-hello 3
PoolWorker-37-hello 4
PoolWorker-38-hello 5
PoolWorker-39-hello 6
PoolWorker-37-hello 7
PoolWorker-40-hello 8
PoolWorker-38-hello 9
与之前的输出不同,这次的输出是有序的。
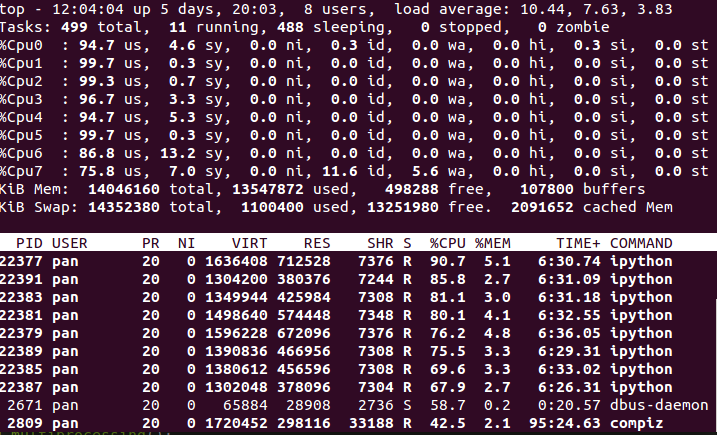
如果电脑是八核,建立8个进程,在Ubuntu下输入top命令再按下大键盘的1,可以看到每个CPU的使用率是比较平均的,如下图:
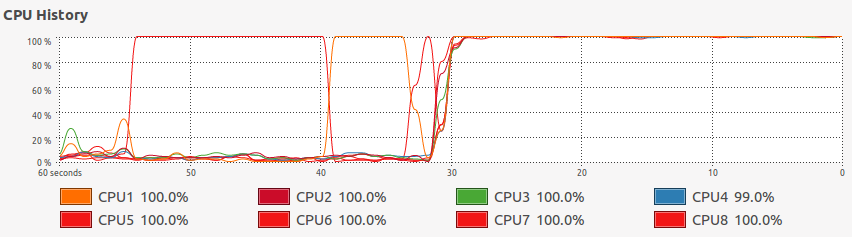
在system monitor中也可以清楚看到执行多进程前后CPU使用率曲线的差异。
子进程执行完毕执行回调函数
#coding=utf-8 import os import signal import traceback import multiprocessing def work(i): try: print('child success') 1/0 except Exception,e: print traceback.print_exc() def cb(e): # print e print '子进程执行成功,会主动调用回调函数,子进程失败,不添加异常处理不会调用回调函数' def main(): pool = multiprocessing.Pool(processes=10) for i in range(0, 2): pool.apply_async(work, (i,), callback=cb) pool.close() pool.join() print('success') if __name__ == '__main__': main()
python进程间传递消息
这一块我之前结合SocketServer写过一点,见Python多进程
一般的情况是Queue来传递。
import multiprocessing class MyFancyClass(object): def __init__(self, name): self.name = name def do_something(self): proc_name = multiprocessing.current_process().name print 'Doing something fancy in %s for %s!' % (proc_name, self.name) def worker(q): obj = q.get() obj.do_something() if __name__ == '__main__': queue = multiprocessing.Queue() p = multiprocessing.Process(target=worker, args=(queue,)) p.start() queue.put(MyFancyClass('Fancy Dan')) # Wait for the worker to finish queue.close() queue.join_thread() p.join() import multiprocessing import time class Consumer(multiprocessing.Process): def __init__(self, task_queue, result_queue): multiprocessing.Process.__init__(self) self.task_queue = task_queue self.result_queue = result_queue def run(self): proc_name = self.name while True: next_task = self.task_queue.get() if next_task is None: # Poison pill means shutdown print '%s: Exiting' % proc_name self.task_queue.task_done() break print '%s: %s' % (proc_name, next_task) answer = next_task() self.task_queue.task_done() self.result_queue.put(answer) return class Task(object): def __init__(self, a, b): self.a = a self.b = b def __call__(self): time.sleep(0.1) # pretend to take some time to do the work return '%s * %s = %s' % (self.a, self.b, self.a * self.b) def __str__(self): return '%s * %s' % (self.a, self.b) if __name__ == '__main__': # Establish communication queues tasks = multiprocessing.JoinableQueue() results = multiprocessing.Queue() # Start consumers num_consumers = multiprocessing.cpu_count() * 2 print 'Creating %d consumers' % num_consumers consumers = [ Consumer(tasks, results) for i in xrange(num_consumers) ] for w in consumers: w.start() # Enqueue jobs num_jobs = 10 for i in xrange(num_jobs): tasks.put(Task(i, i)) # Add a poison pill for each consumer for i in xrange(num_consumers): tasks.put(None) # Wait for all of the tasks to finish tasks.join() # Start printing results while num_jobs: result = results.get() print 'Result:', result num_jobs -= 1
进程间信号传递
Event提供一种简单的方法,可以在进程间传递状态信息。事件可以切换设置和未设置状态。通过使用一个可选的超时值,时间对象的用户可以等待其状态从未设置变为设置。
import multiprocessing import time def wait_for_event(e): """Wait for the event to be set before doing anything""" print 'wait_for_event: starting' e.wait() print 'wait_for_event: e.is_set()->', e.is_set() def wait_for_event_timeout(e, t): """Wait t seconds and then timeout""" print 'wait_for_event_timeout: starting' e.wait(t) print 'wait_for_event_timeout: e.is_set()->', e.is_set() if __name__ == '__main__': e = multiprocessing.Event() w1 = multiprocessing.Process(name='block', target=wait_for_event, args=(e,)) w1.start() w2 = multiprocessing.Process(name='nonblock', target=wait_for_event_timeout, args=(e, 2)) w2.start() print 'main: waiting before calling Event.set()' time.sleep(3) e.set() print 'main: event is set'
http://outofmemory.cn/code-snippet/2267/Python-duojincheng-multiprocessing-usage-example
https://blog.csdn.net/jinping_shi/article/details/52433867
https://segmentfault.com/q/1010000017216079
python进程池Pool的apply与apply_async到底怎么用?
背景
最近在解决问题的时候遇到了上下文冲突的问题,不得不用多进程来解决这个问题。这个问题是StackOverflow没有完整答案的问题,下一篇博客进行介绍。
多进程
python中使用multiprocessing模块实现多进程。multiprocessing模块提供了一个Process类来代表一个进程对象,这个模块表示像线程一样管理进程,是multiprocessing的核心,它与threading很相似,对多核CPU的利用率会比threading好的多。
Pool类
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
Signature: Pool(processes=None, initializer=None, initargs=(), maxtasksperchild=None)
Docstring: Returns a process pool object
File: /usr/lib/python3.5/multiprocessing/context.py
Type: method
Pool 中提供了如下几个方法:
apply()
apply_async()
map()
map_async()
close()
terminal()
join()
这里主要说一下apply和apply_async两个,其他的内容可以进行百度搜索
apply
Signature: pool.apply(func, args=(), kwds={})
Docstring: Equivalent of `func(*args, **kwds)`.
File: /usr/lib/python3.5/multiprocessing/pool.py
Type: method
apply函数主要用于传递不定参数,主进程会被阻塞到函数执行结束。也就是说只有apply里面的内容被执行完了,才会进行执行主函数的内容。
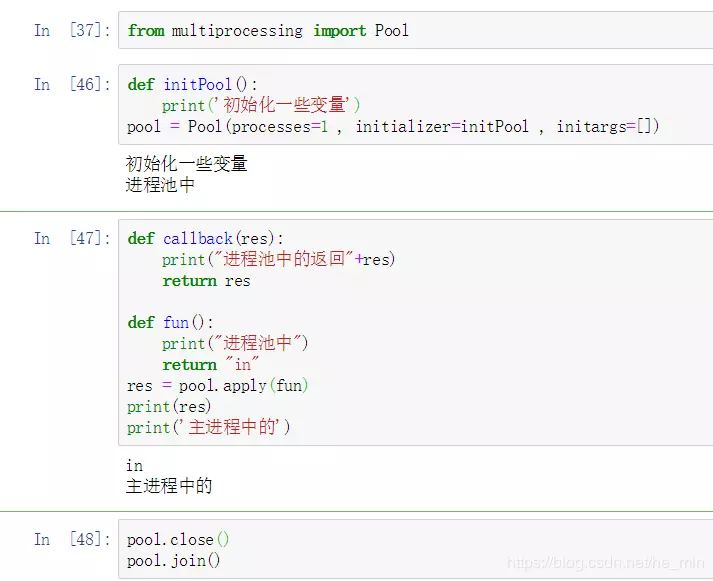
apply_async
Signature: pool.apply_async(func, args=(), kwds={}, callback=None, error_callback=None)
Docstring: Asynchronous version of `apply()` method.
File: /usr/lib/python3.5/multiprocessing/pool.py
Type: method
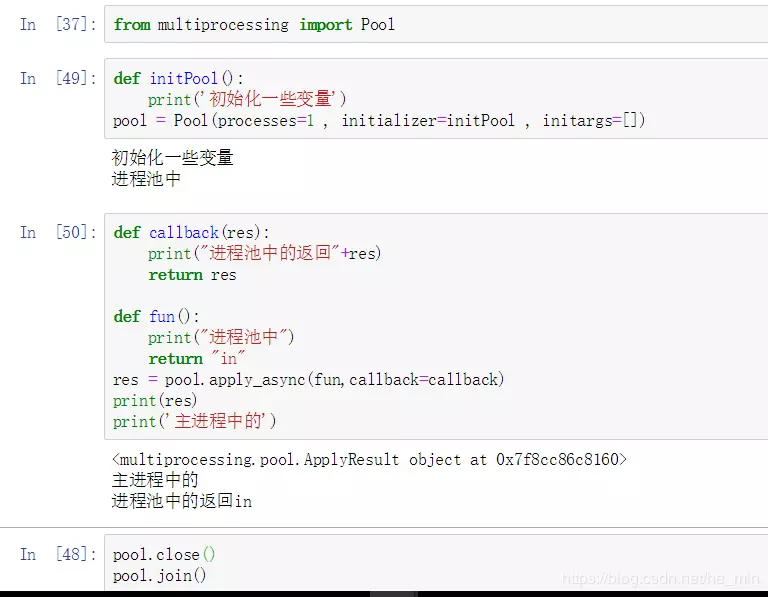
Python 多进程默认不能共享全局变量
主进程与子进程是并发执行的,进程之间默认是不能共享全局变量的(子进程不能改变主进程中全局变量的值)。如果要共享全局变量需要用(multiprocessing.Value("d",10.0),数值)(multiprocessing.Array("i",[1,2,3,4,5]),数组)(multiprocessing.Manager().dict(),字典)(multiprocessing.Manager().list(range(5)))。进程通信(进程之间传递数据)用进程队列(multiprocessing.Queue(),单向通信),管道( multiprocessing.Pipe() ,双向通信)。

import multiprocessing import time import os datalist=['+++'] #全局变量,主进程与子进程是并发执行的,他们不能共享全局变量(子进程不能改变主进程中全局变量的值) def adddata(): global datalist datalist.append(1) datalist.append(2) datalist.append(3) print("子进程",os.getpid(),datalist) if __name__=="__main__": p=multiprocessing.Process(target=adddata,args=()) p.start() p.join() datalist.append("a") datalist.append("b") datalist.append("c") print("主进程",os.getpid(),datalist)
进程之间共享数据(数值型):
import multiprocessing def func(num): num.value=10.78 #子进程改变数值的值,主进程跟着改变 if __name__=="__main__": num=multiprocessing.Value("d",10.0) # d表示数值,主进程与子进程共享这个value。(主进程与子进程都是用的同一个value) print(num.value) p=multiprocessing.Process(target=func,args=(num,)) p.start() p.join() print(num.value)
进程之间共享数据(数组型):
import multiprocessing def func(num): num[2]=9999 #子进程改变数组,主进程跟着改变 if __name__=="__main__": num=multiprocessing.Array("i",[1,2,3,4,5]) #主进程与子进程共享这个数组 print(num[:]) p=multiprocessing.Process(target=func,args=(num,)) p.start() p.join() print(num[:])
进程之间共享数据(dict,list):
import multiprocessing def func(mydict,mylist): mydict["index1"]="aaaaaa" #子进程改变dict,主进程跟着改变 mydict["index2"]="bbbbbb" mylist.append(11) #子进程改变List,主进程跟着改变 mylist.append(22) mylist.append(33) if __name__=="__main__": with multiprocessing.Manager() as MG: #重命名 mydict=multiprocessing.Manager().dict() #主进程与子进程共享这个字典 mylist=multiprocessing.Manager().list(range(5)) #主进程与子进程共享这个List p=multiprocessing.Process(target=func,args=(mydict,mylist)) p.start() p.join() print(mylist) print(mydict)