什么是NUMA?
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。
所以NUMA(Non-Uniform Memory Access)就此得名:非一致访问分布共享存储技术
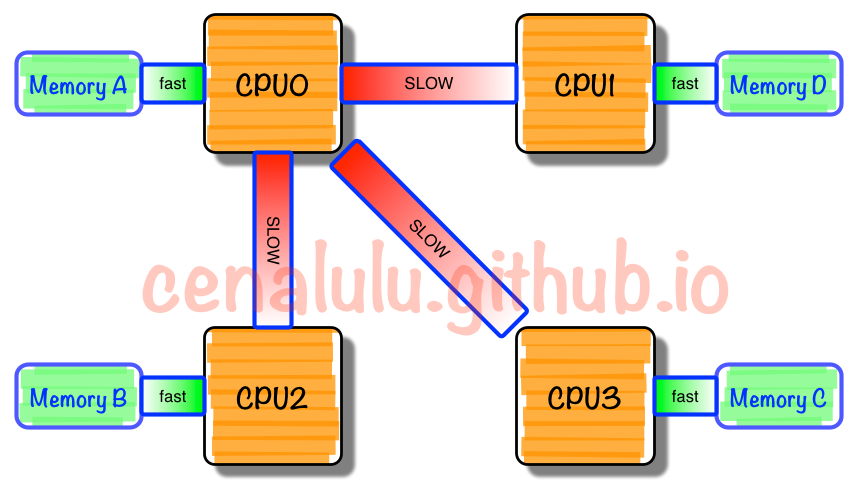
每个CPU模块之间都是通过互联模块进行连接和信息交互,CPU都是互通互联的,同时,每个CPU模块平均划分为若干个Chip(不多于4个),每个Chip都有自己的内存控制器及内存插槽。
在NUMA中还有三个节点的概念:
1)、本地节点:对于某个节点中的所有CPU,此节点称为本地节点。
2)、邻居节点:与本地节点相邻的节点称为邻居节点。
3)、远端节点:非本地节点或邻居节点的节点,称为远端节点。
4)、邻居节点和远端节点,都称作非本地节点(Off Node)。
CPU访问不同类型节点内存的速度是不相同的,访问本地节点的速度最快,访问远端节点的速度最慢,即访问速度与节点的距离有关,距离越远访问速度越慢,此距离称作Node Distance。应用程序要尽量的减少不通CPU模块之间的交互,如果应用程序能有方法固定在一个CPU模块里,那么应用的性能将会有很大的提升。
二、NUMA实践
1、安装numactl工具
Linux提供了一个手工调优的命令numactl(默认不安装)
#yum install numactl -y
#numactl --hardware 列举系统上的NUMA节点
2、查看numa状态
# numactl --show policy: default preferred node: current physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 cpubind: 0 1 nodebind: 0 1 membind: 0 1
# numastat node0 node1 numa_hit 1296554257 918018444 numa_miss 8541758 40297198 numa_foreign 40288595 8550361 interleave_hit 45651 45918 local_node 1231897031 835344122 other_node 64657226 82674322
说明:
- numa_hit —命中的,也就是为这个节点成功分配本地内存访问的内存大小
- numa_miss —把内存访问分配到另一个node节点的内存大小,这个值和另一个node的numa_foreign相对应。
- numa_foreign –另一个Node访问我的内存大小,与对方node的numa_miss相对应
- local_node ----这个节点的进程成功在这个节点上分配内存访问的大小
- other_node ----这个节点的进程 在其它节点上分配的内存访问大小
很明显,miss值和foreign值越高,就要考虑绑定的问题。
3、numad服务
在redhat6中,有一个numad的服务(需手工安装),它可以自动的监控我们cpu状况,并自动平衡资源,这个服务需要在内存使用量非常大的时候才会有明显的效果,当内存空余量较大时,需要关闭KSM,避免发生冲突。官方说在某些内存使用巨大的环境中,可能会提高50%的性能。
# service numad start
4、查看cpu和内存使用情况
# numactl --hardware available: 2 nodes (0-1) node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 node 0 size: 64337 MB node 0 free: 1263 MB node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 node 1 size: 64509 MB node 1 free: 30530 MB node distances: node 0 1 0: 10 21 1: 21 10
cpu0 可用 内存 1263 MB
cpu1 可用内存 30530 MB
当cpu0上申请内存超过1263M时必定使用swap,这个是很不合理的。
举例:
这里假设我要执行一个java param命令,此命令需要1G内存;一个python param命令,需要8G内存。
最好的优化方案时python在node1中执行,而java在node0中执行,那命令是:
#numactl --cpubind=0 --membind=0 python param
#numactl --cpubind=1 --membind=1 java param
5、NUMA的内存分配策略
1.缺省(default):总是在本地节点分配(分配在当前进程运行的节点上);
2.绑定(bind):强制分配到指定节点上;
3.交叉(interleave):在所有节点或者指定的节点上交织分配;
4.优先(preferred):在指定节点上分配,失败则在其他节点上分配。
因为NUMA默认的内存分配策略是优先在进程所在CPU的本地内存中分配,会导致CPU节点之间内存分配不均衡,当某个CPU节点的内存不足时,会导致swap产生,而不是从远程节点分配内存。这就是所谓的swap insanity 现象。
举例:
# numactl --hardware node 0 cpus: 0 2 4 6 node 0 size: 65490 MB node 0 free: 24447 MB node 1 cpus: 1 3 5 7 node 1 size: 65536 MB node 1 free: 16050 MB node distances: node 0 1 0: 10 20 1: 20 10
可以看到numa节点是2个,cpu物理节点是8个
现在我们绑定资源,两颗cpu,每颗4个物理节点,那么我们开4个mysql实例,每个实例绑定2个cpu物理节点
numactl --physcpubind=0,3 --localalloc mysqld_multi --defaults-extra-file=/etc/mysqld_multi.cnf start 1
–physcpubind 指定绑定的cpu节点,
–localalloc表示使用内存方式,不交叉,以免降低性能,
mysqld_multi是mysql实例启动命令
三、如何关闭NUMA
方法一:通过bios关闭
BIOS:interleave = Disable / Enable
方法二:通过OS关闭
1、编辑 /etc/default/grub 文件,加上:numa=off
GRUB_CMDLINE_LINUX="crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
注:参数只需加 numa=off 即可 (rd.lvm.lv是因为机器上做了lvm所以带有对应参数)
2、重新生成 /etc/grub2.cfg 配置文件:
# grub2-mkconfig -o /etc/grub2.cfg
3、重启操作系统
# reboot
4、确认:
# dmesg | grep -i numa [ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet[ 0.000000] NUMA turned off[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
# cat /proc/cmdline BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet