1.HTTP概况
Web的应用层协议是超文本传输协议(HTTP),它是Web的核心。
HTTP由两部分程序实现:一个客户机程序和一个服务器程序,它们运行在不同的端系统中,通过交换HTTP报文进行对话。HTTP定义了这些报文的格式以及客户机和服务器是如何进行报文交换的。下图是其基本思想:
当用户请求一个Web页面(如点击一个超链接)时,浏览器向服务器发出对该页面中所包含对象的HTTP请求报文,服务器接受请求并用包含这些对象的HTTP响应报文进行响应。

HTTP使用TCP(而不是UDP)作为它的支撑运输层协议。HTTP客户机发起一个与服务器的TCP连接,一旦连接建立,浏览器和服务器进程就可以通过套接字接口访问TCP。同时要注意到一点,HTTP服务器不保存关于客户机的任何信息,所以我们说HTTP是一个无状态协议。
2.非持久连接和持久连接
非持久连接:至多一个对象经过一个TCP连接发送。
持久连接:多个对象能够经过客户机和服务器之间的单个TCP连接发送。
HTTP既可以使用非持久连接,也可以使用持久连接,默认方式下HTTP使用持久连接。
·非持久连接
首先明确一个定义RTT(往返时延):从客户机到服务器发送一个小分组并返回所经历的时间。下面可以对响应时间建模:
(1)一个RTT发起TCP连接(2)对HTTP请求和返回的HTTP响应的一个RTT(3)文件传输时间
总计:2RTT + 传输时间

缺点:
(1)必须为每一个请求的对象建立和维护一个全新的连接。对每个这样的连接,在客户机和服务器都要分配TCP的缓冲区和变量,给服务器带来了严重负担。
(2)每一个对象的传输时延为两个RTT,即一个RTT用于建立TCP,另一个RTT用于请求和接收一个对象。
·持久连接
服务器在发送响应后保持该TCP连接打开。在相同的客户机与服务器之间的后续请求和响应报文可通过相同的连接进行传送。如果一个连接经过一定时间间隔(一个可配置的超时间隔)仍未被使用,HTTP服务器就关闭该连接。
持久连接还分为有无流水线两种。
无流水线的持久连接:仅当前面的响应已经收到,客户机发出新的请求。对每个引用对象一个RTT。
有流水线的持久连接:只要客户机遇到一个引用对象,它就发送请求。对于所有引用的对象花费一个RTT时间。
3.HTTP报文格式
·HTTP请求报文
首先来看一下HTTP请求报文的ASCII格式:

下面是请求报文的通用格式:
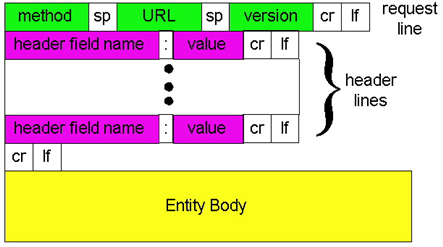
可以看到两者是密切相关的,在首部行(和附加的回车换行符cr、lf)后有一个“实体主体”(Entity Body)。
使用GET方法时实体主体为空,而使用POST方法时,用户仍可以向服务器请求一个Web页面,但Web页面的特定内容依赖用户在表单字段中输入的内容。当方法字段的值为POST时,实体主体中包含的就是用户在表单字段中输入的值。
注:用表单生成的请求报文不需要使用POST方法,HTML表单经常使用GET方法,将输入数据(在表单字段中)传送到正确的URL。
HEAD方法类似于GET方法。当服务器收到使用的HEAD方法的请求时,会用一个HTTP报文进行响应,但是并不返回请求对象。---可用于故障跟踪。
PUT方法也被应用程序用来向Web服务器上传对象。
运用DELETE方法,用户或者应用程序可以删除Web服务器上的对象。
·HTTP响应报文

下面来看一下常用的HTTP响应状态码:
200 OK
请求成功,请求的对象在这个报文后面
301 Moved Permanently
请求的对象已转移,新的URL在响应报文的Location:首部行中指定
400 Bad Request
请求报文不为服务器理解
404 Not Found
请求的文档没有在该服务器上发现
505 HTTP Version Not Supported
服务器不支持请求报文使用的HTTP协议版本
4.用户与服务器的交互:cookie
前面提到了HTTP是无状态的,这简化了服务器的设计。然而一个Web站点通常希望能够识别用户,既可能是因为服务器想限制用户的访问,又可能是因为它想把内容和用户身份联系起来。为此,HTTP使用了cookie。
cookie由四个部分组成:
1)在HTTP响应报文中的cookie 首部行
2)在HTTP请求报文中的cookie 首部行
3)保持在用户主机中的 cookie 文件并由用户浏览器管理
4)位于Web站点的后端数据库
总结:cookie可以标识用户。用户首次访问站点时,可能需要提供一个用户标识(可能是名字)。在后继访问中,浏览器向服务器传递一个cookie首部,供服务器识别该用户。因此,cookie可以在无状态的HTTP上建立一个用户会话层。
5.Web缓存(代理服务器)
假设浏览器正在请求对象:http://www.someschool.edu/campus.gif,则会发生如下情况:
(1)浏览器建立一个到Web缓存器的TCP连接,并向Web缓存器中的对象发送一个HTTP请求。
(2)Web缓存器检查本地是否存储了该对象拷贝,如果有,Web缓存器就用HTTP响应报文向客户机浏览器返回该对象。(客户机2)
(3)如果Web缓存器没有该对象,它就与该对象的初始服务器(如www.someschool.edu)打开一个TCP连接。Web缓存器则在该TCP连接上发送获取该对象的HTTP请求。收到该请求后,初始服务器向Web缓存器发送具有该对象的HTTP响应。
(4)当Web缓存器接收该对象时,它在本地存储空间存储了一份拷贝,并用HTTP响应报文向客户机的浏览器发送该拷贝(通过已经建立在客户机浏览器和Web缓存器之间的TCP连接)。
因此,Web缓存器(代理服务器)既是服务器又是客户机。缓存器通常由ISP(大学,公司和住宅ISP)安装。

使用Web缓存器的好处:
·减小客户机请求的响应时间
·减小机构访问链路的流量
·因特网密集安装缓存使得内容提供商能有效地交付内容(对P2P文件共享也是这样)
下面是一个Web缓存的例子:
该图显示了两个网络,即机构内部网络和公共因特网的一部分。机构内部网络是一个高速局域网。



6.条件GET方法
尽管高速缓存能减少用户感受到的响应时间。但也引入了一个新问题,即存放在缓存器中的对象拷贝可能是陈旧的。因此HTTP有一种机制,允许缓存器证明它的对象是最新的,这种机制就是条件GET方法。
目的:如果缓存中有最新缓存版本,就不发送该对象。
缓存器: 在HTTP请求If-modified-since: <date>中,指定缓存版本的日期。
服务器:如果缓存的拷贝是最新的,响应不包含对象: HTTP/1.0 304 Not Modified,否则将最新的对象发送给缓存器。
