如果数据被过度拟合,导致方差过大,那么就可以用正则化:

L2正则化(最常用的方法): 在之前的成本函数 J=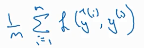 后面加上
后面加上 拉姆他是个参数,是人为定义的。m是训练样本数量,
拉姆他是个参数,是人为定义的。m是训练样本数量, 是权重矩阵w的所有元素的平方和。L是神经网络的层数,因为每层都有一个w矩阵,所以一共有L个W矩阵。
是权重矩阵w的所有元素的平方和。L是神经网络的层数,因为每层都有一个w矩阵,所以一共有L个W矩阵。
 正则化后的dw变为左图这个,左图的紫色部分是由于加入正则化多出来的部分。
正则化后的dw变为左图这个,左图的紫色部分是由于加入正则化多出来的部分。 更新后的W定义如左图。
更新后的W定义如左图。
Dropout正则化:

设置一定的概率随机去掉一部分结点。只要令某个结点与上层结点连接的权值w全为0即可实现“去掉”这个结点。

上图为“Inverted drorpout”的一个例子,神经网络是三层的,想要去掉20%的节点,实现方法:构造一个d3矩阵,
这个式子就会使d3里面80%是1,20%是0,然后让d3与a3相乘,得到了新的、20%为0的a3。然后让 a3/=0.8,这一步的原因是因为 ,由于20%的a3变为了0,所以Z4的期望值就会降低,为了不影响Z4,就让a3/0.8,从而增大Z4,不影响Z4的期望值。前述的例子是针对某一层的,对于不同层,keep-prob会不同
,由于20%的a3变为了0,所以Z4的期望值就会降低,为了不影响Z4,就让a3/0.8,从而增大Z4,不影响Z4的期望值。前述的例子是针对某一层的,对于不同层,keep-prob会不同
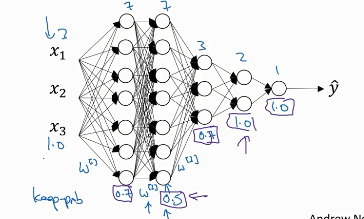 第一层是0.7,第二层0.5,第三层0.7,后面的全是1
第一层是0.7,第二层0.5,第三层0.7,后面的全是1
其他的正则化方法:
1.扩增数据 方法:将图片进行翻转、裁剪旋转等,扩大数据量,减小方差。
2.Early stopping 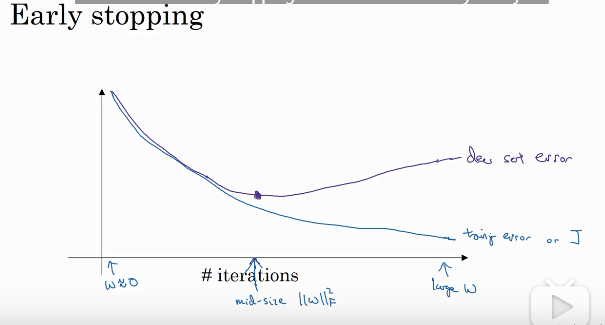
该方法就是提前结束训练。因为通常损失函数会先减小再增加再减小,在训练的过程中拟合程度逐步增大,如果选择在一个局部较小的损失函数的时候就结束训练的话,那么拟合程度就不会太大,同时偏差也不会太大。