什么是云词
词云,也称为文本云或标签云。在词云图片制作中,一般我们规定特定文本词在文本数据源中出现的次数越多,说明该词越重要,其在词云中所占区域也就越大。词云可以利用常见的几何图形,或者其他不规则的图片素材形状来作为界限。词云不仅可以应用在企业数据分析上,还可以应用到媒体营销或者平面设计当中。
大概长这样:

快速实现
要实现词云,首先肯定是要获取词组和权重,然后再根据数据进行可视化的展示。
分词
手动输入比较麻烦,一般根据句子进行分词,然后按照词语出现的次数计算权重。
这里推荐用【讯飞关键词提取API】,有免费的额度,类似的云平台基本上都有这类API。
https://www.xfyun.cn/doc/nlp/keyword-extraction/API.html
如果不想用云API,也可以用开源分词库,这里推荐jieba
https://github.com/fxsjy/jieba
可视化
直接用轮子:
https://github.com/timdream/wordcloud2.js
如果是基于echart,可以以扩展形式引入:
https://github.com/ecomfe/echarts-wordcloud
实现原理
这里主要分析wordcloud2.js的源码,简要说明。
假设我们要将一个不带旋转的词放入canvas中,如下图所示:
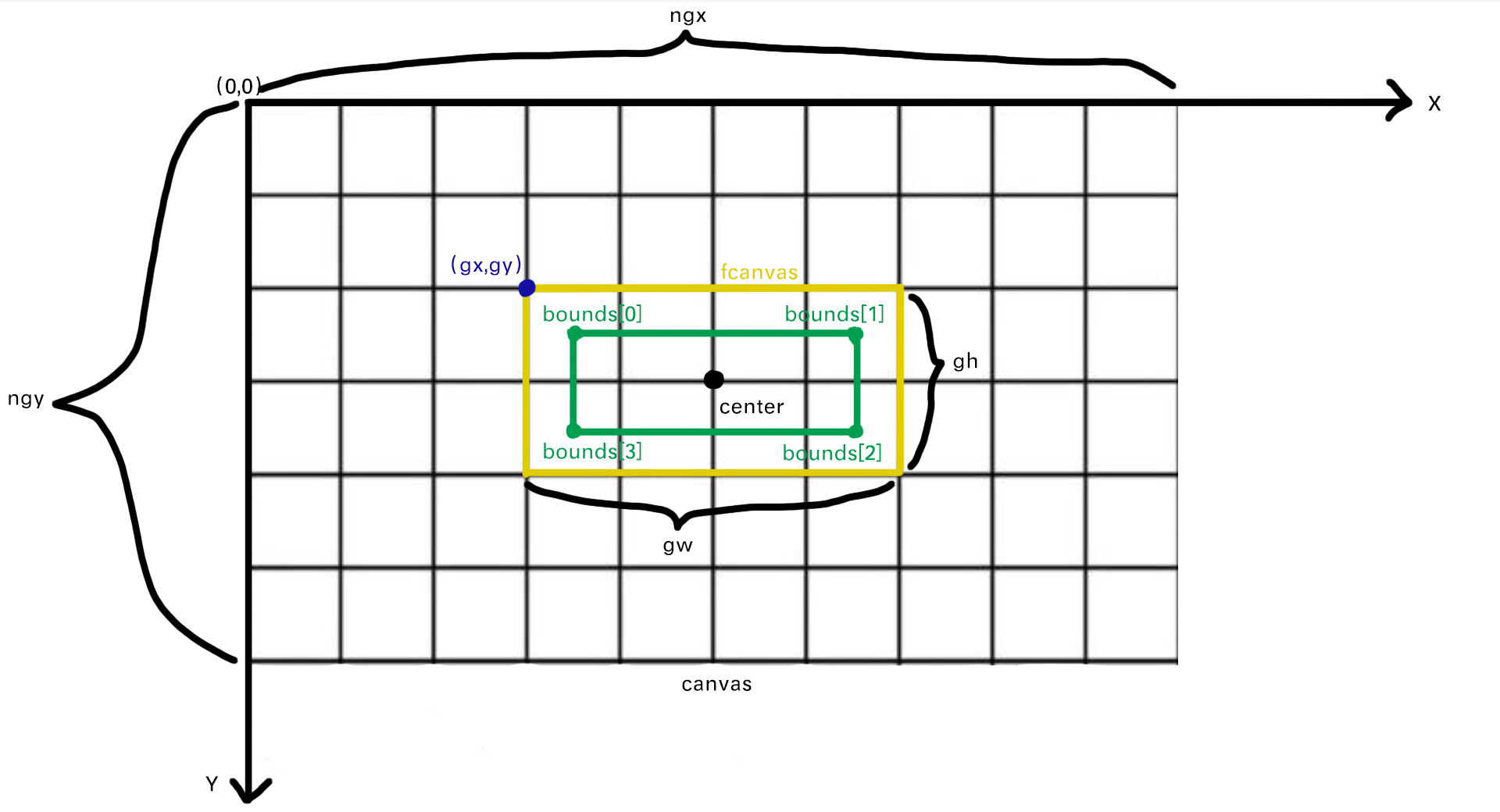
注:canvas坐标系Y轴是向下的。
1、canvas其实被切成了许多小方块(如例图所示),默认方块大小为16px,不小于4px,方格越大,间距越大。
2、初始化grid = [];用来判断方块中能否放置元素。
3、getTextInfo方法中,创建了一个新的fcanvas,通过measureText测量出词组宽度,为了防止文字被切,实际的fcanvas是大于测量的宽度的,如例图中黄色方框与绿色方框的关系。
fctx.fillText(word, fillTextOffsetX * mu, (fillTextOffsetY + fontSize * 0.5) * mu);
注意:这里为什么fillTextOffsetY要加上fontSize?
