1Time
import time print(time.time()) print(time.clock())#计算cpu执行时间 print(time.gmtime())#世界标准时间 print(time.strftime()) #Commonly used format codes: 设置时间第一个参数为设置时间格式 # %Y Year with century as a decimal number. # %m Month as a decimal number [01,12]. # %d Day of the month as a decimal number [01,31]. # %H Hour (24-hour clock) as a decimal number [00,23]. # %M Minute as a decimal number [00,59]. # %S Second as a decimal number [00,61]. # %z Time zone offset from UTC. # %a Locale's abbreviated weekday name. # %A Locale's full weekday name. # %b Locale's abbreviated month name. # %B Locale's full month name. # %c Locale's appropriate date and time representation. # %I Hour (12-hour clock) as a decimal number [01,12]. # %p Locale's equivalent of either AM or PM. print(time.strptime())#字符串时间转换为结构化时间 第一个参数为字符串第二个为时间格式 print(time.ctime())#当前时间格式固定 参数转化为标准时间从1970年开始算 print(time.mktime())#转换为时间戳
import datetime print(datetime.datetime.now())#直接看时间
2logging模块

日志格式:

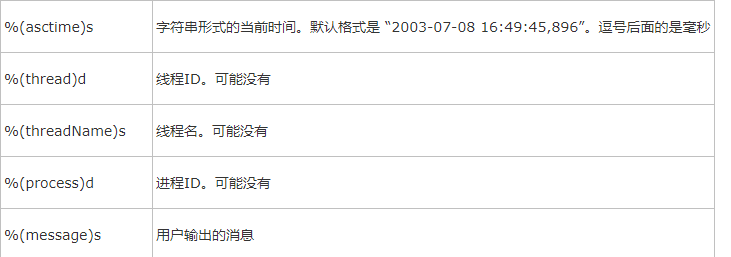


import logging # logging.debug('debug message') # logging.info('info message') # logging.warning('warning message') # logging.error('error message') # logging.critical('critical message') # # logging.basicConfig(level=logging.DEBUG,#级别 # format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)',#格式 # datefmt='%a,%d %b %Y %H:%M:%S',#时间格式 # filename='/tmp/test.log',#文件目录名字 # filemode='w')#设置输出到文件 logger=logging.getLogger() #创建一个handler,用于写入日志文件 fh=logging.FileHandler('test.log') #再创建一个handler,用于输出控制台 ch=logging.StreamHandler() logger.setLevel(logging.DEBUG) formatter=logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)') fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) logger.addHandler(ch)
3OS模块
import os os.getcwd()#获得工作目录 os.chdir()#更改当前脚本工作目录 os.curdir#当前路径 os.makedirs()#生成多层文件夹 os.removedirs()#删除多层文件夹有内容的文件夹不删除 os.mkdir()#生成文件夹只能创建一个文件夹 os.rmdir()#删除一个文件夹 os.listdir()#输出当前路径下的文件文件夹 os.remove()#删除一个文件 os.rename()#更改文件名 os.stat()#文件信息 os.sep()#输出操作系统指定的路径分隔符 os.linesep()#输出终止符(换行符 os.pathsep()#路径分隔符 os.system()#运行shell命令 os.environ#环境变量 os.path.abspath()#绝对路径 os.path.split()#对路径进行分割 路径 文件名 os.path.dirname()#上一个文件夹的名字 os.path.basename()#返回最后文件名 os.path.join()#路径拼接
4sys模块
import sys #与python解释器交互 # sys.argv() #命令行参数List,第一个元素是程序本身路径 # sys.exit() #退出程序,正常退出时exit(0) print(sys.version) #获取Python解释程序的版本信息 # sys.maxint() #最大的Int值 # sys.path() #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 # sys.platform() #返回操作系统平台名称 #sys.path.append()#添加路径 sys.stdout.write('please:')#标准输出
5hashlib模块
import hashlib#加密模块 import time m=hashlib.md5() print(m) t_start=time.time() m.update('hello world'.encode('utf-8')) time.sleep(2) t_end=time.time() print(t_end-t_start) print(m.hexdigest()) s=hashlib.sha256() s.update('hello world'.encode('utf-8')) print(s.hexdigest())
6ConfigParser模块
import configparser config=configparser.ConfigParser() # config['DEFAULT']={'ServerAliveInterval':'45', # 'Compression':'yes', # 'CompressionLevel':'9'} # # config['bitbucket.org']={} # config['bitbucket.org']['User']='hg' # config['topsecret.server.com']={} # topsecret=config['topsecret.server.com'] # topsecret['Host Port']='50022' # topsecret['ForwardX11']='no' # config['DEFAULT']['ForwardX11']='yes' # with open('example.ini','w')as configfile: # config.write(configfile) config.read('example.ini') # print(config.sections()) # print(config.defaults()) # for key in config['bitbucket.org']: # print(key) # config.remove_section('topsecret.server.com') config.set('bitbucket.org','user','alex') config.write(open('example.ini','w'))
7json&pickle模块
json,用于字符串 和 python数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
import json dic={'name':'alex','age':'18'} data=json.dumps(dic)#转换为json形式的仿字典 f=open('test','w') f.write(data) f.close() #向文件写入1 dic={'name':'alex','age':'18'} f=open('test','w') import json json.dump(dic,f) f.close()#向文件写入2
import json f=open('test','r') # data=f.read() # data=json.loads(data)#将json模式的仿字典转化为python形式的字典 data=json.load(f) f.close() print(data['name']) #从文件读取数据
pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump、loads、load

8shelve模块
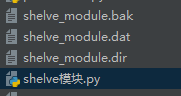
import shelve f=shelve.open('shelve_module') # f['info']={'name':'alex','age':'18'} data=f.get('info') print(data)
代码运行后结果为
9xml处理模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
1 <?xml version="1.0"?> 2 <data> 3 <country name="Liechtenstein"> 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() print(root.tag) #遍历xml文档 for child in root: print(child.tag, child.attrib) for i in child: print(i.tag,i.text) #只遍历year 节点 for node in root.iter('year'): print(node.tag,node.text)
修改和删除xml文档内容
import xml.etree.ElementTree as ET tree = ET.parse("xmltest.xml") root = tree.getroot() #修改 for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes") tree.write("xmltest.xml") #删除node for country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country) tree.write('output.xml')
自己创建xml文档
import xml.etree.ElementTree as ET new_xml = ET.Element("namelist") name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"}) age = ET.SubElement(name,"age",attrib={"checked":"no"}) sex = ET.SubElement(name,"sex") sex.text = '33' name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"}) age = ET.SubElement(name2,"age") age.text = '19' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8",xml_declaration=True) ET.dump(new_xml) #打印生成的格式
10PyYAML模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
Subprocess模块
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes. This module intends to replace several older modules and functions:
os.system
os.spawn*
The recommended approach to invoking subprocesses is to use the run() function for all use cases it can handle. For more advanced use cases, the underlying Popen interface can be used directly.
The run() function was added in Python 3.5; if you need to retain compatibility with older versions, see the Older high-level API section.
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False)Run the command described by args. Wait for command to complete, then return a CompletedProcess instance.
The arguments shown above are merely the most common ones, described below in Frequently Used Arguments (hence the use of keyword-only notation in the abbreviated signature). The full function signature is largely the same as that of the Popen constructor - apart from timeout, input and check, all the arguments to this function are passed through to that interface.
This does not capture stdout or stderr by default. To do so, pass PIPE for the stdout and/or stderr arguments.
The timeout argument is passed to Popen.communicate(). If the timeout expires, the child process will be killed and waited for. The TimeoutExpired exception will be re-raised after the child process has terminated.
The input argument is passed to Popen.communicate() and thus to the subprocess’s stdin. If used it must be a byte sequence, or a string if universal_newlines=True. When used, the internal Popen object is automatically created withstdin=PIPE, and the stdin argument may not be used as well.
If check is True, and the process exits with a non-zero exit code, a CalledProcessError exception will be raised. Attributes of that exception hold the arguments, the exit code, and stdout and stderr if they were captured.
