Splash是什么:
Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT。Twisted(QT)用来让服务具有异步处理能力,以发挥webkit的并发能力。
为什么要有Splash:
为了更加有效的制作网页爬虫,由于目前很多的网页通过javascript模式进行交互,简单的爬取网页模式无法胜任javascript页面的生成和ajax网页的爬取,同时通过分析连接请求的方式来落实局部连接数据请求,相对比较复杂,尤其是对带有特定时间戳算法的页面,分析难度较大,效率不高。而通过调用浏览器模拟页面动作模式,需要使用浏览器,无法实现异步和大规模爬取需求。鉴于上述理由Splash也就有了用武之地。一个页面渲染服务器,返回渲染后的页面,便于爬取,便于规模应用。
安装条件:
操作系统要求:
Docker for Windows requires Windows 10 Pro or Enterprise version 10586, or Windows server 2016 RTM to run
安装:
首先点击下面链接,从docker官网上下载windows下的docker进行安装,不过请注意系统要求是**windows1064位 pro及以上版本或者教育版
官网下载:https://store.docker.com/editions/community/docker-ce-desktop-windows
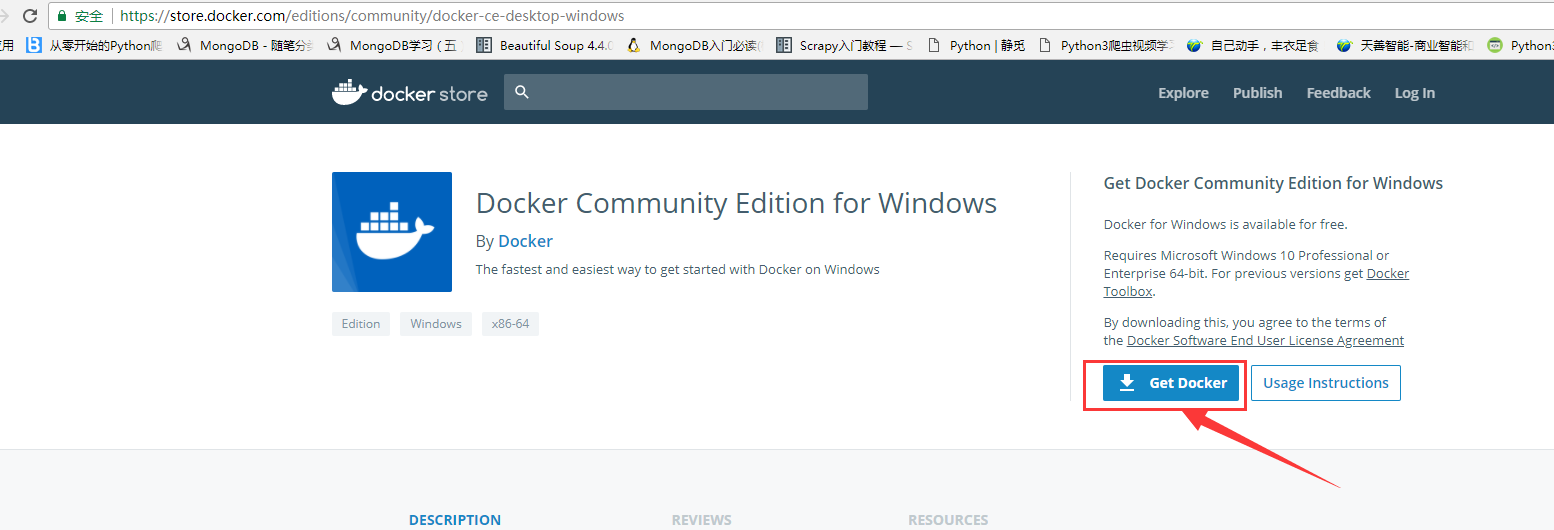
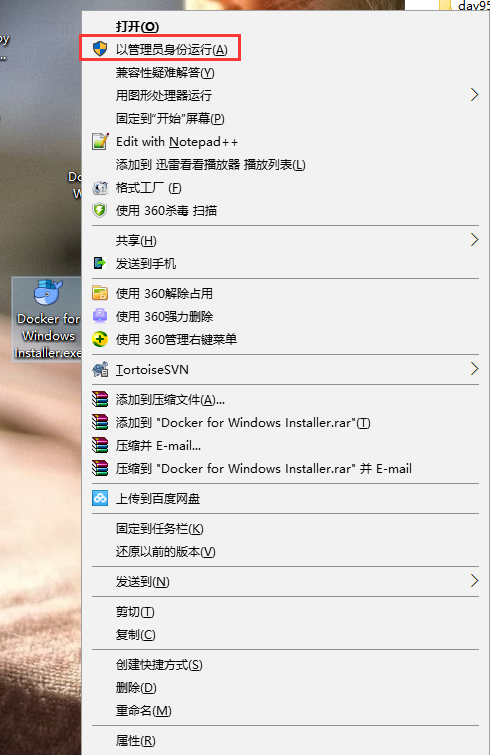
安装包下载完成后以管理员身份运行。
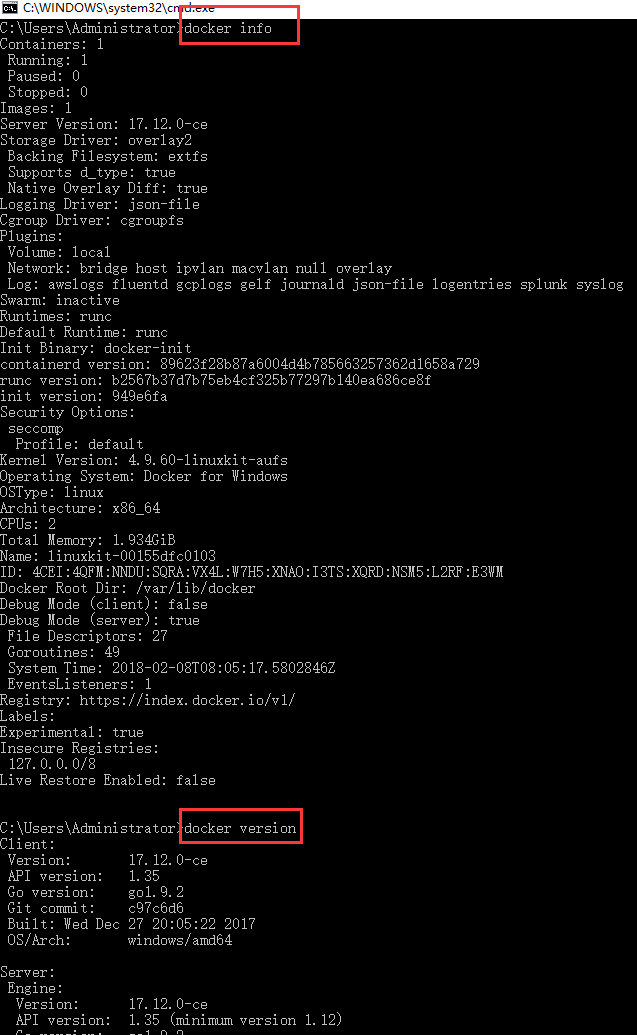
查看信息:
#docker info
#docker version
查看启动的容器

在docker中下载安装Splash镜像,并安装
#docker pull scrapinghub/splash
启动splash服务
#启动splash服务,并通过http,https,telnet提供服务 #通常一般使用http模式 ,可以只启动一个8050就好 #Splash 将运行在 0.0.0.0 at ports 8050 (http), 8051 (https) and 5023 (telnet). docker run -p 5023:5023 -p 8050:8050 -p 8051:8051 scrapinghub/splash
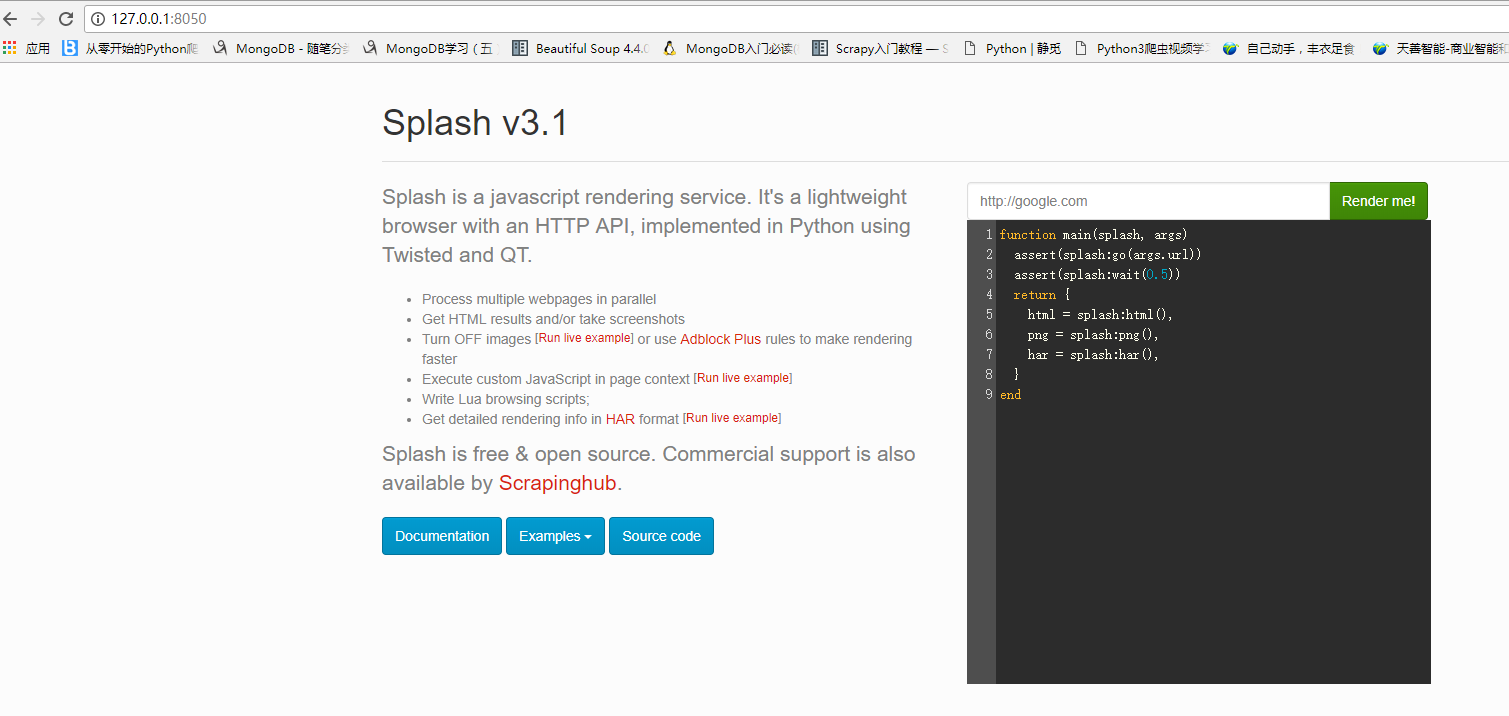
参考链接:https://www.jianshu.com/p/4052926bc12c
Centos7安装:
准备工作
删除原来的docker包,一般情况下不用,保险起见,最好按流程走一下
$ sudo yum -y remove docker docker-common container-selinux删除docker的selinux 同上
$ sudo yum -y remove docker-selinux开始安装了
使用yum 安装yum-utils
$ sudo yum install -y yum-utils增加docker源
$ sudo yum-config-manager
--add-repo
https://download.docker.com/linux/centos/docker-ce.repo查看docker源是否可用
$ sudo yum-config-manager --enable docker-ce-edge
enable 为True就行创建缓存
$ sudo yum makecache fast使用yum安装
docker现在分为两个版本 EE(企业版) CE(社区版),这里我们选择CE版.
$ sudo yum install docker-ce启动docker
$ sudo systemctl start docker启动一个helloword
$ sudo docker run hello-world这条命令会下载一个测试镜像,并启动一个容器,输出hello world 并退出,如果正常说明docker安装成功.
参考地址:https://www.cnblogs.com/colder219/p/6679255.html
使用
1、配置splash服务(以下操作全部在settings.py):
1)添加splash服务器地址:
SPLASH_URL = 'http://localhost:8050'
2)将splash middleware添加到DOWNLOADER_MIDDLEWARE中:
DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810, }
3)Enable SplashDeduplicateArgsMiddleware:
SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100, }
4)Set a custom DUPEFILTER_CLASS:
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
5)a custom cache storage backend:
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
案例:
import scrapy from scrapy_splash import SplashRequest class TbtaobaoSpider(scrapy.Spider): name = "tbtaobao" allowed_domains = ["www.taobao.com"] start_urls = ['https://s.taobao.com/search?q=坚果&s=880&sort=sale-desc'] def start_requests(self): for url in self.start_urls: # yield Request(url,dont_filter=True) yield SplashRequest(url, self.parse, args={'wait': 0.5}) def parse(self, response): print(response.text)