前言
如果想做好一款产品,数据统计一定是必不可少的功能,它为产品经理验证功能可行性提供数据支撑,为后期数据分析提供高纬度业务数据,同时产品经理会经常根据不同的业务场景,提出不同的统计需求。
不过大多数情况下,我们仅通过缓存、数据库,配合一些统计查询语句,就可以应付绝大多数的统计场景。这里结合我自身的经验,根据产品的不同阶段,分享一下数据统计的简单实现思路。
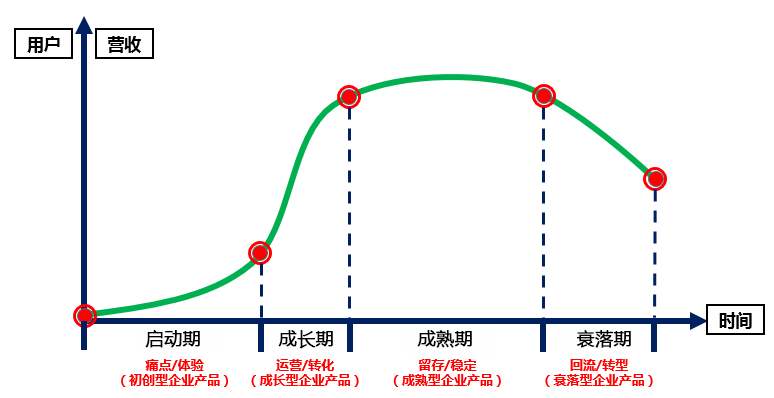
初期
产品初期的时候,我们的主要精力放在业务功能的实现上,所以不会花太大精力到很细化的数据统计部分,这种情况下,当然是优先考虑使用第三方的免费统计平台。
下面就推荐几个三方统计平台,我们只要根据相关文档做简单的接入,就可以快速实现数据统计功能了。
说到CNZZ大家肯定不陌生,最早在做一些门户网站的时候,一般都会接入CNZZ,最主要它是免费的,直到2016年友盟、缔元信.网络数据、CNZZ三家公司宣布合并,联手打造新公司,更名为“友盟+”,为我们提供了APP、网站、小程序的统计。
类似的平台还有:
百度统计:https://tongji.baidu.com
腾讯移动分析:https://mta.qq.com
可以看到的是,三方统计的数据通过用户信息获取到的,所以统计的内容也都是基于用户信息,对于前期仅验证AAARR模型,和那些不需要统计“内部”数据的情况,基本完全够用了。
中期

产品中期的时候,也积累了一定的“内部”数据,比如历史订单数据,实时下单数据,设备使用数据等等,这些数据原则上是也不会公开给三方平台,并且第三方平台也不提供接口让我们接入自己的后台,所以这个时候就需要我们在自己的平台实现数据统计模块了。
当然,用户基础数据统计这一块如果不是必须自行统计的话,我们还是可以依旧直接用第三方,把精力放到业务数据统计中去,只不过这个时候产品运营需要打开两个统计后台查看。
非实时数据统计
这个比较好办,因为数据部分我们都有记录了,一般存在mysql中,那么每天晚上凌晨(业务低峰期)直接执行脚本通过mysql的聚合查询语句查询即可,然后写入汇总表。
