利用Linux命令进行文本按行去重并按重复次数排序
linux命令行提供了非常强大的文本处理功能,组合利用linux命令能实现好多强大的功能。本文这里举例说明如何利用Linux命令行进行文本按行去重并按重复次数排序。主要用到的命令有sort,uniq。其中,sort主要功能是排序,uniq主要功能是实现相邻文本行的去重。
用于演示的测试文件内容如下:
Hello World.
Apple and Nokia.
Hello World.
I wanna buy an Apple device.
The Iphone of Apple company.
Hello World.
The Iphone of Apple company.
My name is Friendfish.
Hello World.
Apple and Nokia.
1、文本去重
(1)排序
由于uniq命令只能对相邻行进行去重复操作,所以在进行去重前,先要对文本行进行排序,使重复行集中到一起。
排序前:
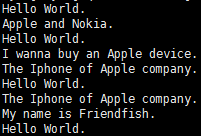
排序后:

(2)去掉相邻的重复行
如图所示:
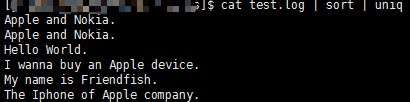
2、文本行去重并按重复次数排序
(1)首先,对文本行进行去重并统计重复次数(uniq命令加-c选项可以实现对重复次数进行统计)
如图所示:
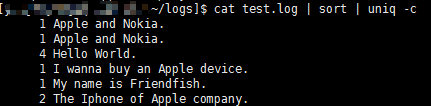
(2)按重复次数排序
sort -n可以识别每行开头的数字,并按其大小对文本行进行排序。默认是按升序排列,如果想要按降序要加-r选项(sort -rn)

-------------------------------------------------------手动分割---------------------------------------------------------
2018/09/04
做数据统计的时候遇见一个问题,对一个包含地区名的地区文件做处理的时候(cat diqu.log | sort | uniq -c),发现相邻的地区名
并没有去重,反复试了好几次也没有解决
注意:uniq 命令读取文本文件或者标准输入,并比较相邻的行。正常情况下,相邻的重复行将被删去
最后查了一下,怀疑应该是编码的问题,最后找到了解决方案:
修改系统配置
vi /etc/sysconfig/i18n #把原配置 LANG="en_US.UTF-8" #修改为 LANG="zh_CN.GB18030"
做以上修改就能解决问题
-------------------------------------------------------手动分割---------------------------------------------------------
2019/09/18
对于一些文件,我们在去重排序后会有空行存在的问题,比如:

可以看到去重之后的文件是存在空行,可以执行如下命令去除空行:
grep -v '^$' file
效果如下所示:
