MySQL是一种关系型数据库
mysql是属于Oracle旗下的一款数据库产品。
分为商业版和社区版
MySQL数据库是一种C/S(客户端/服务器)模型的服务 B/S(浏览器/服务器)
MySQL的网络通信模型为:NIO+连接池来实现,支持高并发的应用场景
实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,不如说“老师与学校的关系”。
属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
元组:表中的一行就是一个元组。
分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫 候选码,我们从候选码中挑一个出来做老大,它就叫主码。
全码:如果一个码包含了所有的属性,这个码就是全码。
主属性(主键):一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性(非主键属性):与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
外码(外键):一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
数据库范式的好处:
1、减少数据冗余
2、消除异常
2、让数据组织更加合理
成绩表(学生ID、课程ID、学生姓名、学生年龄、成绩)
列是基本的数据行,不能进行拆分
如果不满足1NF,则拆分成一对多的实体关系
注意:不符合第一范式不能称之为关系型数据库
eg:1 张三 18 陕西省西安市西安工业大学7公寓
陕西省西安市未央区西安工业大学7公寓 陕西省西安市未央区草滩街道办西安工业大学
拆分后:
学生表:(学生ID、姓名、年龄、地址ID)
地址表:(地址ID、省、市、区、街道办)
非主属性完全依赖于主关键字,如果不是依赖于主键,应该拆分成新的主体,
设计成一对多的关系
联合主键(学生ID、课程ID)
学生姓名 ->学生ID 部分依赖
学生年龄 ->学生ID 部分依赖
课程名称 ->课程ID 部分依赖
课程成绩 ->学生ID、课程ID 完全依赖
学生表(学生ID、学生姓名、学生年龄) ->主键:学生ID
课程表(课程ID、课程名称) ->主键:课程ID
学生成绩表(学生ID、课程ID、课程成绩) ->主键:学生ID、课程ID
3、第三范式(3NF):在2NF基础上,属性不依赖于其他非主属性(消除传递依赖)
主键:学生ID
学生姓名 ->学生ID
学院名称 ->学生ID
学院电话 ->学院 ->学生ID
学生表(学生ID、学生姓名、学院ID) 主键:学生ID
学院表(学院ID、学院名称、学院电话、学院地址) 主键:学院ID
1、查询操作会连接多个表,增加了查询的福在读
2、查询操作需要连接多个表,降低了查询的性能
创建用户: create user '用户名 '@' 主机名' identified by ' 密码 ' ;
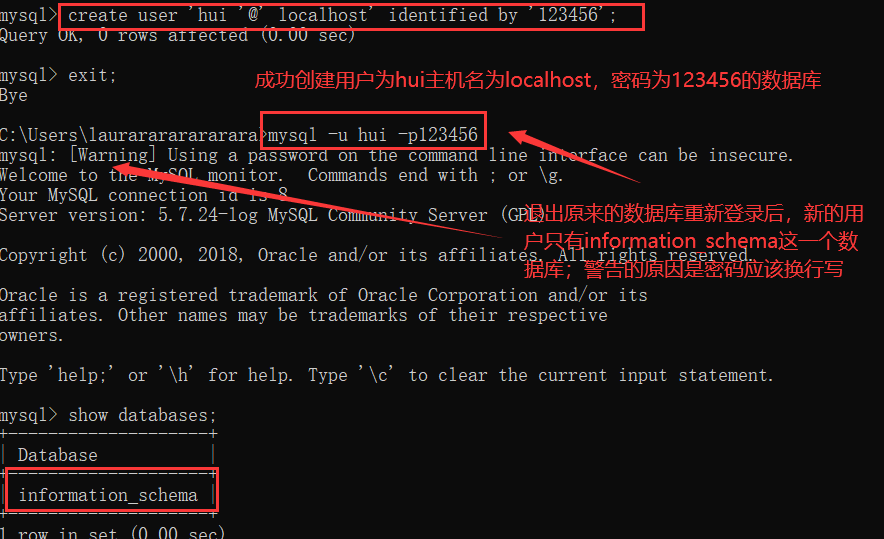
在默认的用户root中选取mysql数据库查找user表可以查看已经创建的用户:首先 use mysql; select * from user;
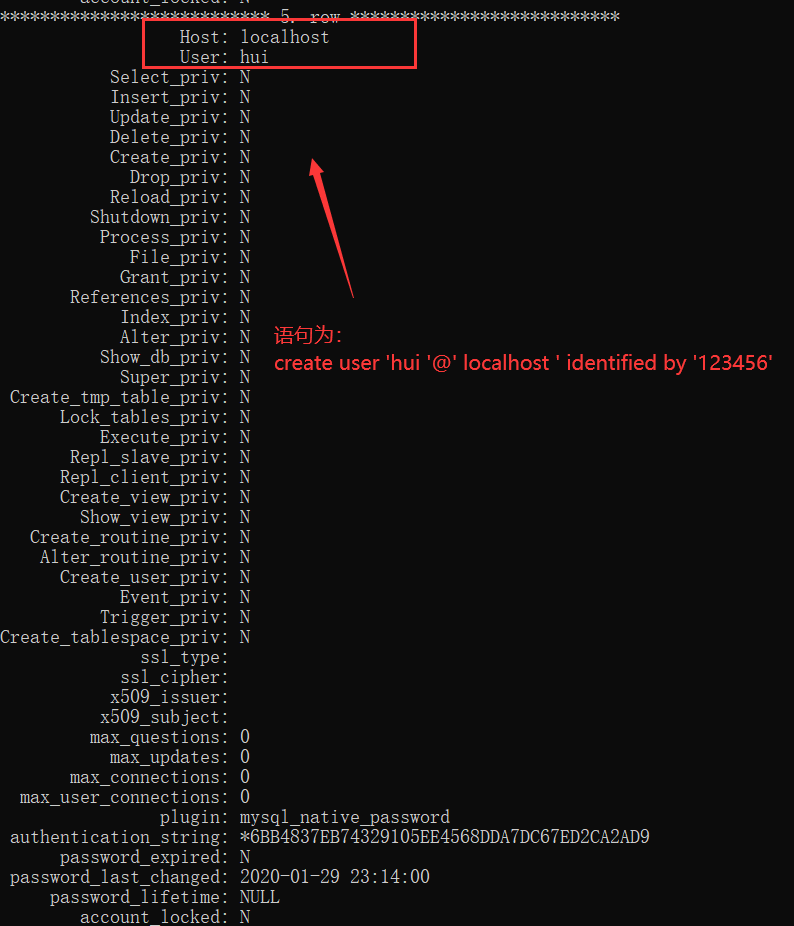
删除用户:drop user '用户名 '@' 主机名';
修改数据库密码:要在mysql数据库里面修改;首先选取该数据库:use mysql;
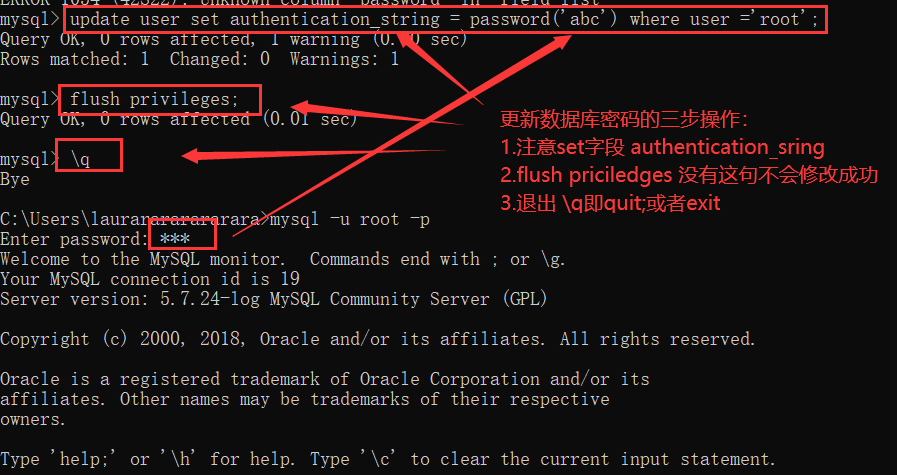
忘记密码怎么办?
1.cmd -> net stop mysql 停止mysql服务(管理员身份)
2.使用无验证方式启动mysql 服务:mysqld --skil-grant-tables(再cmd打开一个普通窗口直接输入mysql即可进入)
3.再use mysql数据库,用update语句改密码;
4关闭两个窗口,在任务管理器中结束mysqld-exe 服务。
5.管理员 cmd页面启动服务器net start mysql 并输入新的mysql -uroot -p+密码
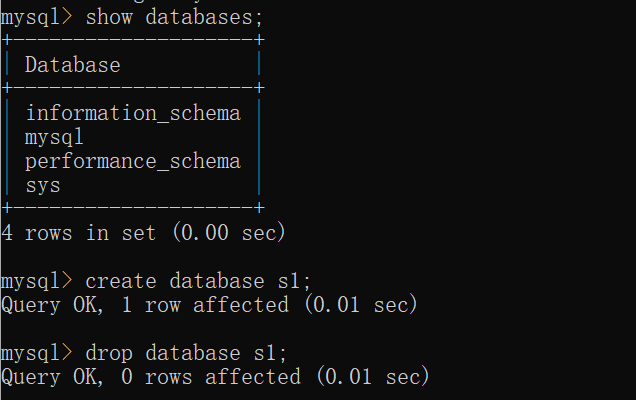
查看所有的库: show databases;
创建数据库的SQL:create database database_name;
删除数据的SQL:drop database database_name;
选择数据库的SQL:use database_name;
展示当前库下的所有的表SQL:show tables;
三:表相关的操作
1、创建表
create table table_name
属性名 数据类型[完整性约束],
属性名 数据类型[完整性约束],
属性名 数据类型[完整性约束]
)
注意:在数据库创建的时候要选取合适的数据类型,而且还要添加完整性约束
完整性约束条件有:
-------------------------------------
约束条件 | 说明
-------------------------------------
primary key | 修饰的属性是该表的主键
-------------------------------------
foreign key | 修饰的数据是该表的外键