汇总表需要根据业务统计需求划分好纬度字段,一般只统计到最细化的那一部分。
例如对于订单表,从交易纬度按日汇总统计,包括日下单数、日支付数、日退款数等。
- 如果是统计范围是全平台,那么每天就汇总一条记录,后面如果需要统计平台的周汇总数据,月汇总数据,直接从日汇总表进行一次聚合查询即可,就不需要再创建周汇总表、月汇总表了。
- 如果是统计范围是按商户,那么每天需要汇总商户数条记录,这种情况下如果商户(用户)很多,在做按月汇总时,可能还需要再提取出高一层的按月汇总表。
总之尽可能的空间换时间。
实时数据
在需要统计今日数据的时候,直接用mysql就比较吃力了,这时候就考虑用缓存,redis又派上用场了。
对于类似PV(浏览量,用户每点一次记录一次),给每个页面配置一个独立的redis 计数器,把这个计数器的 key 后缀加上当天的日期。这样每来一个请求,就执行 INCRBY 指令一次,最终就可以统计出当天不同页面的 PV 数据了。
又以事实下单数为例:
- 如果需要按商户区分,那么给每个商户设置一个独立的redis计数器,key设置成这样 “dayOrederCount:date:merchantId”,其中merchantId为商户id,date为当天日期。
- 如果需要统计全平台的下单数,那么给平台设置一个独立的redis计数器,key设置成这样 “dayOrederCount:date”,下单成功之后累加即可。
- 如果能确保实时数据的准确,那么晚上执行统计脚本的时候可以直接将缓存数据写入,避免多一次的聚合查询。
对于判断用户是否已经执行(使用)过某些方法。
- 如果数据量比较小,可以考虑基于redis使用hashmap、set、bitmap,每次通过缓存判断是否存在即可。
- 如果数据量比较大,可以将数据冷热分离,冷历史操作记录依旧需要写入mysql,按需读取当前用户的记录到reids中,设置一个过期时间,再通过方法判断是否存在,这样可以避免频繁查询mysql,同时又减少了redis的存储大小。
- 如果数据量比较大,但又不需要精准判断,可以基于使用布隆过滤器(Bloom Filter)
布隆过滤器(Bloom Filter) 实际上 是一个很长的二进制向量和一系列随机映射函数 (hash),你也可以把它 简单理解 为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那么一定不存在。
对于不要求精准数据,只需要统计独立总数,并且访问数据量很大的情况,如UV,同一个用户一天之内的多次访问请求只能计数一次(基数统计)
可以考虑使用redis的HyperLogLog,主要用到了pfadd 和 pfcount 方法。
HyperLogLog基于概率通过分桶调和平均能够使用极少的内存来统计巨量的数据。
在 Redis 中实现的 HyperLogLog,只需要12K内存就能统计2^64个数据。计数存在一定的误差,误差率整体较低。标准误差为 0.81% 。
误差可以被设置辅助计算因子进行降低。
后期
当公司产品发展壮大之后,会产生大量的数据,需要我们进一步分析统计,这个时候光靠mysql是很难支撑了的,就需要我们建立数据仓库,根据统计需求进行在线分析或离线计算。
如果要自行建立的话,可以考虑Elasticsearch、hadoop大礼包等,但是需要投入大量的人力物力财力,
所以如果非必要,我们可以直接接入云计算。
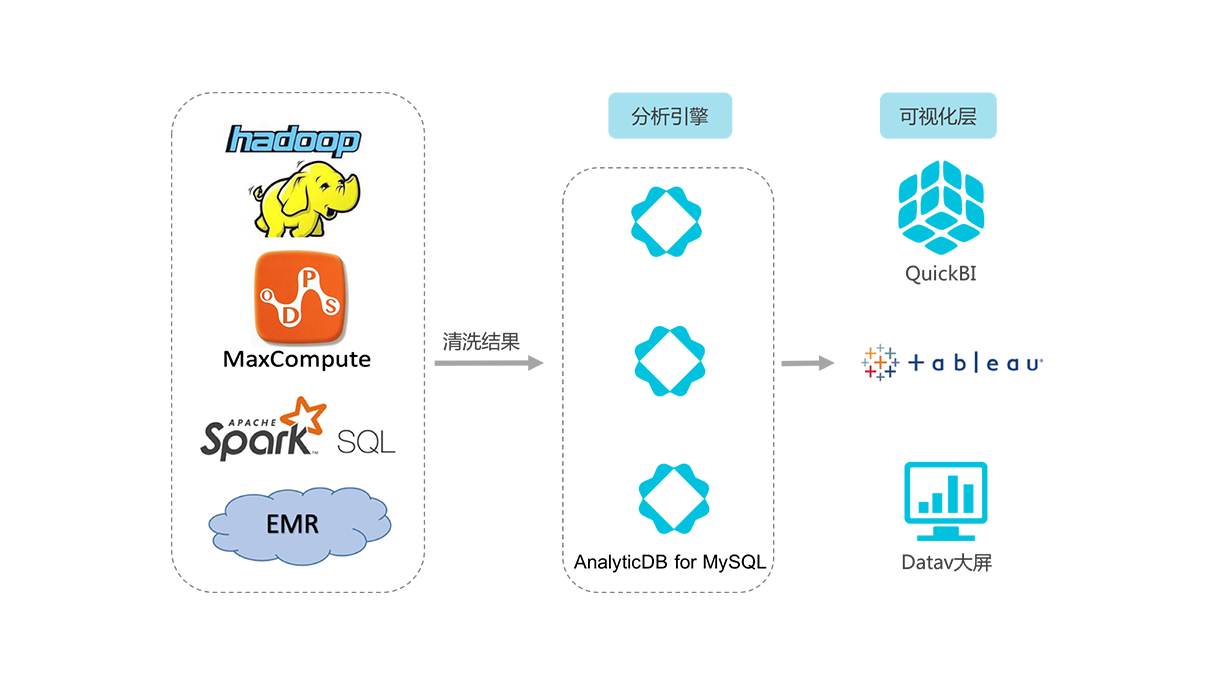
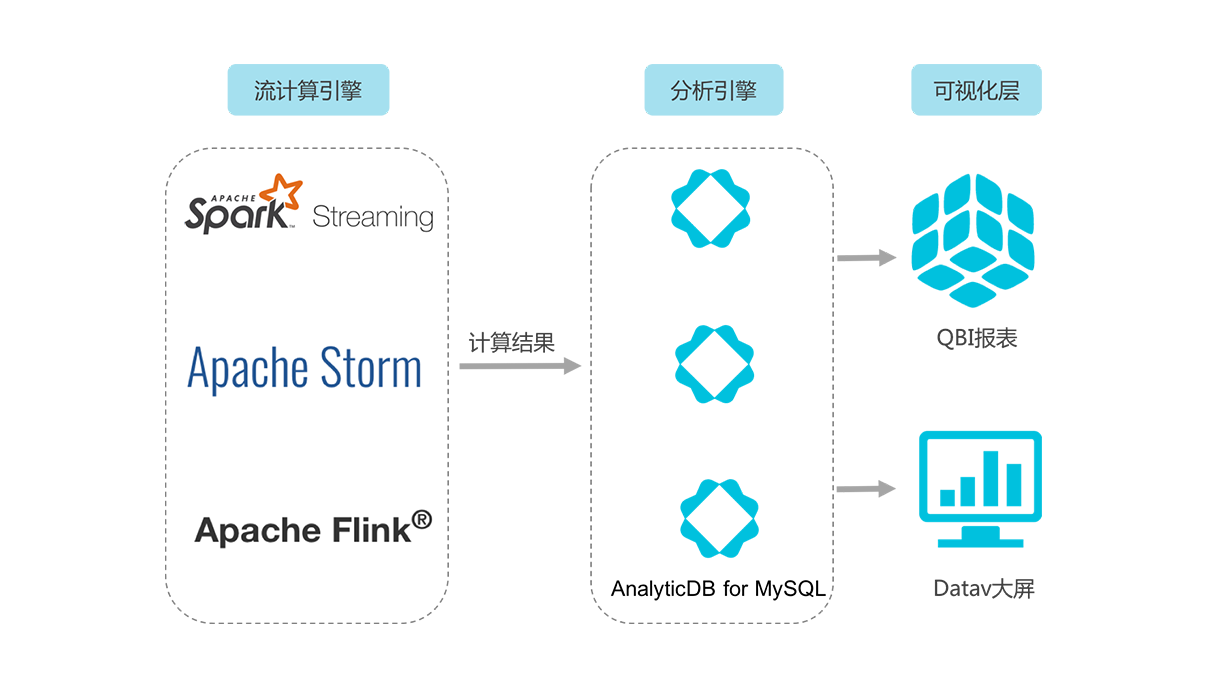
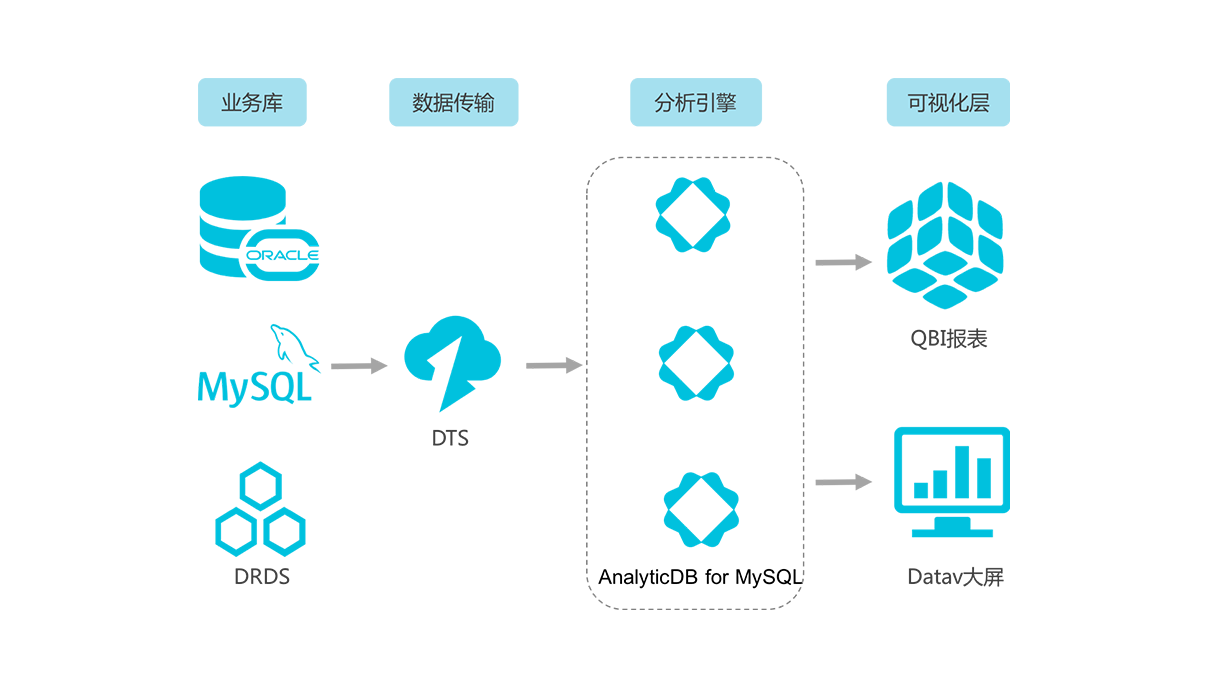
像阿里云就提供了表格存储、云原生数据仓库AnalyticDB(原ADS)、日志服务等,再配合上述的方法,基本上可以满足统计需求。
参考:
http://imhuchao.com/1271.html
https://www.zhihu.com/question/53416615