本文以爬取百度首页为示例来学习,python版本为python3.6.7,完整代码会在文章末附上
本次学习所用到的python框架:
urllib.request
本次学习所用到的函数: urllib.request.urlopen():发送http的get请求 .read():读取抓到的内容 .decode("utf-8"):将获取的betys格式数据转换为string格式数据
1.发送http的get请求使用的函数urllib.request.urlopen() ,其返回内容是所请求的url的网页源代码 可以将返回的内容赋给另外一个key
例如 response = urllib.request.urlopen(url)
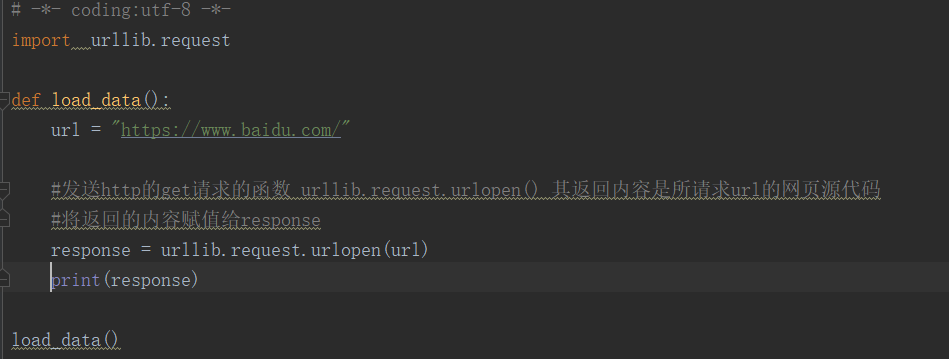
代码执行结果:

好像是存在内存里,这应该展示的是一个内存地址。
2.我们需要将内容读出来就用到了有一个函数.read()
data = response.read() `将response的内容读出来赋值给data
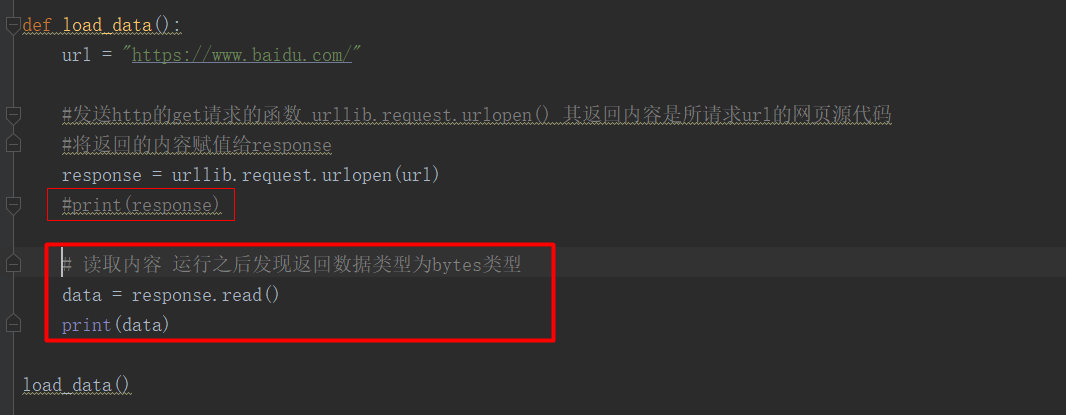
代码执行结果:获取的数据类型为bytes,没有可读性哈

3.需要进行转换将data转换成字符串类型,用到函数.decode("utf-8")
str_data = data.decode("utf-8")
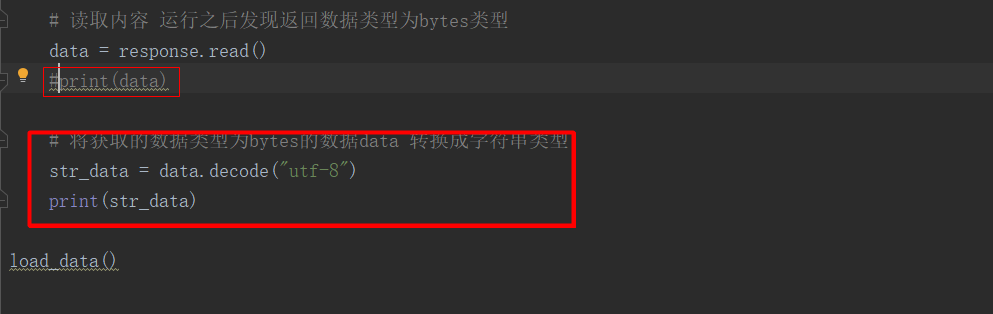
代码执行结果:【ps:将上面的https改为http】不截图了这里就能打印出url所对应的网页源代码了
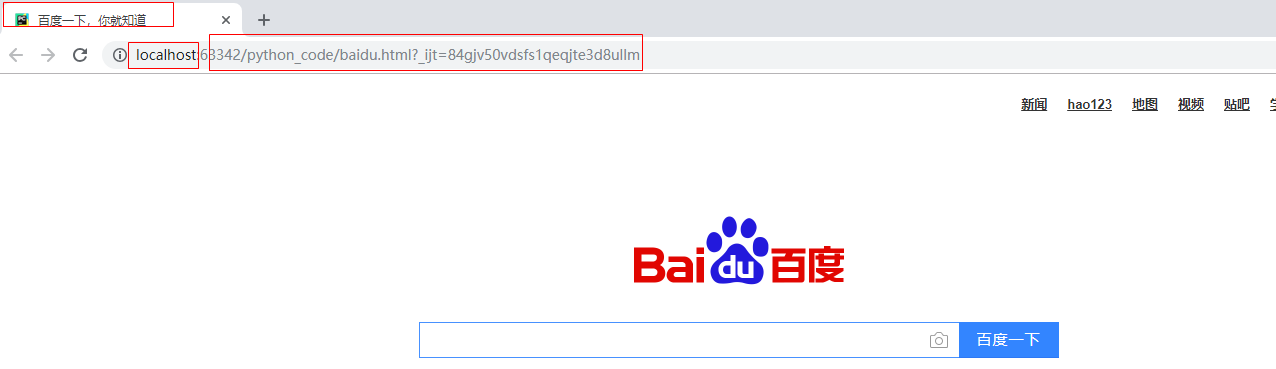
4.接下来是数据持久化的问题【固定格式记住就行了】

代码运行会生成一个baidu.html保存的是上面搜抓取的内容。
可以本地运行会[做运维的小年轻]打开一个浏览器页面:
5.那我们在爬虫的时候也会有需求,将字符串转换为你bytes格式,这就需要用到函数.encode

代码运行结果:

Python爬取到的数据类型一般有两种:str 、bytes
如果是爬取回来的是bytes类型,但是需要写入的是str类型用到的就是第4条的.decode(utf-8)
如果爬取回来的是str类型,但是需要写入的是bytes类型用到的就是第5条对的.encode(utf-8)
完整代码:
# -*- coding:utf-8 -*- import urllib.request def load_data(): url = "http://www.baidu.com/" #发送http的get请求的函数 urllib.request.urlopen() 其返回内容是所请求url的网页源代码 #将返回的内容赋值给response response = urllib.request.urlopen(url) #print(response) #读取内容 运行之后发现返回数据类型为bytes类型[做运维的小年轻] data = response.read() #print(data) # 将获取的数据类型为bytes的数据data 转换成字符串类型 str_data = data.decode("utf-8") #print(str_data) #数据持久化,即写入文件 with open("baidu.html","w",encoding="utf-8")as f: f.write(str_data) load_data()