参考:http://techblog.youdao.com/?p=915#LinkTarget_699
word2vector是一个把词转换成词向量的一个程序,能够把词映射到K维向量空间,甚至词与词之间 的向量操作还能和语义相对应。如果换个思路,把词当做feature,那么word2vec就可以把feature映射到K维向量空间,一、什么是 word2vec?
采用的模型有 CBOW(Continuous Bag-Of-Words,即连续的词袋模型)和 Skip-Gram 两种
word2vec 通过训练,可以把对文本内容的处理简化为 K 维向量空间中的向量 运算,而向量空间上的相似度可以用来表示文本语义上的相似度。
。因此,word2vec 输出的词向量可以被用来做很多 NLP 相关的工作,比如聚类、找同义词、词性分 析等等
二、快速入门
简单介绍cmake makefile.txt → makefile make的关系
首先编写一个与平台无关的CMakelist.txt文本文件,这个文本文件是为了制定整个编译流程,然后通过cmake path(makelist.txt所在位置,在这个目录下就是 dian .) 生成本地化的Makefile文件 ,最后make 编译文件
总的来说就是
- 编写cmakelist.txt(跨平台的文件来制定整个编译流程)
- cmake .生成本地化的makefile
- make 编译 word2vec 工具
然后你想运行***脚本就sh ***.sh
demo-word.sh 中的代码如下,
主要工作为:
1) 编译(make)
2) 下载训练数据 text8,如果不存在。text8 中为一些空格隔开的英文单 词,但不含标点符号,一共有 1600 多万个单词。
3) 训练,大概一个小时左右,取决于机器配置
4) 调用 distance,查找最近的词
上github下载之后,打开文件夹你能看到很多.sh的脚本
这时候除了开心就是开心
因为运行脚本就ok了
首先敲入 make (由于有makefile文件直接这样就可以了 更何况没有makelist.txt cmake 也没有用)
简单介绍cmake makefile.txt → makefile make的关系
首先编写一个与平台无关的CMakelist.txt文本文件,这个文本文件是为了制定整个编译流程,然后通过cmake path(makelist.txt所在位置,在这个目录下就是 dian .) 生成本地化的Makefile文件 ,最后make 编译文件
总的来说就是
- 编写cmakelist.txt(跨平台的文件来制定整个编译流程)
- cmake .生成本地化的makefile
- make
然后你想运行***脚本就sh ***.sh
比如说我想知道一个词与谁的距离最近
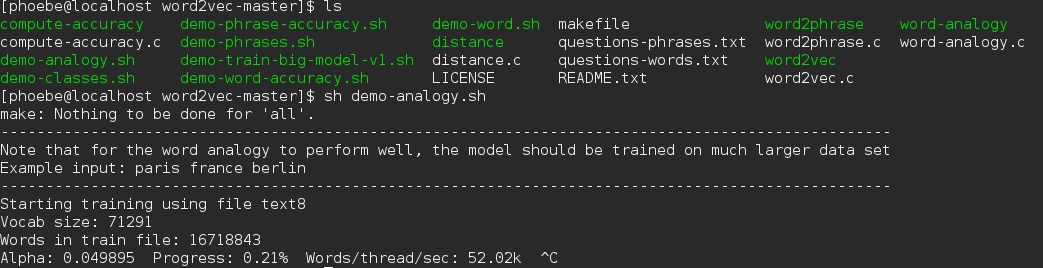
这个脚本里的内容首先会检查你有没有test8这个训练语料
如果没有它会自动下载,
下载之后就开始训练了
之后你可以输入三个单词
paris france berlin(分开的)
之后你会看到Germany出现在第一个位置
如果你不想运行脚本你也可以直接执行可执行的程序 比如:你可以在vectors.txt看到test8中的词转成了50维的词向量
nohup ./word2vec -train text8 -output vectors.txt -cbow 1 -size 50 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -iter 1 > test.log 2>&1 &
总之一句话,认真看脚本。。。。