默认情况下fillText的字体是左下角在坐标点的,所以需要加上fontSize使其满足canvas坐标系。例如:
var c=document.getElementById("myCanvas");
var ctx=c.getContext("2d");
ctx.font="20px Georgia";
ctx.fillText("Hello World!",50,50);
ctx.fillRect(50,50,20,20)
可以看到文字是整个高出了方块的。
4、fcanvas填充完文字之后,通过getImageData获取图片像素信息,然后循环遍历每隔格子的每个像素,判断像素alpha是否有值,有则判断文字bounds边界(例图绿色方框),继续循环下一个格子。
其中,bounds的值为【小y,大x,大y,小x】,通过这4个值,就可以得出边界坐标和宽高。
左上:【小x,小y】
右上:【大x,小y】
左下:【小x,大y】
右下:【大x,大y】
宽:大x-小x
高:大y-小y
注意:imageData[((gy * g + y) * width + (gx * g + x)) * 4 + 3]
getImageData() 方法返回 ImageData 对象,该对象拷贝了画布指定矩形的像素数据。
对于 ImageData 对象中的每个像素,都存在着四方面的信息,即 RGBA 值:
R - 红色 (0-255)
G - 绿色 (0-255)
B - 蓝色 (0-255)
A - alpha 通道 (0-255; 0 是透明的,255 是完全可见的)
color/alpha 以数组形式存在,并存储于 ImageData 对象的 data 属性中。
这里乘以4是因为每个像素占4个下标,加3是为了获取alpha值。
5、从中心点位置到半径范围内遍历,结合计算出的文字信息判断格子是否被占用,没被占用则填充文字,更新格子的值,直到放不下或放完为止。

红色部分即为被“占领”的方格。
6、图案遮罩如何实现的?
我们可以通过上传图片,实现图片遮罩,白色部分将会被忽略,文字将被填充到黑色部分。


还记得grid[]吗?其实我们在上传图片之后,通过getImageData获取图片数据,将白色的部分都标记成了已被占用的状态,所以后续的遍历,只会找到黑色的部分进行填充。