1. 将新闻的正文内容保存到文本文件。
def writeNewsDetail(content):
f = open('gzccNews.txt','a',encoding='utf-8')
f.write(content)
f.close()
2. 将新闻数据结构化为字典的列表:
- 单条新闻的详情-->字典news
- 一个列表页所有单条新闻汇总-->列表newsls.append(news)
- 所有列表页的所有新闻汇总列表newstotal.extend(newsls)
import requests
import re
from bs4 import BeautifulSoup
from datetime import datetime
newsUrl = 'http://news.gzcc.cn/html/2017/xiaoyuanxinwen_0925/8249.html'
pageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
def writeNewsDetail(content):
f = open('gzccNews.txt','a',encoding='utf-8')
f.write(content)
f.close()
def getClickCount(newsUrl):
newsId = re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
resd = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId))
return (int(resd.text.split('.html')[-1].lstrip("('").rstrip("');")))
def getNewDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
news = {}
news['title'] = soupd.select('.show-title')[0].text # 标题
info = soupd.select('.show-info')[0].text # 连接
news['dt'] = datetime.strptime(info.lstrip('发布时间:')[:19], '%Y-%m-%d %H:%M:%S') # 发布时间
if info.find('来源:') > 0:
news['source'] = info[info.find('来源:'):].split()[0].lstrip('来源:')
else:
news['source'] = 'none'
news['content'] = soupd.select(".show-content")[0].text.strip()
writeNewsDetail(news['content'])
news['click'] = getClickCount(newsUrl)
news['newsUrl'] = newsUrl
return(news)
# content = soupd.select(".show-content")[0].text.strip()
# writeNewDetail(content)
def getListPage(pageUrl):
res=requests.get(pageUrl)
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
newslist = []
for news in soup.select('li'):
if len(news.select('.news-list-title')) > 0:
newsUrl=news.select('a')[0].attrs['href']#继续
newslist.append(getNewDetail(newsUrl))
return (newslist)
def getPageN():
res=requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/')
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
n=int(soup.select('.a1')[0].text.rstrip('条'))
return (n // 10 + 1)
newstotal = []
firstPageUrl = 'http://news.gzcc.cn/html/xiaoyuanxinwen/'
newstotal.extend(getListPage(firstPageUrl))
n=getPageN()
for i in range(n,n+1):
listPageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
newstotal.extend(getListPage(listPageUrl))
print(newstotal)
3. 安装pandas,用pandas.DataFrame(newstotal),创建一个DataFrame对象df.
import pandas df = pandas.DataFrame(newstotal) print(df)
4. 通过df将提取的数据保存到csv或excel 文件。
df.to_excel('news1.xlsx')
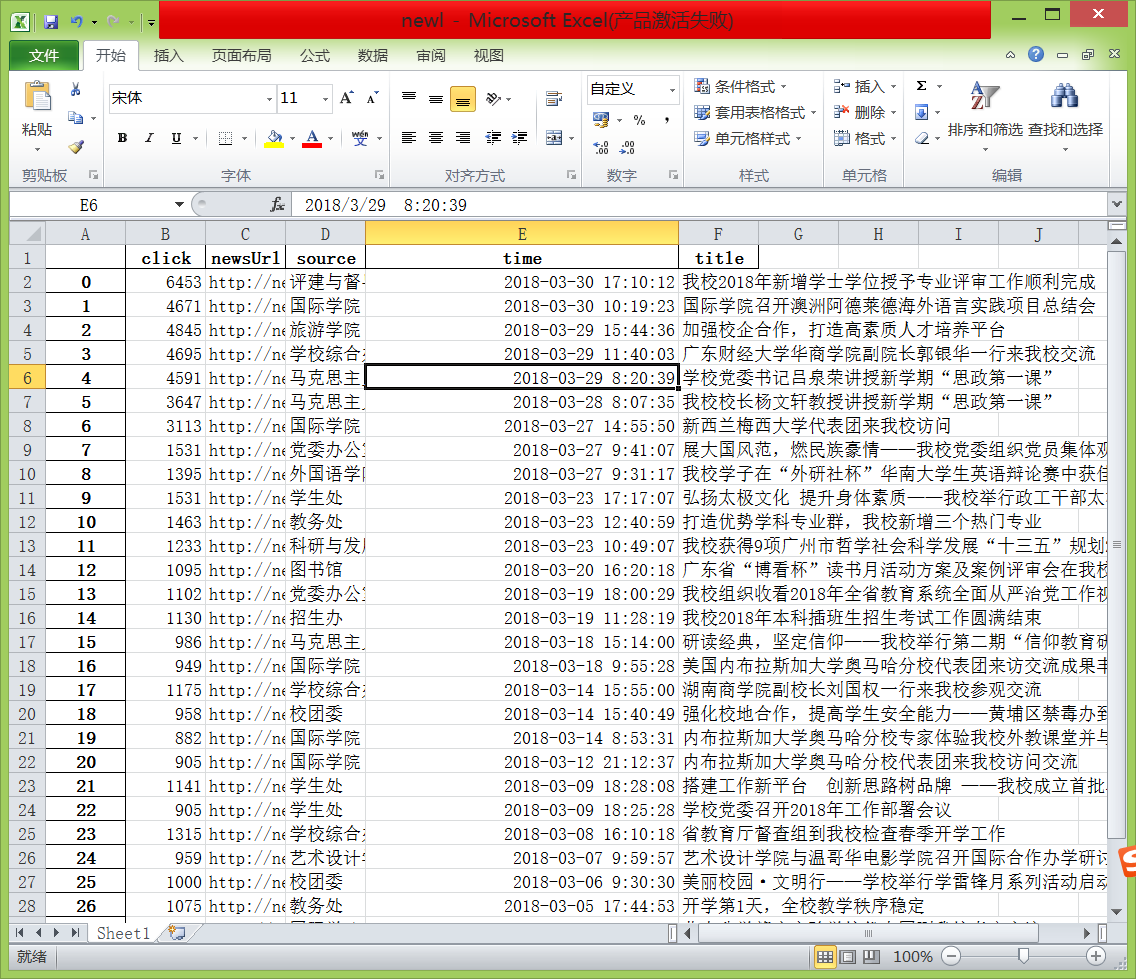
5. 用pandas提供的函数和方法进行数据分析:
- 提取包含点击次数、标题、来源的前6行数据
- 提取‘学校综合办’发布的,‘点击次数’超过3000的新闻。
- 提取'国际学院'和'学生工作处'发布的新闻。
- 进取2018年3月的新闻
print(df[['click','title','source']][:6])
print(df[(df['source']=='学校综合办')&(df['click']>3000)])
#使用isin筛选值
sou = ['国际学院','学生工作处']
df[df['source'].isin(sou)]
print(df[df['source'].isin(sou)])
df1 = df.set_index('dt')
print(df1['2018-03'])
6. 保存到sqlite3数据库
import sqlite3
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df3.to_sql('gzccnews05',con = db, if_exists='replace')
7. 从sqlite3读数据
with sqlite3.connect('gzccnewsdb.sqlite') as db:
df2 = pandas.read_sql_query('SELECT * FROM gzccnews05',con=db)
print(df2)
8. df保存到mysql数据库
安装SQLALchemy
安装PyMySQL
MySQL里创建数据库:create database gzccnews charset utf8;
import pymysql
from sqlalchemy import create_engine
conn=create_engine('mysql+pymysql://root:@localhost://3306/gzcc?charset=utf8')
pandas.io.sql.to_sql(df,'gzccnews',con=conn,if_exists='replace')
MySQL里查看已保存了数据。(通过MySQL Client或Navicate。)
select * from news