常用subprocess方法示例
#执行命令,返回命令执行状态 , 0 or 非0
>>> retcode = subprocess.call(["ls", "-l"])
#执行命令,如果命令结果为0,就正常返回,否则抛异常
>>> subprocess.check_call(["ls", "-l"])
0
#接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
>>> subprocess.getstatusoutput('ls /bin/ls')
(0, '/bin/ls')
#接收字符串格式命令,并返回结果
>>> subprocess.getoutput('ls /bin/ls')
'/bin/ls'
#执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
>>> res=subprocess.check_output(['ls','-l'])
>>> res
b'total 0
drwxr-xr-x 12 alex staff 408 Nov 2 11:05 OldBoyCRM
'
#上面那些方法,底层都是封装的subprocess.Popen
poll()
Check if child process has terminated. Returns returncode
wait()
Wait for child process to terminate. Returns returncode attribute.
terminate() 杀掉所启动进程
communicate() 等待任务结束
stdin 标准输入
stdout 标准输出
stderr 标准错误
pid
The process ID of the child process.
#例子
>>> p = subprocess.Popen("df -h|grep disk",stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
>>> p.stdout.read()
b'/dev/disk1 465Gi 64Gi 400Gi 14% 16901472 104938142 14% /
'
>>> subprocess.run(["ls", "-l"]) # doesn't capture output CompletedProcess(args=['ls', '-l'], returncode=0) >>> subprocess.run("exit 1", shell=True, check=True) Traceback (most recent call last): ... subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1 >>> subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE) CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0, stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null ')
调用subprocess.run(...)是推荐的常用方法,在大多数情况下能满足需求,但如果你可能需要进行一些复杂的与系统的交互的话,你还可以用subprocess.Popen(),语法如下:
p = subprocess.Popen("find / -size +1000000 -exec ls -shl {} ;",shell=True,stdout=subprocess.PIPE) print(p.stdout.read())
可用参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
需要交互的命令示例
import subprocess obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE) obj.stdin.write('print 1 ') obj.stdin.write('print 2 ') obj.stdin.write('print 3 ') obj.stdin.write('print 4 ') out_error_list = obj.communicate(timeout=10) print out_error_list
subprocess实现sudo 自动输入密码
import subprocess def mypass(): mypass = '123' #or get the password from anywhere return mypass echo = subprocess.Popen(['echo',mypass()], stdout=subprocess.PIPE, ) sudo = subprocess.Popen(['sudo','-S','iptables','-L'], stdin=echo.stdout, stdout=subprocess.PIPE, ) end_of_pipe = sudo.stdout print "Password ok Iptables Chains %s" % end_of_pipe.read()
random
import random print(random.random())#随机数0到1 print(random.randint(1,8))#1 到8 的整数 print(random.choice())#在随机序列里选择 print(random.sample())#从序列里随机选可以指定选几个 print(random.randrange(1,8))#1到7 的整数 不包括右边
subproces
当我们需要调用系统的命令的时候,最先考虑的os模块。用os.system()和os.popen()来进行操作。但是这两个命令过于简单,不能完成一些复杂的操作,如给运行的命令提供输入或者读取命令的输出,判断该命令的运行状态,管理多个命令的并行等等。这时subprocess中的Popen命令就能有效的完成我们需要的操作。subprocess模块允许一个进程创建一个新的子进程,通过管道连接到子进程的stdin/stdout/stderr,获取子进程的返回值等操作。
The subprocess module allows you to spawn new processes, connect to their input/output/error pipes, and obtain their return codes.
