概念:
分布式系统:
组件分布在网络计算机上,组件之间仅仅通过消息传递来通信并协调行动。
节点:
完成一组完整逻辑的程序个体,对应于server上的一个独立进程。
异常:
在分布式系统中还存在着一种状态:超时,意味着结果完全不确定。分布式协议就是保证系统在各种异常情形下仍能正常的工作。
CAP理论:
- C(Consistency:一致性):强一致性,保证数据中的数据完全一致;
- A(Available:可用性):在系统异常时,仍然可以提供服务,注:这儿的可用性,一方面要求系统可以正常的运行返回结果,另一方面同样对响应速度有一定的保障;
- P(Tolerance to the partition of network:分区容错性):既然是分布式系统,很多组件都是部署在不同的server中,通过网络通信协调工作,这就要求在某些节点服发生网络分区异常,系统仍然可以正常工作。
强一致性和强可用性在实际的系统中往往不能同时兼得,需要根据需求来权衡选择;
数据存储系统:
也即数据的分布式存储方式,主要有以下几个方式:
哈希方式:
每条数据通过某种计算方式计算出Hash值并分配到对应的服务器上;
int serverId = data.hashcode % serverTotalNum; 通过这种方式就可以将数据对应到不同的服务器上;
优点:简单易用,只需要根据数据的键值计算出serverid即可;
缺点:可扩展性不高,当需要增加服务器时会出现大量数据迁移;而且容易造成数据倾斜的问题;
数据范围分布方式:
将数据的某个特征值按照值域分为不同区间。比如按时间、区间分割,不同时间范围划分到不同server上。
优点:数据区间可以自由分割,当出现数据倾斜时,即某一个区间的数据量非常大,则可以将该区间split然后将数据进行重分配;集群方便扩展,当添加新的节点,只需将数据量多的节点数据迁移到新节点即可。
缺点:需要存储大量的元信息(数据区间和server的对应关系)。
数据量分布方式:
这样的存储方式和数据的特征类型没有关系,可以理解成将一个大的文件分成固定大小的多个block。
优点:不会有数据倾斜的问题,而且数据迁移时速度非常快(因为一个文件由多个block组成,block在不同的server上,迁移一个文件可以多个server并行复制这些block)。
缺点:需要存储大量的meta信息(文件和block的对应关系,block和server的对应关系)。
一致性哈希方式:
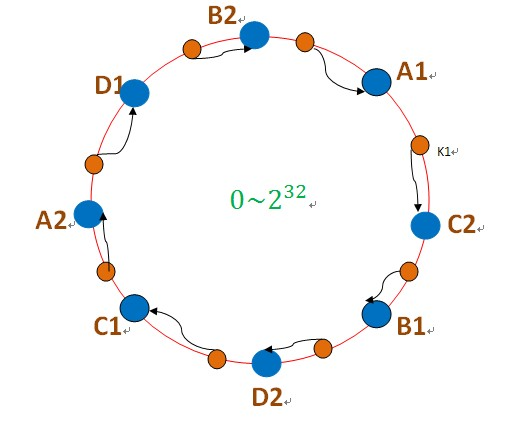
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置。一致性哈希和哈希的数据分布方式大概一致,唯一不同的是一致性哈希hash的值域是个环。
优点:集群可扩展性好,当增加删除节点,只影响相邻的数据节点。
缺点:当一个节点挂掉时,将压力全部转移到相邻节点,有可能将相邻节点压垮。
副本控制问题:
当某台服务器出现故障时,这台服务器上的数据就不可访问,为了保证系统仍谈能正常运转,需要对数据存储多个副本。
引入多个副本后,引来了一系列问题:多个副本之间,读取时以哪个副本的数据为准呢,更新时什么才算更新成功,是所有副本都更新成功还是部分副本更新成功即可认为更新成功?这些问题其实就是CAP理论中可用性和一致性的问题。其中primary-secondary副本控制模型则是解决这类问题行之有效的方法。
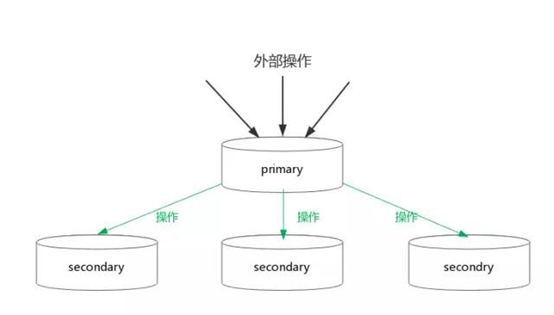
副本的更新:
副本更新基本流程:数据更新操作发到primary节点,由primary将数据更新操作同步到其他secondary副本,根据其他副本的同步结果返回客户端响应。
以mysql的master slave简单说明下,通常情况下,mysql的更新只需要master更新成功即可响应客户端,slave可以通过binlog慢慢同步,这种情形读取slave会有一定的延迟,一致性相对较弱,但是系统的可用性有了保证;另一种slave更新策略,数据的更新操作不仅要求master更新成功,同时要求slave也要更新成功,primary和secondray数据保持同步,系统保证强一致性,但可用性相对较差,响应时间变长。
根据quorum协议,在保证一定的可用性同时又保证一定的一致性的情形下,设置副本更新成功数为总副本数的一半(即N/2+1)性价比最高。
副本的读取:
副本的读取策略和一致性的选择有关,如果需要强一致性,我们可以只从primary副本读取,如果需要最终一致性,可以从secondary副本读取结果,如果需要读取最新数据,则按照quorum协议要求,读取相应的副本数。
副本的切换:
当系统中某个副本不可用时,需要从剩余的副本之中选取一个作为primary副本来保证后续系统的正常执行。
存储模型:
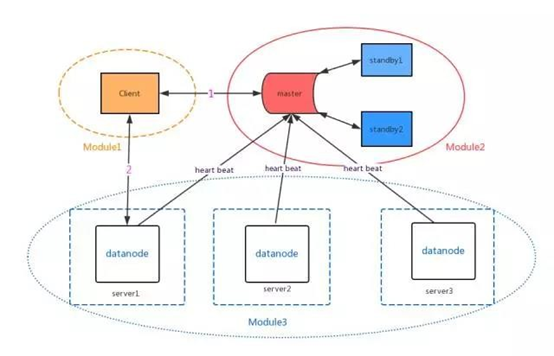
Client模块:负责用户和系统内部模块的通信。
Master模块:负责元数据的存储以及节点健康状态的管理。
Data节点模块:用于数据的存储和数据查询返回。
数据的查询流程通常分两步:
1. 向master节点查询数据对应的节点信息;
2. 根据返回的节点信息连接对应节点,返回相应的数据。
数据计算处理系统:
数据投递策略:
- at most once:数据处理最多一次,这种语义在异常情况下会有数据丢失;
- at least once:数据处理最少一次,这种语义会造成数据的重复;
- exactly once:数据只处理一次,这种语义支持是最复杂的,要想完成这一目标需要在数据处理的各个环节做到保障。
如何做到exactly once, 需要在数据处理各个阶段做些保证:
- 数据接收:由不同的数据源保证。
- 数据传输:数据传输可以保证exactly once。
- 数据输出:根据数据输出的类型确定,如果数据的输出操作对于同样的数据输入保证幂等性,这样就很简单(比如可以把kafka的offset作为输出mysql的id),如果不是,要提供额外的分布式事务机制如两阶段提交等等。
异常任务的处理:
因为数据计算的节点都是无状态的,只要启动任务副本即可。
其中任务恢复策略有以下几种:
- 简单暴力,重启任务重新计算相关数据;当某个数据执行超时或失败,则将该数据从源头开始在拓扑中重新计算。
- 根据checkpoint重试出错的任务,典型应用:mapreduce,一个完整的数据处理是分多个阶段完成的,每个阶段(map 或者reduce)的输出结果都会保存到相应的存储中,只要重启任务重新读取上一阶段的输出结果即可继续开始运行,不必从开始重新执行该任务。
背压——Backpressure:
在数据处理中,经常会担心这样一个问题:数据处理的上游消费数据速度太快,会不会压垮下游数据输出端如mysql等。 通常的解决方案:上线前期我们会做详细的测试,评估数据下游系统承受的最大压力,然后对数据上游进行限流的配置,比如限制每秒最多消费多少数据。
数据处理通用架构:

- client: 负责计算任务的提交。
- scheduler : 计算任务的生成和计算资源的调度,同时还包含计算任务运行状况的监控和异常任务的重启。
- worker:计算任务会分成很多小的task, worker负责这些小task的执行同时向scheduler汇报当前node可用资源及task的执行状况。