摘自《孙卫琴Hibernate从入门到放弃》扫描第二版
一.简要Hibernate的检索方式
1.导航对象图检索方式
2.OID检索方式
3.HQL检索方式
4.QBC检索方式
5.本地SQL检索方式
HQL:的独白:
使用面向对象的HQL来检索对象,Hiberbate还提供了Query接口,他是专门的HQL
查询接口,能执行各种复杂的HQL查询语句,
回忆JDBC的方式检索数据的方式

来做一下简单的对比
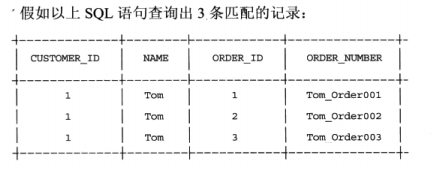
以下代码通过Hibernate提供的HQL检索方式,按照姓名检索匹配的Custoner对象及关联的Order对象

从种种迹象的判断可以看关键字.面向对象.映射文件.HQL转化为SQL查询语句.....dengdeng从而
得出结论,Hibernate封装了通过JDBC API查询数据库的细节
二 .解开HQL的神秘面纱
HQL(Hibernate Query Language)注意他和SQL查询有写类似
功能:
1).在查询语句中设定各种查询条件
2).支持投影查询,及检索出对象的部分属性
3).支持分页查询
4).支持连接查询
5).支持分组查询,允许使用having和group By关键字
6).提供内置聚合函数,如sum(),min()和max()
7).能够调用用户定义的SQL函数或者标准的SQL函数
8).支持子查询,及嵌入式查询
9).支持动态绑定参数
HQL中 from xxx where和select x from xx的区别
结果类型对比
一个是投影的是对象另一个是数据库检索字段
HQL语句使用规范
引用官方的一句话:通过HQL检索一个类的实体时如果查询语句的其他地方需要引用他,
应该为这个类(注意是这个类而不是数据表)指定一个别名列如
String hql="from Emp d order by d.empno";
as 关键字用于设定别名,亦可以将as关键字省了
String hql="from Emp as d order by d.empno";
但是官方建议我们在实际开发中建议使别名与类名相同
三.HQL使用案例(启用单元测试)
1.环境
ideat最体贴的软件,JDK8(注意使用hibernate的HQLJDK必须在7以上),对maven简单的了解(本次测试采用maven的方式使用jar包)
提供ideat的下载地址(可以下载zip版不用免安装版的)
http://www.jetbrains.com/idea/download/#section=windows
2.基本配置
01.这是我们这次测试的分层架构
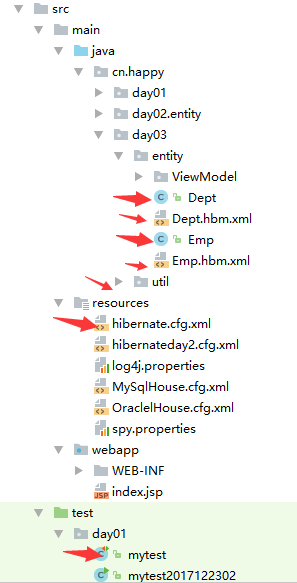
东西比较多见谅见谅
02.数据库(Oracle)提供测试数据‘
DEPT.sql
/* Navicat Oracle Data Transfer Oracle Client Version : 11.2.0.1.0 Source Server : happy Source Server Version : 110200 Source Host : localhost:1521 Source Schema : HAPPY Target Server Type : ORACLE Target Server Version : 110200 File Encoding : 65001 Date: 2017-12-27 13:02:56 */ -- ---------------------------- -- Table structure for DEPT -- ---------------------------- DROP TABLE "HAPPY"."DEPT"; CREATE TABLE "HAPPY"."DEPT" ( "DEPTNO" NUMBER(2) NOT NULL , "DNAME" VARCHAR2(14 BYTE) NULL , "LOC" VARCHAR2(13 BYTE) NULL ) LOGGING NOCOMPRESS NOCACHE ; -- ---------------------------- -- Records of DEPT -- ---------------------------- INSERT INTO "HAPPY"."DEPT" VALUES ('10', 'ACCOUNTING', 'NEW YORK'); INSERT INTO "HAPPY"."DEPT" VALUES ('20', 'RESEARCH', 'DALLAS'); INSERT INTO "HAPPY"."DEPT" VALUES ('30', 'SALES', 'CHICAGO'); INSERT INTO "HAPPY"."DEPT" VALUES ('40', 'OPERATIONS', 'BOSTON'); -- ---------------------------- -- Indexes structure for table DEPT -- ---------------------------- -- ---------------------------- -- Checks structure for table DEPT -- ---------------------------- ALTER TABLE "HAPPY"."DEPT" ADD CHECK ("DEPTNO" IS NOT NULL); -- ---------------------------- -- Primary Key structure for table DEPT -- ---------------------------- ALTER TABLE "HAPPY"."DEPT" ADD PRIMARY KEY ("DEPTNO");
EMP.sql
/* Navicat Oracle Data Transfer Oracle Client Version : 11.2.0.1.0 Source Server : happy Source Server Version : 110200 Source Host : localhost:1521 Source Schema : HAPPY Target Server Type : ORACLE Target Server Version : 110200 File Encoding : 65001 Date: 2017-12-27 13:03:12 */ -- ---------------------------- -- Table structure for EMP -- ---------------------------- DROP TABLE "HAPPY"."EMP"; CREATE TABLE "HAPPY"."EMP" ( "EMPNO" NUMBER(4) NOT NULL , "ENAME" VARCHAR2(10 BYTE) NULL , "JOB" VARCHAR2(9 BYTE) NULL , "MGR" NUMBER(4) NULL , "HIREDATE" DATE NULL , "SAL" NUMBER(7,2) NULL , "COMM" NUMBER(7,2) NULL , "DEPTNO" NUMBER(2) NULL ) LOGGING NOCOMPRESS NOCACHE ; -- ---------------------------- -- Records of EMP -- ---------------------------- INSERT INTO "HAPPY"."EMP" VALUES ('7369', 'SMITH', 'CLERK', '7902', TO_DATE('1980-12-17 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '1600', null, '20'); INSERT INTO "HAPPY"."EMP" VALUES ('7499', 'ALLEN', 'SALESMAN', '7698', TO_DATE('1981-02-20 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '2400', '300', '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7521', 'WARD', 'SALESMAN', '7698', TO_DATE('1981-02-22 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '2050', '500', '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7566', 'JONES', 'MANAGER', '7839', TO_DATE('1981-04-02 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '3775', null, '20'); INSERT INTO "HAPPY"."EMP" VALUES ('7654', 'MARTIN', 'SALESMAN', '7698', TO_DATE('1981-09-28 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '2050', '1400', '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7698', 'BLAKE', 'MANAGER', '7839', TO_DATE('1981-05-01 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '3650', null, '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7782', 'CLARK', 'MANAGER', '7839', TO_DATE('1981-06-09 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '3250', null, '10'); INSERT INTO "HAPPY"."EMP" VALUES ('7788', 'SCOTT', 'CLERK', '7566', TO_DATE('1987-04-19 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '3800', null, '20'); INSERT INTO "HAPPY"."EMP" VALUES ('7839', 'KING', 'PRESIDENT', null, TO_DATE('1981-11-17 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '5800', null, '10'); INSERT INTO "HAPPY"."EMP" VALUES ('7844', 'TURNER', 'SALESMAN', '7698', TO_DATE('1981-09-08 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '2300', '0', '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7876', 'ADAMS', 'CLERK', '7788', TO_DATE('1987-05-23 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '1900', null, '20'); INSERT INTO "HAPPY"."EMP" VALUES ('7900', 'JAMES', 'CLERK', '7698', TO_DATE('1981-12-03 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '1750', null, '30'); INSERT INTO "HAPPY"."EMP" VALUES ('7902', 'FORD', 'ANALYST', '7566', TO_DATE('1981-12-03 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '3800', null, '20'); INSERT INTO "HAPPY"."EMP" VALUES ('7934', 'MILLER', 'CLERK', '7782', TO_DATE('1982-01-23 00:00:00', 'YYYY-MM-DD HH24:MI:SS'), '2100', null, '10'); -- ---------------------------- -- Indexes structure for table EMP -- ---------------------------- -- ---------------------------- -- Checks structure for table EMP -- ---------------------------- ALTER TABLE "HAPPY"."EMP" ADD CHECK ("EMPNO" IS NOT NULL); -- ---------------------------- -- Primary Key structure for table EMP -- ---------------------------- ALTER TABLE "HAPPY"."EMP" ADD PRIMARY KEY ("EMPNO");
如果数据附加不上请参考百度,或者尝试删掉一些字段
03.Emp实体类(Emp)
@Entity @Table(name = "EMP") public class Emp { private Integer empno; private String ename; private String job; private Integer mgr;//经理 private Date hiredate; private Double sal; private Integer comm; private Integer deptno;
映射文件(Emp.hbm.xml)
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.happy.day03.entity"> <class name="Emp" table="Emp" schema="happy"> <id name="empno" column="empno"> <generator class="native"/> </id> <property name="ename"/> <property name="job"/> <property name="mgr"/> <property name="hiredate"/> <property name="sal"/> <property name="comm"/> <property name="deptno"/> </class> </hibernate-mapping>