This module intends to replace several other, older modules and functions, such as: os.system、os.spawn*、os.popen*、popen2.*、commands.*
这个模块一个类:Popen。
1 #Popen它的构造函数如下: 2 subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None,stderr=None, preexec_fn=None, close_fds=False, shell=False,cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0) 3 # 参数args可以是字符串或者序列类型(如:list,元组),用于指定进程的可执行文件及其参数。 4 # 如果是序列类型,第一个元素通常是可执行文件的路径。我们也可以显式的使用executeable参 5 # 数来指定可执行文件的路径。在windows操作系统上,Popen通过调用CreateProcess()来创 6 # 建子进程,CreateProcess接收一个字符串参数,如果args是序列类型,系统将会通过 7 # list2cmdline()函数将序列类型转换为字符串。 8 # 参数bufsize:指定缓冲。我到现在还不清楚这个参数的具体含义,望各个大牛指点。 9 # 参数executable用于指定可执行程序。一般情况下我们通过args参数来设置所要运行的程序。如 10 # 果将参数shell设为True,executable将指定程序使用的shell。在windows平台下,默认的 11 # shell由COMSPEC环境变量来指定。 12 # 参数stdin, stdout, stderr分别表示程序的标准输入、输出、错误句柄。他们可以是PIPE, 13 # 文件描述符或文件对象,也可以设置为None,表示从父进程继承。 14 # 15 # 参数preexec_fn只在Unix平台下有效,用于指定一个可执行对象#(callable object),它将在子进程运行之前被调用。 16 # 参数Close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会 17 # 继承父进程的输入、输出、错误管道。我们不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 18 # 如果参数shell设为true,程序将通过shell来执行。 19 # 参数cwd用于设置子进程的当前目录。 20 # 参数env是字典类型,用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。 21 # 参数Universal_newlines:不同操作系统下,文本的换行符是不一样的。如:windows下 22 # 用’/r/n’表示换,而Linux下用’/n’。如果将此参数设置为True,Python统一把这些换行符当 23 # 作’/n’来处理。 24 # 参数startupinfo与createionflags只在windows下用效,它们将被传递给底层的 25 # CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等。
import subprocess a = subprocess.Popen('ls') # 创建一个新的进程,与主进程不同步 print('>>>>>>>', a) # a是Popen的一个实例对象 ''' >>>>>>> <subprocess.Popen object at 0x10185f860> __init__.py __pycache__ log.py main.py '''
# subprocess.Popen('ls -l',shell=True) # subprocess.Popen(['ls','-l']) # subprocess.PIPE # # 在创建Popen对象时,subprocess.PIPE可以初始化stdin, stdout或stderr参数。表示与子进程通信的标准流。 # import subprocess # # # subprocess.Popen('ls') # p = subprocess.Popen('ls', stdout=subprocess.PIPE) # 结果跑哪去啦? # # print(p.stdout.read()) # 这这呢:b'__pycache__ hello.py ok.py web ' # 这是因为subprocess创建了子进程,结果本在子进程中,if 想要执行结果转到主进程中,就得需要一个管道,即 : stdout=subprocess.PIPE # # subprocess.STDOUT # # 创建Popen对象时,用于初始化stderr参数,表示将错误通过标准输出流输出。 # # Popen的方法 # Popen.poll() # 用于检查子进程是否已经结束。设置并返回returncode属性。 # # Popen.wait() # 等待子进程结束。设置并返回returncode属性。 # # Popen.communicate(input=None) # 与子进程进行交互。向stdin发送数据,或从stdout和stderr中读取数据。可选参数input指定发送到子进程的参数。 Communicate()返回一个元组:(stdoutdata, stderrdata)。注意:如果希望通过进程的stdin向其发送数据,在创建Popen对象的时候,参数stdin必须被设置为PIPE。同样,如 果希望从stdout和stderr获取数据,必须将stdout和stderr设置为PIPE。 # # Popen.send_signal(signal) # 向子进程发送信号。 # # Popen.terminate() # 停止(stop)子进程。在windows平台下,该方法将调用Windows API TerminateProcess()来结束子进程。 # # Popen.kill() # 杀死子进程。 # # Popen.stdin # 如果在创建Popen对象是,参数stdin被设置为PIPE,Popen.stdin将返回一个文件对象用于策子进程发送指令。