mongodb主要解决的是海量数据的访问效率,当数据量达到50GB以上的时候,mongodb的数据库访问效率是mysql的10倍以上,默认端口是27017
mysql是一个关系型数据库管理系统,而mongodb是非关系型的数据库,mongodb非关系型数据库,高性能,开源,是当前NoSql数据库中比较热门的一种,mongo使用C++开发,NoSql,全称是Not Only Sql,指的是非关系型数据库,关系型数据库是表和表之间有关联关系,非关系型数据库是键值对
AA
|
id |
Buy |
|
A |
1000 |
|
B |
2000 |
BB
|
id |
Sell |
|
A |
100 |
|
A |
200 |
|
B |
200 |
|
B |
300 |
select id,Buy-Sold from AA,(select id,sum(Sell) as Sold from BB group by id) as bb where AA.id=bb.id
表全部数据: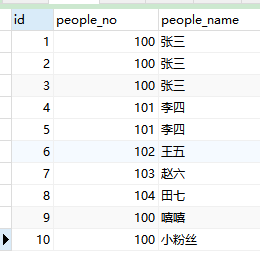
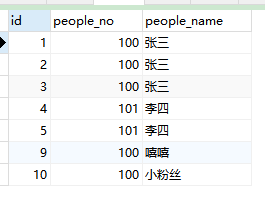
1、查询people_no重复的记录(如果查询people_name重复的记录,把people_no换成people_name即可)
select * from people where people_no in (select people_no from people group by people_no having count(people_no) > 1);
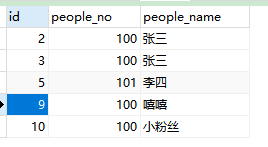
2、查询people_no重复的记录 ,排除最小id(删除id为1的记录)
select * from people where people_no in (select people_no from people group by people_no having count(people_no) > 1) and id not in (select min(id) from people group by people_no having count(people_no)>1);
3、查询people_no和people_name重复的记录
select * from people a where (a.people_no,a.people_name) in (select people_no,people_name from people GROUP BY people_no,people_name HAVING count(*)>1);

4、查询people_no和people_name重复的记录,排除最小id
select * from people a where (a.people_no,a.people_name) in (select people_no,people_name from people GROUP BY people_no,people_name HAVING count(*)>1) and a.id not in (select min(id) from people GROUP BY people_no,people_name HAVING count(*)>1);
登录MySQL
连接到本机上的MYSQL命令是:在虚拟机里输入mysql -u root -p,点击回车,提示输入密码,输入123123,在输入密码的时候不会显示,输入完毕后直接回车,光标停留在mysql命令行了,就能看到已经登录到了MySQL,连接到远程主机上的MYSQL命令:mysql -h远程主机IP地址 -u用户名 -p用户密码,退出mysql命令行的命令是quit或ctrl+c
先建立besttest数据库,编码为utf8,在虚拟机中进入mysql命令行,输入create database besttest default charset=utf8;
创建数据库:create database dbname
删除数据库:drop database dbname
查看数据库:show databases
查看创建数据库的sql语句:show create database test
create table table_name (col1 type1 [not null] [primary key], col2 type2 [not null] [primary key],..)
创建一个与当前某个表相似的空表:create table table_name(新表) like table_name1(旧表)
创建一个和ssj相同的备份表ssj2,要求表结构相同,数据相同:insert into ssj2(新表) select * from ssj(有数据的表)
增加字段:ADD col_name column_definition
增加字段在某个字段后面:alter table tablename add 字段 after name
增加字段在某个字段前面:alter table tablename add 字段 first name
删除表:drop table table_name
修改表名:alter table school rename school2
修改字段类型:alter table table_name MODIFY col_name column_definition
修改字段名:alter table table_name CHANGE old_col_name new_col_name column_definition
查看表结构的详细信息:desc table_name
查看创建表的sql语句:show create table tablename
1、在表最后添加一个字段interest,新增加的字段默认是在最后一个
alter table ssj add interest varchar(10);
2、在表的第一列新增加一个字段sid
alter table ssj add sid int first;
3、在ssj_age后增加一个字段age_sex
alter table ssj add age_sex varchar(10) after ssj_age;
4、在ssj_age后增加tel,在最后一列新增email
alter table ssj add tel int(11) after ssj_age,add email varchar(20);
5、修改列名称ssj_age为age
alter table ssj change ssj_age age int(2);
6、修改数据类型
alter table ssj modify ssj_sex int(1);
7、删除某一个列
alter table ssj drop sid;
alter table tablename drop 字段;删除某个字段
delete清空的表自增长id还会继续增长,是从删除那条记录的ID+1开始
truncate清空的表自增长id从1开始,truncate速度比delete要快,drop>truncate>delete,因为truncate是从磁盘上删除数据,恢复不了
下划线通配符表示任一个单字符:select * from tablename where 字段 like 'yao_'
百分号通配符表示包含零个或多个字符组成的任意字符串:select * from tablename where 字段 like '%yao%'
查找任一个人的信息:select * from tablename where 字段 in('哈哈,'呵呵','好好')
去掉重复的,只留一个:select distinct 字段 from tablename
从第几条开始,下面的5条,不包含开始的那一条:select * from blk limit 1,5,就是从第2条开始到第6条
查询前5条:select * from blk limit 5
查询后5条:select * from blk desc limit 5
选择:select * from table1 where 范围,如果想查某几个字段,把字段名列出来,用,分隔
插入:insert into table1(field1,field2) values (value1,value2)
删除:delete from table1 where 范围
更新:update table1 set field1= value1 where 范围
查找:select * from table1 where field1 like '%value1%',模糊查询
排序:select * from table1 order by field1,field2[desc]
总数:select count(*) as totalcount from table1 # totalcount是重新起的一个列名,和group by一起使用
求和:select sum(field1) as sumvalue from table1 # sumvalue是重新起的一个列名,和group by一起使用
平均:select avg(field1) as avgvalue from table1 # avgvalue是重新起的一个列名,和group by一起使用
最大:select max(field1) as maxvalue from table1 # maxvalue是重新起的一个列名,和group by一起使用
最小:select min(field1) as minvalue from table1 # minvalue是重新起的一个列名 ,和group by一起使用
例如统计每个班同学的人数,group by子句与聚合函数一起使用
select b.class_name 班级名称,COUNT(b.student_id) 学生人数 from students a,class b where a.id=b.student_id GROUP BY b.class_name;
例如查询索隆班男女学生的人数,group by子句与having子句一起使用
SELECT a.sex,count(a.id),b.class_name from students a ,class b where a.id=b.student_id GROUP BY a.sex HAVING b.class_name ='索隆';
group by多个字段分组
SELECT a.sex,count(a.id),b.class_name from students a ,class b where a.id=b.student_id GROUP BY a.sex,b.class_name;
排序分组的时候order by放在group by后面
select sex 性别,count(*) 人数,a.stu_name from blk a where a.money > 300 group by a.id having a.stu_name like '姚%';如果group by后面有条件的话,必须得用having子句,having子句里面用到的字段必须出现在select后面,要不然就会报错
select xxx,xxxxx 聚合函数() from a,b where a.id=b.id and 条件 group by 字段 having(筛选) order by desc/asc limit x,没有什么去掉什么
表连接

---内连接
select * from books a inner join articles b on a.title=b.title,inner可以省略,inner join 获取的就是两个表中的交集部分,如下图:

---外连接
select a.id,a.title,a.created_at,b.content from books a left join articles b on a.title=b.title, 左连接会读取左边数据表的全部数据,即使右边数据表没有对应数据(如果两个表中数据有相同部分,只显示一个),如下图:
select a.id,a.title,a.created_at,b.content from books a right join articles b on a.title=b.title, 右连接会读取右边数据表的全部数据,即使左边数据表没有对应数据(如果两个表中数据有相同部分,只显示一个),如下图:
select id,stu_name from blk union select id,t_name from teacher;
union用来合并两条select语句的结果,两条select语句字段数量和数据类型必须一致,union前后的两个表没有关联,如果取全校老师和学生的总数就可以用union,union all的效率比union高,union all不会去掉重复的,union可以去重
子查询:把一条sql的结果,作为另一条sql的条件
select * from score where s.id = (select id from blk where stu_name = '哈哈')
括号里的是sql的结果(子查询),前面的sql是条件(主查询),在外面进行二次筛选,=是匹配到,in是在查询的范围内能匹配一点
为数据库授权:
grant select,insert,update on bugfree.* to 'tester' @ '%' identified by '123456';
grant all on *.* to 'andashu'@ 'localhost' identified by '123456' with grant option;
grant all on *.* to 'andashu'@ '%' identified by '123456' with grant option;
all代表所有的权限
第一个*代表所有数据库,第二个*代表所有表
andashu代表用户
localhost代表用户ip
123456代表密码
with grant option表示有执行grant语句的权限
取消授权:
revoke all on *.* from dba@localhost; all包括select,insert,update
revoke select on *.* from andashu@localhost;
修改完权限后要执行这个命令来刷新权限:flush privileges,存在内存里重启电脑数据就没了,数据放在磁盘里才持久化