1、请解释enum和Enum的区别?
- enum:是从JDK1.5之后提供的一个关键字, 用于定于枚举类;
- Enum:是一个抽象类,所有使用enum关键字定义的类就默认继承此类。
2、请解释volatile与synchronized的区别?
- volatile主要在属性上使用,而synchronized是在代码块和方法上使用的;
- volatile无法描述同步的处理,它只是一种直接内存的处理,避免了副本的操作,而synchronized是实现同步的。
3、抽象类与接口的区别?
在实际开发中可以发现抽象类和接口的定义形式是非常相似的,这一点从JDK1.8开始实际上就特别明显了,因为从JDK1.8开始接口也可以定义default和static方法了,但是这两者依旧是有着明显的定义与使用区别的。
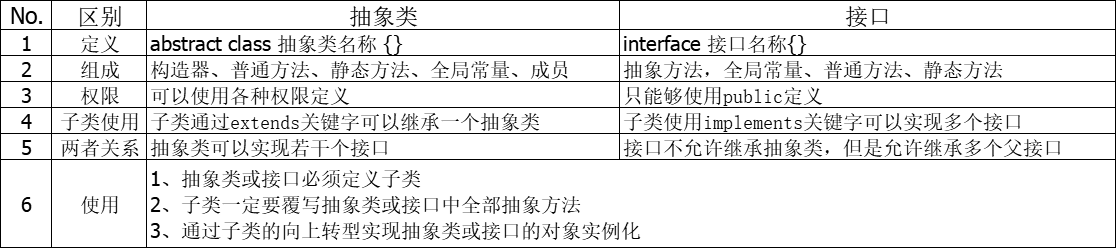
当抽象类和接口都可以使用的情况下,优先考虑接口,因为接口可以避免子类的单继承 局限。另外从正常设计角度而言,也需要先从接口来进行项目的整体设计。
4、请问ArrayList和LinkedList有什么区别?
- ArrayList是数组实现的集合操作,而LinkedList是链表实现的集合操作;
- 在使用List集合中的get()方法根据索引获取数据是,ArrayList的时间复杂度为1,而LinkedList的时间复杂度为n(n为集合长度);
- ArrayList在使用的时候默认的初始化对象数组长度大小为10,如果空间不足则会采用倍数的形式进行容量扩充,如果保存大数据量的时候可能会造成垃圾的产生以及性能下降,但是这个时候可以使用LinkedList子类保存。
5、请解释Collection.remove()与Iterator.remove()的区别?
- 在进行迭代输出的时候如果使用了Collection.remove()则会造成并发更新异常,导致程序删除出错,而此时只能够利用Iterator.remove()方法实现正常的删除处理。
6、PATH和CLASSPATH的区别?
- PATH:是操作系统提供的路径配置,定义所有可执行程序的路径;
- CLASSPATH:是由JRE提供的,用于定义Java程序解释是类加载路径,默认设置的为当前所在目录加载,可以通过“SET CLASSPATH=路径”的命令形式来进行定义;
- 关系:JVM ——> CLASSPATH定义的路径 ——> 加载字节码文件。
7、if和switch的区别?
- if分支结构主要是针对于关系表达式进行判断处理的分支操作;代码中若有符合条件的,在执行完相应代码后其余 if 不会再判断执行;
- switch是一个开关语句,它主要是根据内容来进行判断,且只能判断 int、char、枚举(JDK1.5)、String(JDK1.7)几种数据类型;若是满足条件的代码内没有写 break ,其余部分代码会继续执行。
8、请解释String类两种对象实例化方式的区别?
- 直接赋值:只会产生一个实例化对象,并且可以自动保存到对象池之中,以实现该字符串实例的重用;
- 构造方法:会产生两个实例化对象,并且不会自动入池,无法实现对象重用,但是可以利用intern()方法手动入池处理。
9、请解释String、StringBuffer、StringBuilder的区别?
- String类是字符串的首选类型,其最大的特点是内容不允许修改;
- StringBuffer与StringBuilder类的内容允许修改;
- StringBuffer是在JDK1.0的时候提供的,属于线程安全的操作,而StringBuilder是在JDK1.5之后提供的,属于非线程安全的操作。
10、在进行HashMap的put()操作的时候,如何实现容量扩充的?
- 在HashMap类里面提供有一个"DEFAULT_INITIAL_CAPACITY"常量,作为初始化容量配置,而后这个常量的默认大小为16个元素,也就是说默认可以保存最大内容是16;
- 当保存的内容的容量超过了阈值(DEFAULT_LOAD_FACTOR = 0.75f),相当于"容量 * 阈值 = 12"保存12个元素的时候就会进行容量的扩充;
- 在进行扩充的时候HashMap采用的是成倍的库充模式。
11、请解释HashMap的工作原理(JDK1.8之后开始的)?
- 在HashMap之中进行数据存储的依然是利用了Node类完成的,这种情况下就证明可以使用的数据结构只有链表(时间复杂度“O(n)”)和二叉树(时间复杂度“O(logn)”);
- 从JDK1.8开始,HashMap的实现出现了改变,因为其要适应大数据时代的海量数据问题,所以对于其存储发生变化,并且在HashMap类的内部出现了一个常量:static final int TREEIFY_THRESHOLD = 8,在使用HashMap进行数据保存的时候,如果保存的数据个数没有超过8,那么会按照链表的形式进行存储,如果超过了则会把链表转为红黑树以实现树的平衡,并且利用左旋与右旋保证数据的查询性能;
12、请解释HashMap和Hashtable的区别?
- HashMap中的方法都属于异步操作(非线程安全),HashMap允许保存有null;
- Hashtable中的方法都属于同步方法(线程安全),Hashtable中的key和vaiue都不允许存null;
13、如果在使用HashMap进行数据操作的时候出现了Hash冲突(Hash码相同),HashMap是如何解决的?
- 当出现了Hash冲突之后为了保证程序的正常执行,会在冲突的位置上将所有的Hash冲突的内容转入链表保存;
14、请解释throws和throw的区别?
- throw是在代码块中使用的,主要是手工进行异常对象的抛出;
- throws是在定义方法上使用的,表示此方法中可能产生的异常明确告诉给调用处,由调用处进行处理;