官网上的速度测试报告:
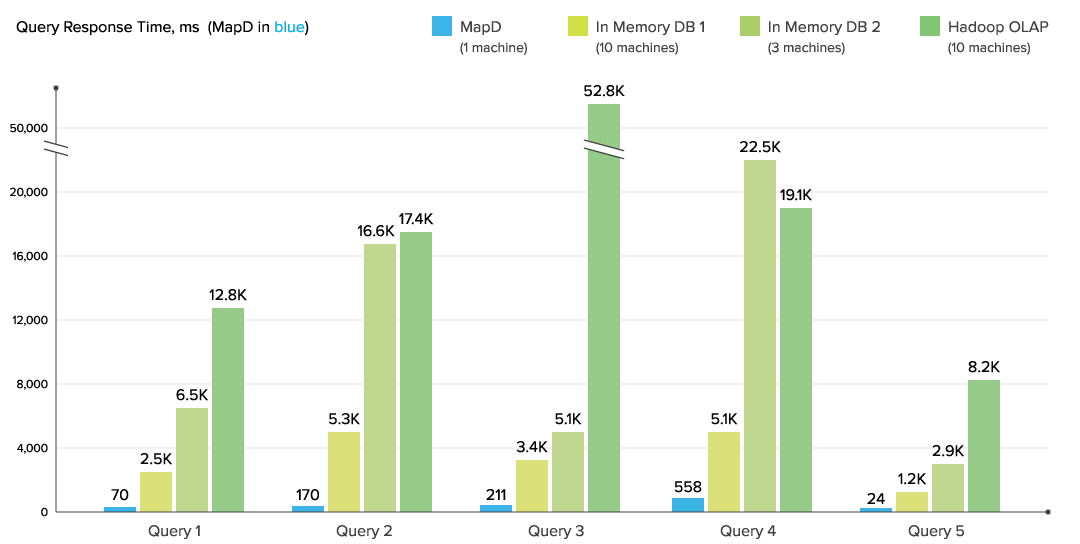
Data source: 10x copy of flights dataset (1.2B rows) at http://stat-computing.org/dataexpo/2009/the-data.html(可以下载更多的数据集,但是是分年份的)
| Query 1 | `select carrier_name, avg(arrdelay) from flights group by carrier_name` |
| Query 2 | `select origin_name, dest_name, avg(arrdelay) from flights group by origin_name, dest_name` |
| Query 3 | `select date_trunc(month,dep_timestamp) as ym, avg(arrdelay) as del from flights group by ym` |
| Query 4 | `select dest_name, extract(month from dep_timestamp) as m, extract(year from dep_timestamp) as y, avg(arrdelay) as del from flights group by dest_name,y,m` |
| Query 5 | `select count(*) from flights where origin_name='Lambert-St Louis International' and dest_name = 'Lincoln Municipal'` |
System configurations
MapD: 1 machine (8 core, 384 GB RAM, 2 x 2TB SSD, 8 Nvidia K40)
In-memory DB 1: 10 machines (16 core, 64 GB RAM, EBS storage, m4.4xlarge)
In-memory DB 2: 3 machines (32 core, 244 GB RAM, 2 x 320GB SSD, r3.8xlarge)
Hadoop OLAP: 10 machines (16 core, 64 GB RAM, EBS storage, m4.4xlarge)