什么是进程??
程序就是一坨代码 而 进程就是正在运行的程序 。进程是对正在运行程序的一个抽象。是系统进行资源分配和调度的基本单位
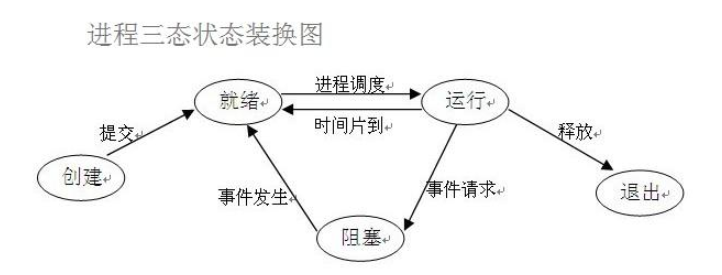
进程调度 时间片轮转法+多级反馈队列 进程三状态图
ps:程序不会立刻进入运行态 都会现在就绪态等待cpu的执行


时间片轮转(Round Robin,RR)法的基本思路是让每个进程在就绪队列中的等待时间与享受服务的时间成比例。在时间片轮转法中,需要将CPU的处理时间分成固定大小的时间片,例如,几十毫秒至几百毫秒。如果一个进程在被调度选中之后用完了系统规定的时间片,但又未完成要求的任务,则它自行释放自己所占有的CPU而排到就绪队列的末尾,等待下一次调度。同时,进程调度程序又去调度当前就绪队列中的第一个进程。 显然,轮转法只能用来调度分配一些可以抢占的资源。这些可以抢占的资源可以随时被剥夺,而且可以将它们再分配给别的进程。CPU是可抢占资源的一种。但打印机等资源是不可抢占的。由于作业调度是对除了CPU之外的所有系统硬件资源的分配,其中包含有不可抢占资源,所以作业调度不使用轮转法。 在轮转法中,时间片长度的选取非常重要。首先,时间片长度的选择会直接影响到系统的开销和响应时间。如果时间片长度过短,则调度程序抢占处理机的次数增多。这将使进程上下文切换次数也大大增加,从而加重系统开销。反过来,如果时间片长度选择过长,例如,一个时间片能保证就绪队列中所需执行时间最长的进程能执行完毕,则轮转法变成了先来先服务法。时间片长度的选择是根据系统对响应时间的要求和就绪队列中所允许最大的进程数来确定的。 在轮转法中,加入到就绪队列的进程有3种情况: 一种是分给它的时间片用完,但进程还未完成,回到就绪队列的末尾等待下次调度去继续执行。 另一种情况是分给该进程的时间片并未用完,只是因为请求I/O或由于进程的互斥与同步关系而被阻塞。当阻塞解除之后再回到就绪队列。 第三种情况就是新创建进程进入就绪队列。 如果对这些进程区别对待,给予不同的优先级和时间片从直观上看,可以进一步改善系统服务质量和效率。例如,我们可把就绪队列按照进程到达就绪队列的类型和进程被阻塞时的阻塞原因分成不同的就绪队列,每个队列按FCFS原则排列,各队列之间的进程享有不同的优先级,但同一队列内优先级相同。这样,当一个进程在执行完它的时间片之后,或从睡眠中被唤醒以及被创建之后,将进入不同的就绪队列。
多级反馈队列调度算法则不必事先知道各种进程所需的执行时间,而且还可以满足各种类型进程的需要,因而它是目前被公认的一种较好的进程调度算法。在采用多级反馈队列调度算法的系统中,调度算法的实施过程如下所述。 (1) 应设置多个就绪队列,并为各个队列赋予不同的优先级。第一个队列的优先级最高,第二个队列次之,其余各队列的优先权逐个降低。该算法赋予各个队列中进程执行时间片的大小也各不相同,在优先权愈高的队列中,为每个进程所规定的执行时间片就愈小。例如,第二个队列的时间片要比第一个队列的时间片长一倍,……,第i+1个队列的时间片要比第i个队列的时间片长一倍。 (2) 当一个新进程进入内存后,首先将它放入第一队列的末尾,按FCFS原则排队等待调度。当轮到该进程执行时,如它能在该时间片内完成,便可准备撤离系统;如果它在一个时间片结束时尚未完成,调度程序便将该进程转入第二队列的末尾,再同样地按FCFS原则等待调度执行;如果它在第二队列中运行一个时间片后仍未完成,再依次将它放入第三队列,……,如此下去,当一个长作业(进程)从第一队列依次降到第n队列后,在第n 队列便采取按时间片轮转的方式运行。 (3) 仅当第一队列空闲时,调度程序才调度第二队列中的进程运行;仅当第1~(i-1)队列均空时,才会调度第i队列中的进程运行。如果处理机正在第i队列中为某进程服务时,又有新进程进入优先权较高的队列(第1~(i-1)中的任何一个队列),则此时新进程将抢占正在运行进程的处理机,即由调度程序把正在运行的进程放回到第i队列的末尾,把处理机分配给新到的高优先权进程。
同步:任务提交之后 原地等待的任务的执行并拿到返回结果才走 期间不做任何事(程序层面的表现就是卡住了)
异步:任务提交之后 不再原地等待 而是继续执行下一行代码(结果是要的 但是是用过其他方式获取)
阻塞非阻塞:表示的程序的运行状态
阻塞:阻塞态
非阻塞:就绪态 运行态 强调:同步异步 阻塞非阻塞是两对概念 不能混为一谈
创建进程的两种方式
第一种
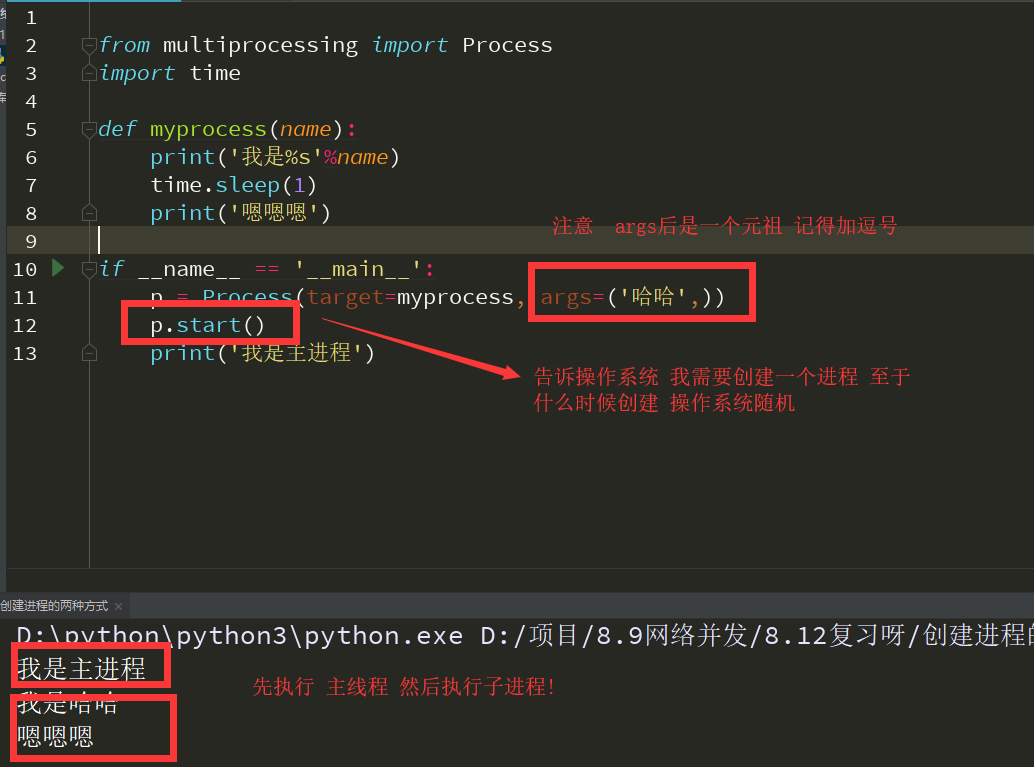
之所以用 if__name__ == '__main__': 的原因是 windows创建进程会将代码以模块的方式 从上往下执行一遍 linux会直接将代码完完整整的拷贝一份 (不加会报错)创建进程就是在内存中重新开辟一块内存空间
将允许产生的代码丢进去
一个进程对应在内存就是一块独立的内存空间
进程与进程之间数据是隔离的 无法直接交互
但是可以通过某些技术实现间接交互
第二种
join方法(主进程代码等待子进程运行结束 主进程等待某个指定的子进程运行结束,不影响其他子进程的运行)
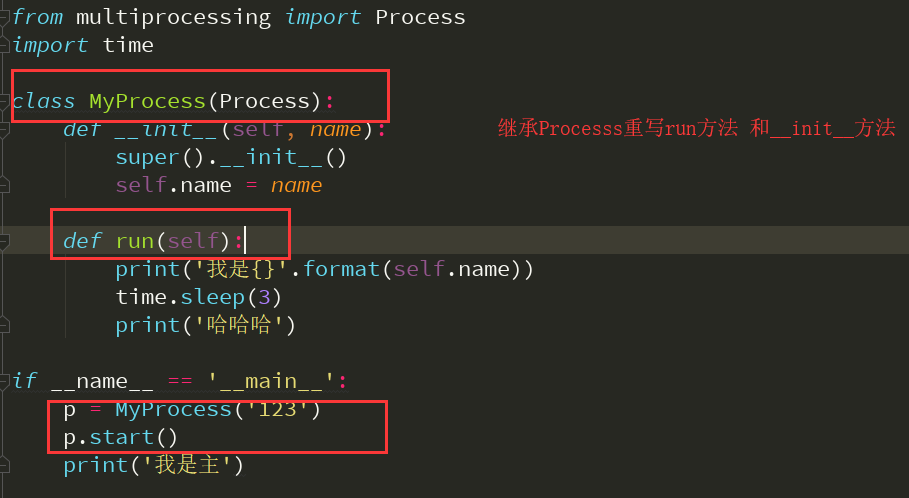
from multiprocessing import Process import time class MyProcess(Process): def __init__(self, name): super().__init__() self.name = name def run(self): print('我是{}'.format(self.name)) time.sleep(3) print('哈哈哈') if __name__ == '__main__': p = MyProcess('123') p1 = MyProcess('qwe') p.start() p1.start() p.join() p1.join() print('我是主')
进程对象以及其他方法
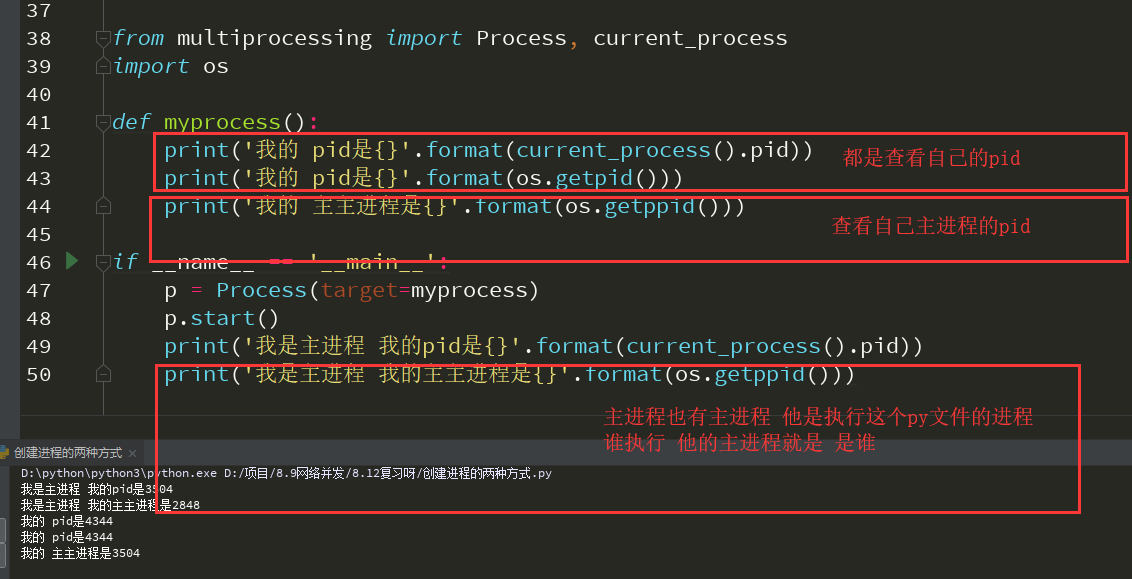
查看程序的pid值 可以在终端打印 tasklist 就可以看到所有的进程 还有他的 pid值

后面加 |findstr 加上进程的pid值 可以常看具体的 程序
在python中 可以使用 multiprocessing 里面的current_process 和os 模块中的 getpid 和 getppid 查看
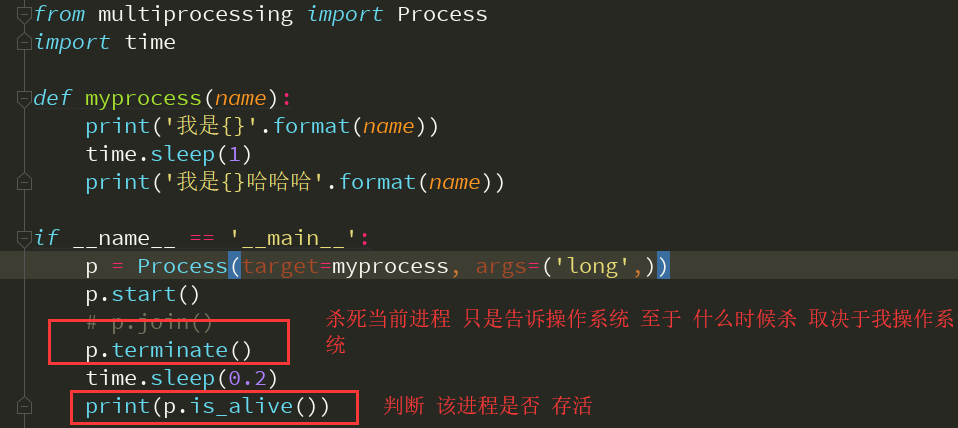
杀死进程 terminate 判断进程是否存活
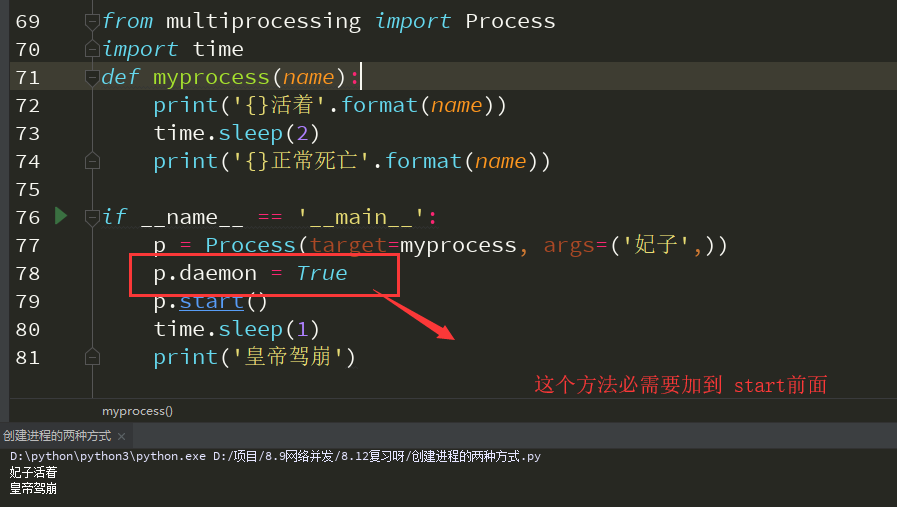
守护进程
就像古代的皇帝和妃子一样 妃子意外死亡 啥事都没有 但是 皇帝如果死了 不好意思 妃子一个都跑不了! 这里的 主进程就相当于 皇帝 子进程就相当于妃子
方法 daemon
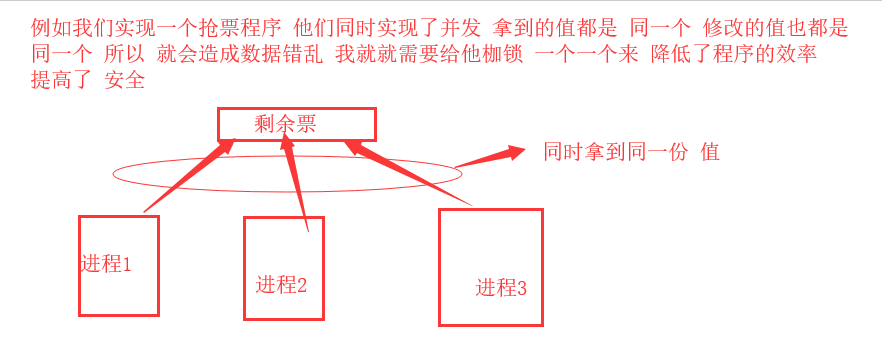
互斥锁
当多个进程操作同一份数据的时候 会造成数据的错乱
这个时候必须加锁处理
将并发变成串行
虽然降低了效率但是提高了数据的安全
注意:
1.锁不要轻易使用 容易造成死锁现象
2.只在处理数据的部分加锁 不要在全局加锁
锁必须在主进程中产生 交给子进程去使用
代码实现: 方法 Lock acquire release
from multiprocessing import Process, Lock import json import time def search(i): with open('json1','r', encoding='utf-8' )as f: dict_json = json.load(f) print('用户{} 查询 票 还有 {}'.format(i, dict_json['count'])) def buy(i): with open('json1', 'r', encoding='utf-8' )as f: dict_json = json.load(f) if dict_json.get('count') <= 0: print('票已近没有了') else: dict_json['count']-=1 print('购买成功') with open ('json1', 'w', encoding='utf-8' )as f: json.dump(dict_json, f) def run(i, mutex): search(i) mutex.acquire() (*****) buy(i) mutex.release() (*****) if __name__ == '__main__': mutex = Lock() for i in range(10): p = Process(target=run, args=(i,mutex)) p.start()
补充 僵尸进程和孤儿进程
僵尸进程 死掉的进程 所有的进程都会 变成僵尸进程
孤儿进程 子进程 没有死 父进程 死了
父进程回收资源的两种方式 join方法 和 父进程正常死亡
针对linux会有儿童福利院(init) 如果父进程意外死亡他所创建的子进程都会被福利院收养