-------------------------------------
not null |表示该字段不能为null
-------------------------------------
unique |修饰的属性值是唯一的
-------------------------------------
auto_increment |mysql的特色,表示该属性是自增的
-------------------------------------
default | 设置属性默认值
-------------------------------------
2.1.1、 desc table_name;
用desc可以查看表的字段名称(Fileld)、类型(Type)、是否为空(Null)、约束条件(Key)、默认值(Default)、备注信息(Extra)

show create table可以打印创建的表的SQL,
并且显示该表的存储引擎和字符集编码(截图不方便,这样显示)
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| t2 | CREATE TABLE `t2` (
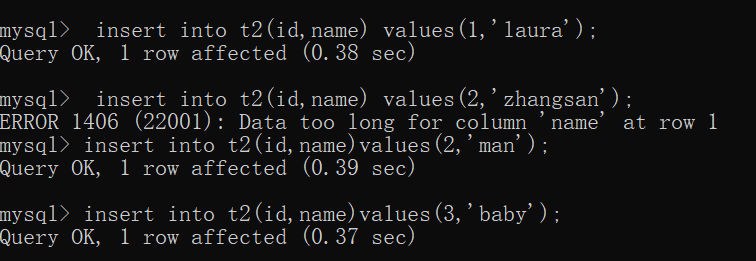
`id` int(11) NOT NULL,
`name` varchar(6) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
在使用的过程中不满足使用情况时,进行修改
3.1.1 修改表名SQL
alter table old_table_name rename [to] new_table_name;

3.1.2、修改表中字段类型SQL:
alter table table_name modify 属性名 数据类型;
eg:alter table t1 modify id bigint;

3.1.3、修改表中属性名SQL:
alter table table_name change 旧属性名 新属性名 新数据类型;
eg:alter table t1 change id idd int;

3.1.4、增加新的字段SQL:
alter table table_name add 属性名 数据类型 [完整性约束] [first|after 属性名2]
eg:alter table t1 add age int;
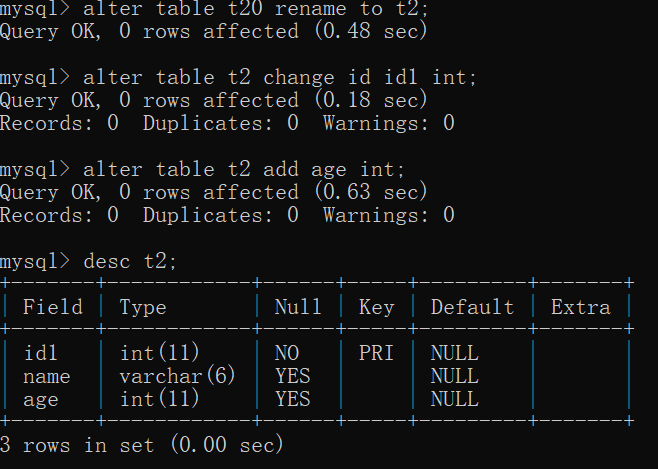
显示该表的存储引擎和字符集编码
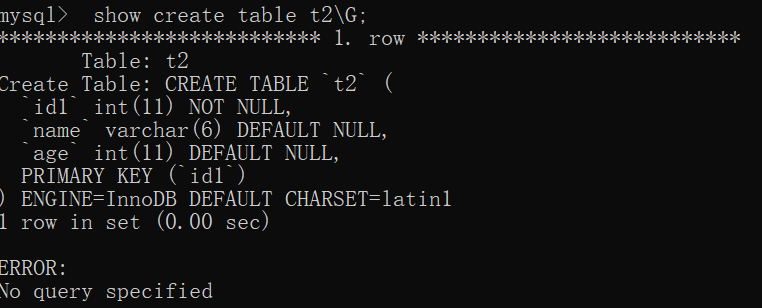
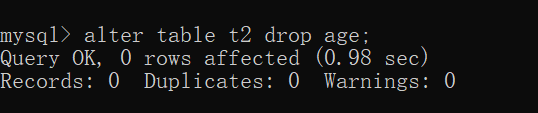
alter table table_name drop 属性名;
eg:alter table t1 drop age2;
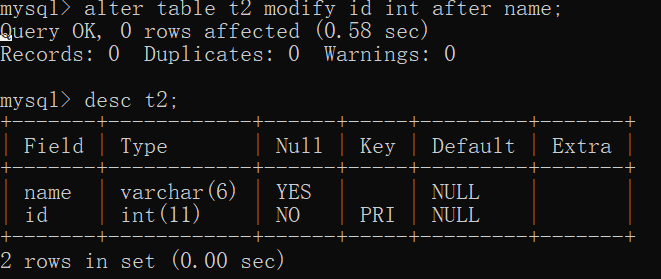
3.1.6、修改属性的排列顺序SQL:
alter table table_name modify 属性名1 数据类型 first | after 属性名2;
4. 查询表SQL
SQL基本的结构如下:
select 属性列表 from table_name [where 条件表达式1]
[group by 属性1 [having 条件表达式2]]
[order by 属性2 [asc | desc]]
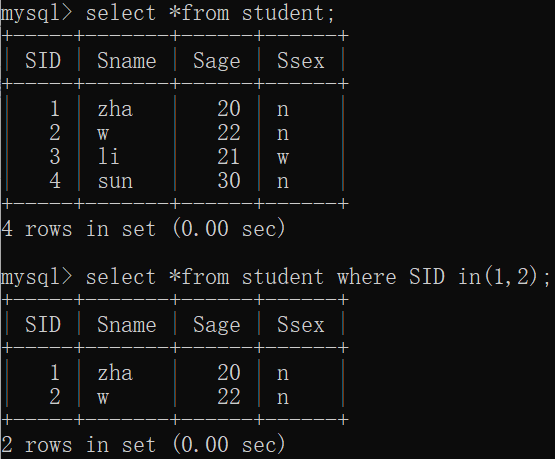
[not] in(元素1,元素2...元素n)
eg:select * from Student where SID in (1,3,5);
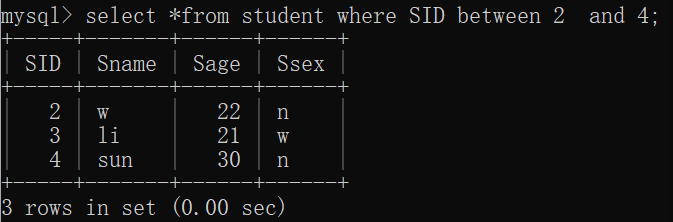
[not] between 取值1 and 取值2
eg:select * from Student where SID between 3 and 7;
[not] like 'abc';
注意:like可以结合通配符使用
%:表示0个或者是任意长度的字符串
_:只能表示单个字符
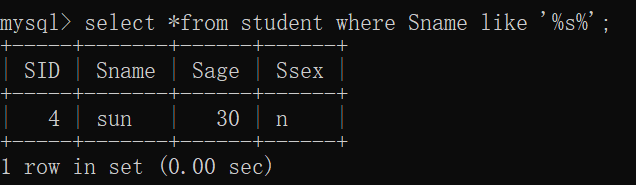
4.4 空值查询
is [not] null;
eg:select * from Student where Sage is not null;

条件表达式1 and 条件表达式2 [and ...条件表达式n]
eg:select * from Student where Ssex ='nan' and Sage=20;

条件表达式1 or 条件表达式2 [or ...条件表达式n]
select distinct 属性名
eg:select distinct Sage from Student;
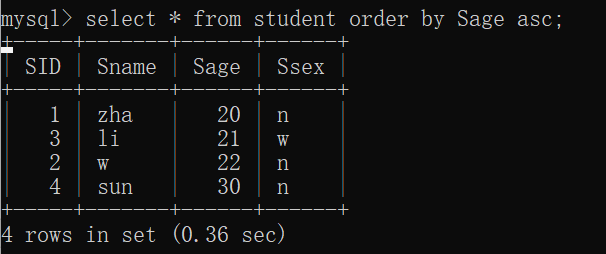
order by 属性名 [asc| desc];
asc:升序(默认是升序) desc:降序
eg:select * from Student order by SID asc;
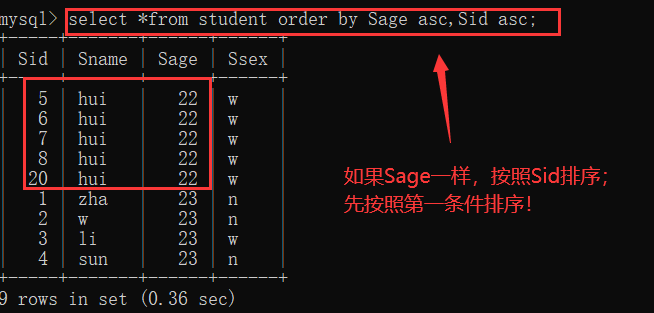
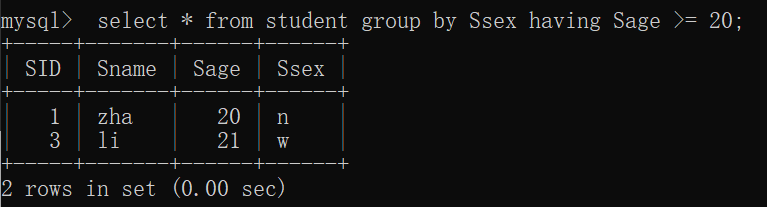
group by 属性名[having 条件表达式]
eg:select * from Student group by Ssex having Sage >= 18;
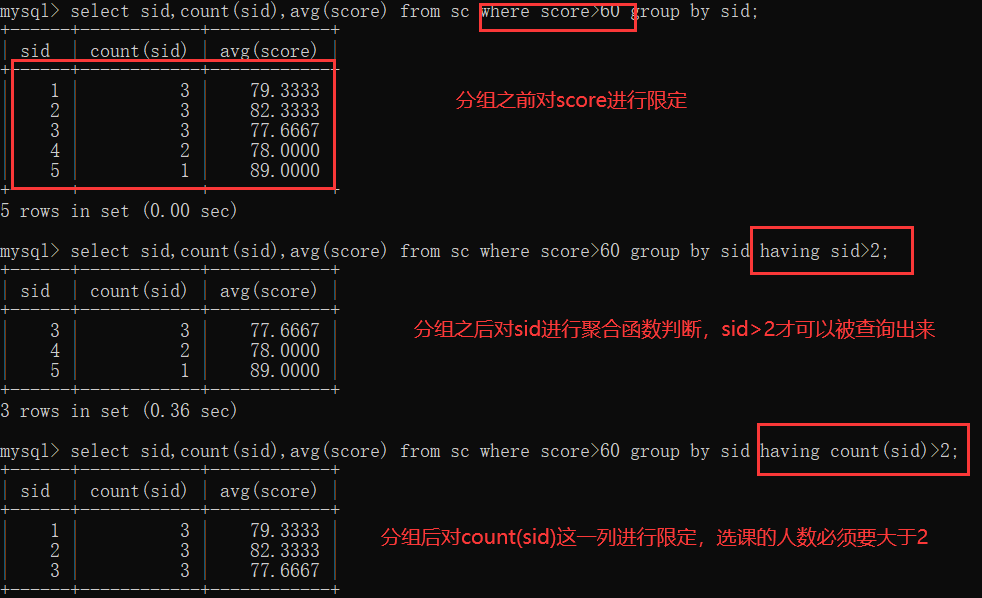
5.0 聚合函数:将某一列数据作为一个整体,进行纵行计算。(count. max. min.sum.avg)
注:聚合函数的计算,排除null值 解决方案:1.选择不包含非空值的列(选择主键,*(不推荐)) 2.IFNULL函数
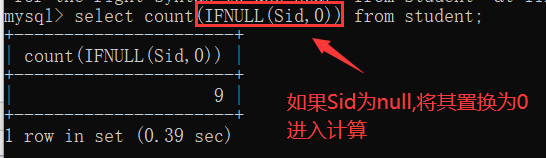
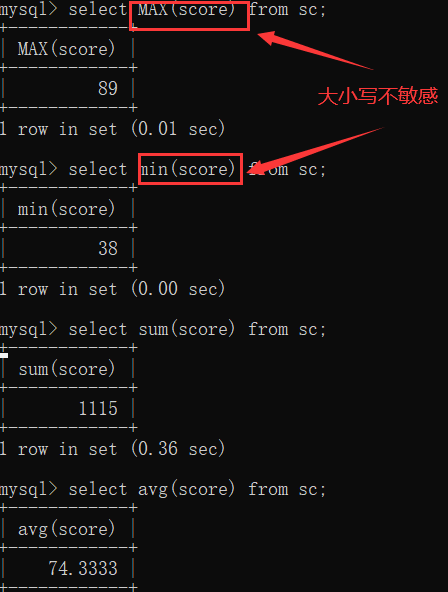
5.1 分组查询group by
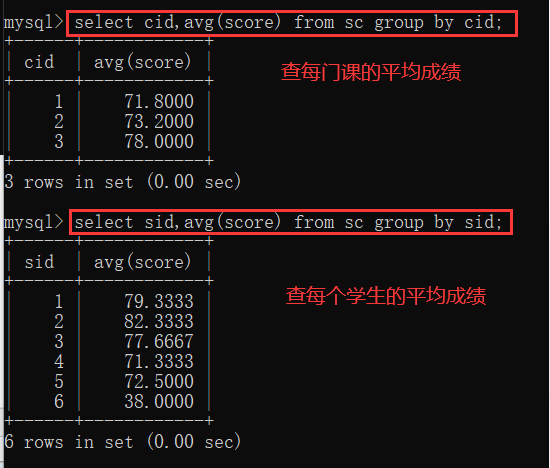
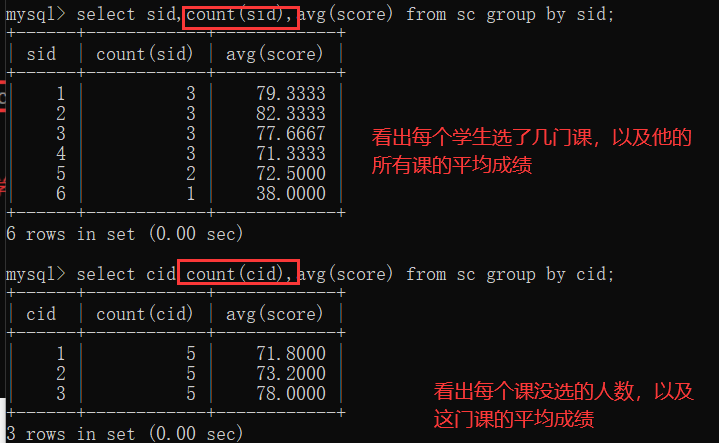
分组之前可对条件进行一些限定操作:成绩不及格的不参与分组:where操作限定;新要求:分组之后,每门课的选课人数要大于两个人 having操作对分组之后的表进行限定操作;
注:where 和having 的区别
1.where在分组之前进行限定,不满足结果,不会参与分组;having在分组之后进行限定,如果不满足条件,不会被查询出来
2.where后不可以跟聚合函数,having可以进行聚合函数的判断
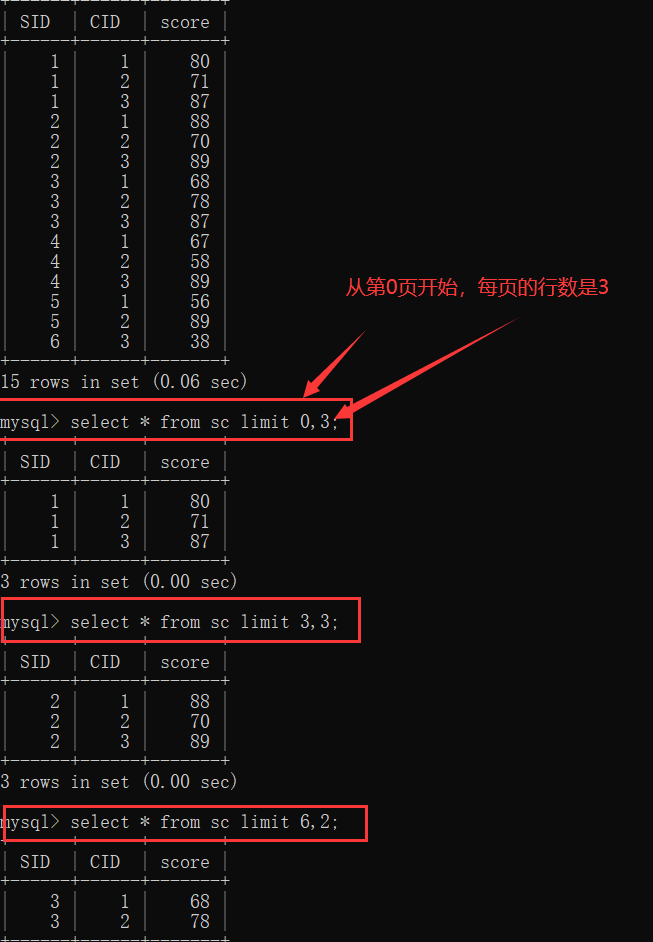
5.2分页查询limit