否则返回None。 # # Popen.stdout # 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 # # Popen.stderr # 如果在创建Popen对象是,参数stdout被设置为PIPE,Popen.stdout将返回一个文件对象用于策子进程发送指令。否则返回 None。 # # Popen.pid # 获取子进程的进程ID。 # # Popen.returncode # 获取进程的返回值。如果进程还没有结束,返回None。 # supprocess模块的工具函数 # supprocess模块提供了一些函数,方便我们用于创建进程来实现一些简单的功能。 # # subprocess.call(*popenargs, **kwargs) # 运行命令。该函数将一直等待到子进程运行结束,并返回进程的returncode。如果子进程不需要进行交 # 互, 就可以使用该函数来创建。 # # subprocess.check_call(*popenargs, **kwargs) # 与subprocess.call(*popenargs, **kwargs) # 功能一样,只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常。在异常对象中,包 # 括进程的returncode信息。 # # check_output(*popenargs, **kwargs) # 与call() # 方法类似,以byte # string的方式返回子进程的输出,如果子进程的返回值不是0,它抛出CalledProcessError异常,这个异常中的returncode包含返回码,output属性包含已有的输出。 # # getstatusoutput(cmd) / getoutput(cmd) # 这两个函数仅仅在Unix下可用,它们在shell中执行指定的命令cmd,前者返回(status, output),后者返回output。其中,这里的output包括子进程的stdout和stderr。 # import subprocess # # #1 # # subprocess.call('ls',shell=True) # ''' # hello.py # ok.py # web # ''' # # data=subprocess.call('ls',shell=True) # # print(data) # ''' # hello.py # ok.py # web # 0 # ''' # # #2 # # subprocess.check_call('ls',shell=True) # # ''' # hello.py # ok.py # web # ''' # # data=subprocess.check_call('ls',shell=True) # # print(data) # ''' # hello.py # ok.py # web # 0 # ''' # # 两个函数区别:只是如果子进程返回的returncode不为0的话,将触发CalledProcessError异常 # # # # #3 # # subprocess.check_output('ls')#无结果 # # # data=subprocess.check_output('ls') # # print(data) #b'hello.py ok.py web ' # 交互命令: # # 终端输入的命令分为两种: # # 输入即可得到输出,如:ifconfig # 输入进行某环境,依赖再输入,如:python # 需要交互的命令示例
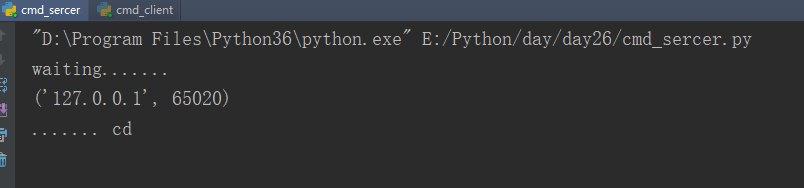
一个例子(在socket编程中,传输命令返回结果,类似于xshell的交互):
1 import subprocess 2 3 4 import socket 5 6 sk = socket.socket() # 创建对象 7 address = ('127.0.0.1', 8000) # 端口号用1024之后的 8 sk.bind(address) # 绑定 9 sk.listen(3) # 最大可以有三个人等待 10 print('waiting.......') 11 while 1: 12 conn,addr=sk.accept() 13 print(addr) 14 while 1: 15 try: 16 data=conn.recv(1024) 17 except Exception: 18 break 19 if not data:break 20 print('.......',str(data,'utf8')) 21 22 obj=subprocess.Popen(str(data,'utf8'),shell=True,stdout=subprocess.PIPE)#第一个是命令,第二个是shell=True第三个是管道命令 23 cmd_result=obj.stdout.read() 24 result_len=bytes(str(len(cmd_result)),'utf8') 25 conn.sendall(result_len) 26 conn.recv(1024) 27 conn.sendall(cmd_result)
1 import socket 2 3 sk=socket.socket()#创建客户端 family type 4 address=('127.0.0.1',8000)#22 5 6 7 sk.connect(address) 8 while True: 9 inp=input('<<<') 10 if inp=='exit': 11 break 12 sk.send(bytes(inp,'utf8')) 13 result_len=int(str(sk.recv(1024),'utf8')) 14 sk.send(bytes('ok','utf8')) 15 data=bytes() 16 while len(data)!=result_len: 17 recv=sk.recv(1024) 18 data+=recv 19 print(str(data,'gbk')) 20 sk.close()
结果: