1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小




![]()
源代码:
#加载图片
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt
china=load_sample_image("china.jpg") #获取一个图片
plt.imshow(china)
plt.show()
import sys
print("原图片文件大小为:",china.size)
print('原图片内存大小:',sys.getsizeof(china))
print('原图片数据结构:',china.shape)
image=china[::3,::3]#降低分辨率,每隔3个数取一个数据
x=image.reshape(-1,3)#线性化,列数为3
print(china.shape,image.shape,x.shape) #输出原图数据结构,降低后的数据结构及线性化后的数据结构
plt.imshow(china)
plt.show()
from sklearn.cluster import KMeans
import numpy as np
n_colors=64 #聚类,把颜色分为64类
model=KMeans(n_colors) #建模
label=model.fit_predict(x)#获取数据,一维数组,255*255*255个元素的类别
colors=model.cluster_centers_#划分聚类,把上面的元素归为64类颜色,二维(64,3)
new_image=colors[label].reshape(image.shape)#代替,用聚类后的64种颜色代替原来的颜色值,还原为二维。
plt.imshow(new_image.astype(np.uint8))#把颜色平均值转为整数
plt.show()#新图
print("压缩后图片文件大小为:",new_image.size)
print('压缩后图片内存大小:',sys.getsizeof(new_image))
print('压缩后图片数据结构:',new_image.shape)
import matplotlib.image as img
img.imsave('D:\图片\new_china.jpg',new_image.astype(np.uint8)) #保存新图片
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
数据:
|
表4-1天气与打球关联关系表 |
|||||
|
Day |
Outlook |
Temp |
Humidity |
Windy |
Play |
|
D1 |
Sunny |
Hot |
High |
Weak |
No |
|
D2 |
Sunny |
Hot |
High |
Strong |
No |
|
D3 |
Overcast |
Hot |
High |
Weak |
Yes |
|
D4 |
Rain |
Mild |
High |
Weak |
Yes |
|
D5 |
Rain |
Cool |
Normal |
Weak |
Yes |
|
D6 |
Rain |
Cool |
Normal |
Strong |
No |
|
D7 |
Overcast |
Cool |
Normal |
Strong |
Yes |
|
D8 |
Sunny |
Mild |
High |
Weak |
No |
|
D9 |
Sunny |
Cool |
Normal |
Weak |
Yes |
|
D10 |
Rain |
Mild |
Normal |
Weak |
Yes |
|
D11 |
Sunny |
Mild |
Normal |
Strong |
Yes |
|
D12 |
Overcast |
Mild |
High |
Strong |
Yes |
|
D13 |
Overcast |
Hot |
Normal |
Weak |
Yes |
|
D14 |
Rain |
Mild |
High |
Strong |
No |
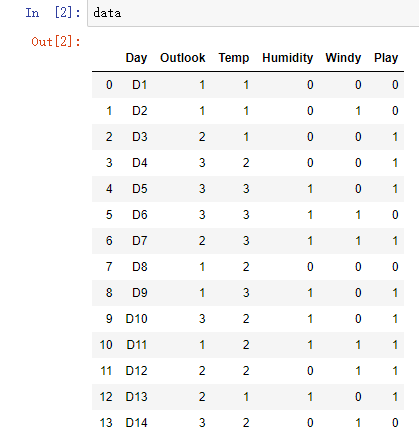

源代码
import pandas as pd
#读取数据并进行预处理,非数值型数据数据化
data=pd.read_csv("C:/Users/AAAA/PycharmProjects/untitled/data/data.csv")
data.loc[data['Outlook']=='Sunny','Outlook']=1
data.loc[data['Outlook']=='Overcast','Outlook']=2
data.loc[data['Outlook']=='Rain','Outlook']=3
data['Outlook']=data['Outlook'].astype('int')
data.loc[data['Temp']=='Hot','Temp']=1
data.loc[data['Temp']=='Mild','Temp']=2
data.loc[data['Temp']=='Cool','Temp']=3
data['Temp']=data['Temp'].astype('int')
data.loc[data['Humidity']=='High','Humidity']=0
data.loc[data['Humidity']=='Normal','Humidity']=1
data['Humidity']=data['Humidity'].astype('int')
data.loc[data['Windy']=='Weak','Windy']=0
data.loc[data['Windy']=='Strong','Windy']=1
data['Windy']=data['Windy'].astype('int')
data.loc[data['Play']=='No','Play']=0
data.loc[data['Play']=='Yes','Play']=1
data['Play']=data['Play'].astype('int')
from sklearn.cluster import KMeans
from sklearn.model_selection import train_test_split
X = data.iloc[:,1:5] #训练集
Y = data.iloc[:,5] #测试集
data_tr, data_te , label_tr ,label_te = train_test_split(X,Y, test_size=0.2,random_state=1) #割分
knn_model=KMeans(n_clusters=2) #分为2类
knn_model.fit(data_tr,label_tr) #训练模型
y_pre=knn_model.predict(data_te) #测试模型
print('被预测的数组:', data_te)
print('预测结果:', y_pre)