Dept实体类(Dept)
public class Dept { private Integer deptno; private String dname; private String loc;
映射文件(Dept.hbm.xml)
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.happy.day03.entity"> <class name="Dept" table="Dept" schema="happy"> <id name="deptno" column="deptno"> <generator class="native"/> </id> <property name="dname"/> <property name="loc"/> </class> </hibernate-mapping>
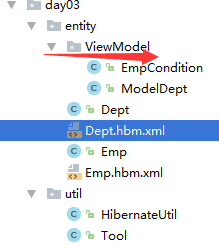
实体层开发完毕但是在entity这一层下面还有一层ViewModel是专门用来充当查询条件(参数)的
意思就是我们把用来查询的条件提炼为一个实体类
(ModelDept)类
public class ModelDept { private String dname; private String loc;
(EmpCondition)类
public class EmpCondition { //和UI紧耦合 雇佣日期 :范围 //job private String job; //salary private Double sal; //入职开始时间 private Date fromDate; //入职结束时间 private Date endDate;
看见没有这就是专业不要问为什么因为我会说(官网就是这么说的)
04.整个hibernate的核心配置(hibernate.cfg.xml)
<?xml version='1.0' encoding='utf-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <!----> <session-factory> <property name="connection.driver_class">com.p6spy.engine.spy.P6SpyDriver</property> <property name="connection.url">jdbc:p6spy:oracle:thin:@localhost:1521:orcl</property> <property name="connection.username">happy</property> <property name="connection.password">happy</property> <!--sql 方言--> <property name="dialect">org.hibernate.dialect.Oracle10gDialect</property> <!--连接池--> <!--<property name="connection.pool_size">1</property>--> <!--和当前线程绑定--> <property name="current_session_context_class">thread</property> <!--echo 打印控制台语句 shout--> <property name="show_sql">true</property> <!--格式化代码--> <property name="format_sql">true</property> <!--是否显示注释--> <property name="hibernate.use_sql_comments">true</property> <!--自动更新表结构 createe 先delete表结构 在创建 update直接更新表结构--> <property name="hbm2ddl.auto">update</property> <mapping resource="cn/happy/day01/entity/Dog.hbm.xml" /> <mapping resource="cn/happy/day01/entity/Student.hbm.xml" /> <mapping resource="cn/happy/day03/entity/Emp.hbm.xml" /> <mapping resource="cn/happy/day03/entity/Dept.hbm.xml" /> </session-factory> </hibernate-configuration>
这个xml旧有的说了
首先我们首次启用的p6spy的SQl监管工具(jar包版的)
所以连接的命令也就变了
方言用的是oracle10的
有过hibernate基础的都知道要想启用session.getCurrent()方法
就必须加上这行代码当然前提是单侧要是要和Spring整合的话thread变量就要换了
下面的都有注释不用解释了把
maven的jar包给一下吧
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <parent> <artifactId>Y2166</artifactId> <groupId>cn.happy</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>hibernate</artifactId> <packaging>war</packaging> <name>hibernate Maven Webapp</name> <url>http://maven.apache.org</url> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.3</version> <scope>test</scope> </dependency> <!--oracle jdbc--> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>11.2.0.1.0</version> </dependency> <!--hibernate核心jar--> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.0.6.Final</version> </dependency> <!--oracle 事务--> <dependency> <groupId>javax.transaction</groupId> <artifactId>jta</artifactId> <version>1.1</version> </dependency> <!--mysql数据库驱动--> <dependency> <groupId>org.wisdom-framework</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.34_1</version> </dependency> <!--SQL拦截/记录--> <dependency> <groupId>p6spy</groupId> <artifactId>p6spy</artifactId> <version>3.0.0</version> </dependency> </dependencies> <build> <resources> <resource> <directory>src/main/java</directory> <includes> <include>**/*.*</include> </includes> </resource> </resources> </build> </project>
特别的提到我们这测还是用了自己写的工具类
HibernateUtil
及日期转换的工具类(初学者的福利)
(HibernateUTil)
package cn.happy.day03.util; import org.hibernate.Session; import org.hibernate.SessionFactory; import org.hibernate.cfg.Configuration; /** * Created by CY on 2017/12/26. */ public class HibernateUtil { //线程变量 get set static ThreadLocal<Session> tl=new ThreadLocal<Session>(); //有SeesionFactory static Configuration cfg=null; static SessionFactory sessionFactory; static { cfg=new Configuration().configure("hibernateday2.cfg.xml"); sessionFactory=cfg.buildSessionFactory(); } //01.获取连接 public static Session getSession(){ //01.从线程变量中尝试获取 Session session = tl.get(); if(session==null){ //用户第一次获取连接,发现线程变量中没有session创建一个,并放入线程变量 session=sessionFactory.openSession(); tl.set(session); } return session; } //02.释放连接 public static void close(){ Session session = tl.get(); if(session!=null){ //线程变量set成null tl.set(null); session.close(); } } }
(Tool)
package cn.happy.day03.util; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; /** * Created by CY on 2017/12/26. */ public class Tool { public static Date setToData(String data) throws ParseException { SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd"); return sdf.parse(data); } }
在项目的test测试目录下我们邂逅的HQL
下面开始干------------------------------------------------------------------------------------------------------------------
1.首先我们回忆了一下上一节讲到的内容
使用HQL检索部分列(简称投影)
Hibernate封装了部分注解所以在单侧中使用了
Configuration cfg; SessionFactory factory; Session session; Transaction tx; @Before public void before(){ cfg=new Configuration().configure(); factory=cfg.buildSessionFactory(); session=factory.getCurrentSession(); tx=session.beginTransaction(); } @After public void after(){ tx.commit(); }
并不奇怪
//01 hql检索所有学生 @Test public void testselectAll(){ String str="from Student"; Query query = session.createQuery(str); List<Student> list = query.list(); for (Student item:list){ System.out.println(item.getSname()); } } //01 hql检索所有学生 @Test public void testseleectAllStudent(){ String str="from cn.happy.day01.entity.Student"; Query query = session.createQuery(str); List<Student> list = query.list(); for (Student item:list){ System.out.println(item.getSname()); } } //02hql获取单列的信息 @Test public void testSelectSomeRows(){ String str="from Student s where s.sname='小红'"; Query query = session.createQuery(str); List<Student> list = query.list(); for (Student item:list){ System.out.println(item.getSname()); } } // 03 hql获取部分列 @Test public void testgetmiuitClount(){ String str="select d.sname from Student d "; Query query = session.createQuery(str); List<String> list = query.list(); for (String item:list){ System.out.println(item); } } // 04 hql获取部分列 @Test public void testgetClounts(){ String str="select d.sname,d.sage from Student d "; Query query = session.createQuery(str); List<Object[]> list = query.list(); for (Object[] item:list){ for (Object it:item){ System.out.println(it); } } }
好了回忆到此结束以上内容充分的说明了结果不重要重要的是思想
:——>
分析如下:
在以上的HQL语句中使用诸如 select x from xx/from xx/ select x as x的语法
这些都在前面做了很好的铺垫接下来就是重点了:重点是提出除一个问题
我们什么时候用LIst<实体类>来接受session返回的数据什么时候用List<String>和List<Object[]>来接受session返回的数据?
答:
List<Bean>——>当我们使用了from 面向的是对象的时候也就是这样的HQL语句
String str="from Student";
得到时候需要这要接受注意这不是最终结果使用from 他返回的是
List list = query.list();
需要我们手动转换为强类的
List<Student> list = query.list();
List<String>----》
这种时候你看是使用了
String str="select d.sname from Student d ";
select 查询的数据字段而且是单列
List<String> list = query.list();
List<Object[]>----》
这个时候你看定时查询了多列不用说就是数组了
String str="select d.sname,d.sage from Student d ";
List<Object[]> list = query.list(); for (Object[] item:list){ for (Object it:item){ System.out.println(it); } }
06.下面介绍一种构造查寻的方法从此不用在考虑返回值了
//构造查询强类型的获取部分列 多列 List<强类型> @Test public void Strongtype(){ Session session; //language=CoffeeScript String hql="select new Dept(d.deptno,d.dname,d.loc) from Dept d"; session= HibernateUtil.getSession(); Query query = session.createQuery(hql); List<Dept> list = query.list(); for (Dept item:list){ System.out.println(item.getDname()); } }
分页:
//分页假象测试HibernateUtil工具类的关闭session方法是否起了作用 @Test public void selectRows(){ Session session=HibernateUtil.getSession(); String hql="from Emp as d order by d.empno"; Query query = session.createQuery(hql); int index=1; int size=3; query.setFetchSize((index-1)*size); query.setMaxResults(size); List<Emp> list = query.list(); ///session.close(); for (Emp item:list){ System.out.println(item.getEname()); } HibernateUtil.closeSession(); }
由于分页就是简单的两个参数setFetchSize和SetMaxResults所以就升级一下判断我们写的工具类关闭Session的方式是否起到了作用
结果接不打印了100%正确他会报一个session已经被关闭了的错
07.HQL升级(在HQL查询语句中绑定参数)
两种形式
1.按参数名称绑定
在查询语句中定义命名参数,命名参数以 ":"开头,形式如下啊
String hql=" from Dept d where d.dname=:dname";
以上HQL查询语句定义了一个命名参数 ''dname'接下来调用Query的setXXX()方法来绑定参数:
query.setParameter("dname","SALES");
Query提供了绑定各种类型的参数的方法,如果参数数字为字符串类类型,可调用
setString()方法,如果参数为整数类型,可以调用SetInteger()方法,依次类推,这些SetXXXX()
方法的第一个参数代表命名参数的名字,第二参数代表命名参数的值
加入有个不怀好意的用户在搜索中的姓名输入一下内容
Tom ' and SomeStoredProcedure() and 'hello'='hello
Hibernate会把以上字符转中的单引号解析为普通的字符,在HQL查询语句中用两个单引号表示
以下是例子
//参数化查询02 :name参数名称绑定 @Test public void t4(){ //部门名称为SALES的部门信息 //language=HQL String hql=" from Dept d where d.dname=:dname"; Query query = session.createQuery(hql); query.setParameter("dname","SALES"); List<Dept> list = query.list(); for (Dept item:list){ System.out.println(item.getDname()); } } //参数化查询03 @Test public void t5(){ //部门名称为SALES的部门信息 String hql="from Dept d where d.dname=:dname and d.loc=:loc"; Query query = session.createQuery(hql); ModelDept modelDept=new ModelDept(); //试图Model ViewModel 因为:ui层 modelDept.setDname("SALES"); modelDept.setLoc("CHICAGO"); query.setProperties(modelDept); List<Dept> list = query.list(); for (Dept item:list){ System.out.println(item.getDname()); } }
在实际开发中为了方便我们通常都是用setParameter()key/value形式的传参和setProperties()传入对象属性的形式来简化查询
按参数名称之动态查询StringBuilder拼接查询条件绑定对象属性实现补丁条件查询(Boss)
//动态查询04:方案三:name参数名称绑定++++对象属性 @Test public void t6() throws ParseException { EmpCondition empCondition=new EmpCondition(); //伪造界面Condition //试图mmodel empCondition.setJob("CLERK"); empCondition.setSal(1000.0); empCondition.setFromDate(Tool.setToData("1987-1-2")); empCondition.setEndDate(new Date()); //根据条件拼接SQl StringBuilder sb=new StringBuilder("from Emp e where 1=1 "); if(empCondition.getJob()!=null){ sb.append("and e.job =:job " ); } if(empCondition.getFromDate()!=null){ sb.append("and e.hiredate >=:fromDate " ); } if(empCondition.getEndDate()!=null){ sb.append("and e.hiredate <=:endDate " ); } Query query = session.createQuery(sb.toString()); query.setProperties(empCondition); List<Emp> list = query.list(); for (Emp item:list){ System.out.println(item.getEname()); } }
顺便科普一下StringBuffer和StringBuilder的区别带两个ff是线程安全的
String、StringBuffer、StringBuilder区别 StringBuffer、StringBuilder和String一样,也用来代表字符串。String类是不可变类,任何对String的改变都 会引发新的String对象的生成;StringBuffer则是可变类,任何对它所指代的字符串的改变都不会产生新的对象。既然可变和不可变都有了,为何还有一个StringBuilder呢?相信初期的你,在进行append时,一般都会选择StringBuffer吧! 先说一下集合的故事,HashTable是线程安全的,很多方法都是synchronized方法,而HashMap不是线程安全的,但其在单线程程序中的性能比HashTable要高。StringBuffer和StringBuilder类的区别也是如此,他们的原理和操作基本相同,区别在于StringBufferd支持并发操作,线性安全的,适 合多线程中使用。StringBuilder不支持并发操作,线性不安全的,不适合多线程中使用。新引入的StringBuilder类不是线程安全的,但其在单线程中的性能比StringBuffer高。 接下来,我直接贴上测试过程和结果的代码,一目了然: [java] view plain copy public class StringTest { public static String BASEINFO = "Mr.Y"; public static final int COUNT = 2000000; /** * 执行一项String赋值测试 */ public static void doStringTest() { String str = new String(BASEINFO); long starttime = System.currentTimeMillis(); for (int i = 0; i < COUNT / 100; i++) { str = str + "miss"; } long endtime = System.currentTimeMillis(); System.out.println((endtime - starttime) + " millis has costed when used String."); } /** * 执行一项StringBuffer赋值测试 */ public static void doStringBufferTest() { StringBuffer sb = new StringBuffer(BASEINFO); long starttime = System.currentTimeMillis(); for (int i = 0; i < COUNT; i++) { sb = sb.append("miss"); } long endtime = System.currentTimeMillis(); System.out.println((endtime - starttime) + " millis has costed when used StringBuffer."); } /** * 执行一项StringBuilder赋值测试 */ public static void doStringBuilderTest() { StringBuilder sb = new StringBuilder(BASEINFO); long starttime = System.currentTimeMillis(); for (int i = 0; i < COUNT; i++) { sb = sb.append("miss"); } long endtime = System.currentTimeMillis(); System.out.println((endtime - starttime) + " millis has costed when used StringBuilder."); } /** * 测试StringBuffer遍历赋值结果 * * @param mlist */ public static void doStringBufferListTest(List<String> mlist) { StringBuffer sb = new StringBuffer(); long starttime = System.currentTimeMillis(); for (String string : mlist) { sb.append(string); } long endtime = System.currentTimeMillis(); System.out.println(sb.toString() + "buffer cost:" + (endtime - starttime) + " millis"); } /** * 测试StringBuilder迭代赋值结果 * * @param mlist */ public static void doStringBuilderListTest(List<String> mlist) { StringBuilder sb = new StringBuilder(); long starttime = System.currentTimeMillis(); for (Iterator<String> iterator = mlist.iterator(); iterator.hasNext();) { sb.append(iterator.next()); } long endtime = System.currentTimeMillis(); System.out.println(sb.toString() + "builder cost:" + (endtime - starttime) + " millis"); } public static void main(String[] args) { doStringTest(); doStringBufferTest(); doStringBuilderTest(); List<String> list = new ArrayList<String>(); list.add(" I "); list.add(" like "); list.add(" BeiJing "); list.add(" tian "); list.add(" an "); list.add(" men "); list.add(" . "); doStringBufferListTest(list); doStringBuilderListTest(list); } } 看一下执行结果: 2711 millis has costed when used String. 211 millis has costed when used StringBuffer. 141 millis has costed when used StringBuilder. I like BeiJing tian an men . buffer cost:1 millis I like BeiJing tian an men . builder cost:0 millis 从上面的结果可以看出,不考虑多线程,采用String对象时(我把Count/100),执行时间比其他两个都要高,而采用StringBuffer对象和采用StringBuilder对象的差别也比较明显。由此可见,如果我们的程序是在单线程下运行,或者是不必考虑到线程同步问题,我们应该优先使用StringBuilder类;如果要保证线程安全,自然是StringBuffer。 从后面List的测试结果可以看出,除了对多线程的支持不一样外,这两个类的使用方式和结果几乎没有任何差别, StringBuffer常用方法 (由于StringBuffer和StringBuilder在使用上几乎一样,所以只写一个,以下部分内容网络各处收集,不再标注出处) StringBuffer s = new StringBuffer(); 这样初始化出的StringBuffer对象是一个空的对象, StringBuffer sb1=new StringBuffer(512); 分配了长度512字节的字符缓冲区。 StringBuffer sb2=new StringBuffer(“how are you?”) 创建带有内容的StringBuffer对象,在字符缓冲区中存放字符串“how are you?” a、append方法 public StringBuffer append(boolean b) 该方法的作用是追加内容到当前StringBuffer对象的末尾,类似于字符串的连接,调用该方法以后,StringBuffer对象的内容也发生改 变,例如: StringBuffer sb = new StringBuffer(“abc”); sb.append(true); 则对象sb的值将变成”abctrue” 使用该方法进行字符串的连接,将比String更加节约内容,经常应用于数据库SQL语句的连接。 b、deleteCharAt方法 public StringBuffer deleteCharAt(int index) 该方法的作用是删除指定位置的字符,然后将剩余的内容形成新的字符串。例如: StringBuffer sb = new StringBuffer(“KMing”); sb. deleteCharAt(1); 该代码的作用删除字符串对象sb中索引值为1的字符,也就是删除第二个字符,剩余的内容组成一个新的字符串。所以对象sb的值变 为”King”。 还存在一个功能类似的delete方法: public StringBuffer delete(int start,int end) 该方法的作用是删除指定区间以内的所有字符,包含start,不包含end索引值的区间。例如: StringBuffer sb = new StringBuffer(“TestString”); sb. delete (1,4); 该代码的作用是删除索引值1(包括)到索引值4(不包括)之间的所有字符,剩余的字符形成新的字符串。则对象sb的值是”TString”。 c、insert方法 public StringBuffer insert(int offset, boolean b), 该方法的作用是在StringBuffer对象中插入内容,然后形成新的字符串。例如: StringBuffer sb = new StringBuffer(“TestString”); sb.insert(4,false); 该示例代码的作用是在对象sb的索引值4的位置插入false值,形成新的字符串,则执行以后对象sb的值是”TestfalseString”。 d、reverse方法 public StringBuffer reverse() 该方法的作用是将StringBuffer对象中的内容反转,然后形成新的字符串。例如: StringBuffer sb = new StringBuffer(“abc”); sb.reverse(); 经过反转以后,对象sb中的内容将变为”cba”。 e、setCharAt方法 public void setCharAt(int index, char ch)该方法的作用是修改对象中索引值为index位置的字符为新的字符ch。例如: StringBuffer sb = new StringBuffer(“abc”); sb.setCharAt(1,’D’); 则对象sb的值将变成”aDc”。 f、trimToSize方法 public void trimToSize() 该方法的作用是将StringBuffer对象的中存储空间缩小到和字符串长度一样的长度,减少空间的浪费,和String的trim()是一样的作用,不在举例。 g、length方法 该方法的作用是获取字符串长度 ,不用再说了吧。 h、setlength方法 该方法的作用是设置字符串缓冲区大小。 StringBuffer sb=new StringBuffer(); sb.setlength(100); 如果用小于当前字符串长度的值调用setlength()方法,则新长度后面的字符将丢失。 i、sb.capacity方法 该方法的作用是获取字符串的容量。 StringBuffer sb=new StringBuffer(“string”); int i=sb.capacity(); j、ensureCapacity方法 该方法的作用是重新设置字符串容量的大小。 StringBuffer sb=new StringBuffer(); sb.ensureCapacity(32); //预先设置sb的容量为32 k、getChars方法 该方法的作用是将字符串的子字符串复制给数组。 getChars(int start,int end,char chars[],int charStart); StringBuffer sb = new StringBuffer("I love You"); int begin = 0; int end = 5; //注意ch字符数组的长度一定要大于等于begin到end之间字符的长度 //小于的话会报ArrayIndexOutOfBoundsException //如果大于的话,大于的字符会以空格补齐 char[] ch = new char[end-begin]; sb.getChars(begin, end, ch, 0); System.out.println(ch); 结果:I lov
2.按参数位置绑定
在HQL查询语句中用 "?"来定义参数的位置形式如下:
String hql=" from Dept d where d.dname=? ";
以上HQL查询语句定义了一个参数,第一个参数的位置为0接下来调用setXXXX()方法来绑定参数:
query.setParameter(0,"SALES");
--------------------------------------------------------------------------------------------------------------------
于是我们得出总结比较按名称绑定和按位置绑定这两中绑定参数的形式,按名称绑定的有下优势
1.使程序代码有较好的可读性
2.按名称绑定方式有利于程序代码的维护,而对于按位置绑定方式,如果参数在HQL
查询语句中的位置改变了,就必须修改绑定参数的代码,这消弱了程序代码的健壮个
维护性
3.按名字绑定方式允许一个参数在HQL查询语句中出现多次.