可以通过https://gitee.com/sun_shu_jiang/,先把earth项目的代码拉下来,也可以通过下图的方式:
弹出的对话框里输入git地址https://gitee.com/nnzhp/earth.git,点击clone按钮就可以把代码拉下来(前提是git安装成功了),拉下来会提示如下图:
点击Yes会弹出如下提示:

可以选择This Window,也可以选择New Window,在pycharm里打开,启动服务,如果有报错,通过pycharm拉代码的解决方式是在一级目录下新建一个logs目录,如果是最上面的方式拉的代码就要在settings.py里注释下面的mysql数据库,用上面的sqlite,在启动就ok了
新建一个app,python manage.py startapp sksystem,回车,创建成功了在当前目录下新建一个urls.py文件,打开earth目录下的urls.py文件,from sksystem import urls,把上面example的urls删除就可以了,然后导入url,把它加到urlpatterns里,earth下的urls.py文件新增代码如下图:

然后在settings.py文件的INSTALLED_APPS里导入sksystem,然后全部复制example目录下的urls.py里的代码拷到sksystem下的urls.py里,删除urlpatterns里的所有代码,只保留一行
接下来创建表,models.py里的BaseModel和User类是从example里复制出来的,其他新增的所有表的代码如下图:
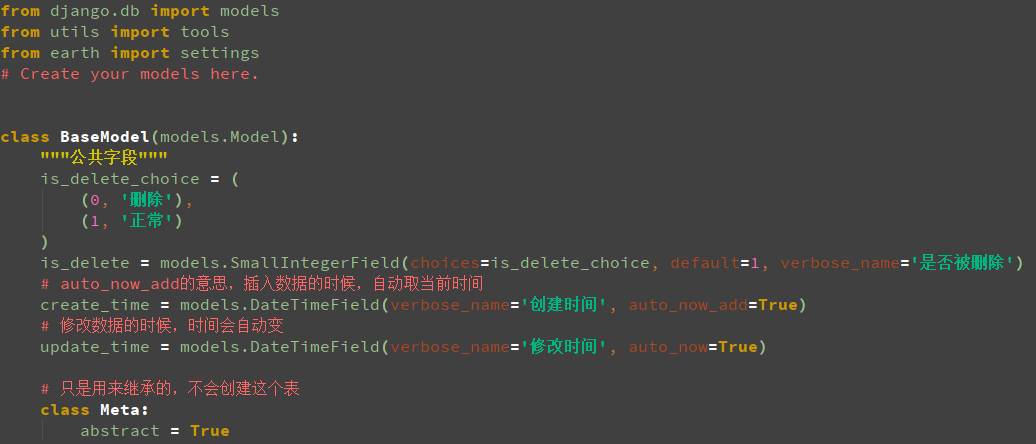
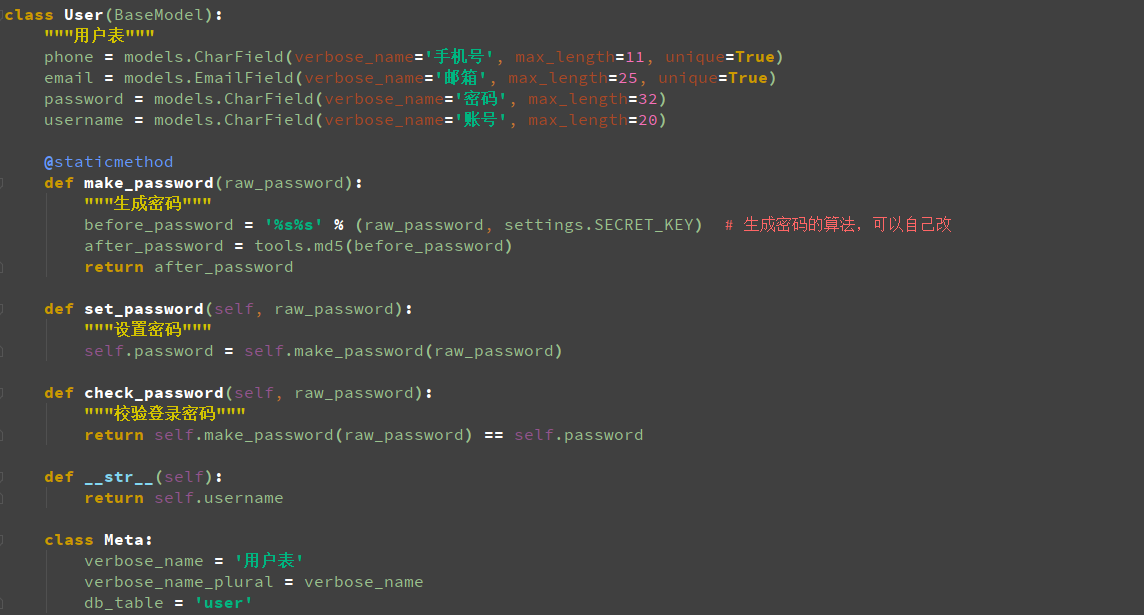
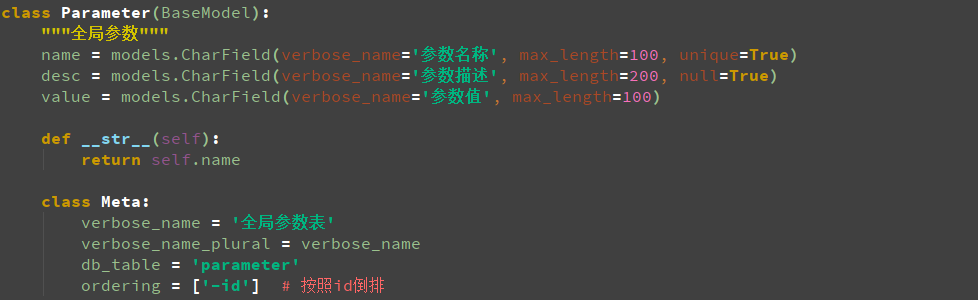



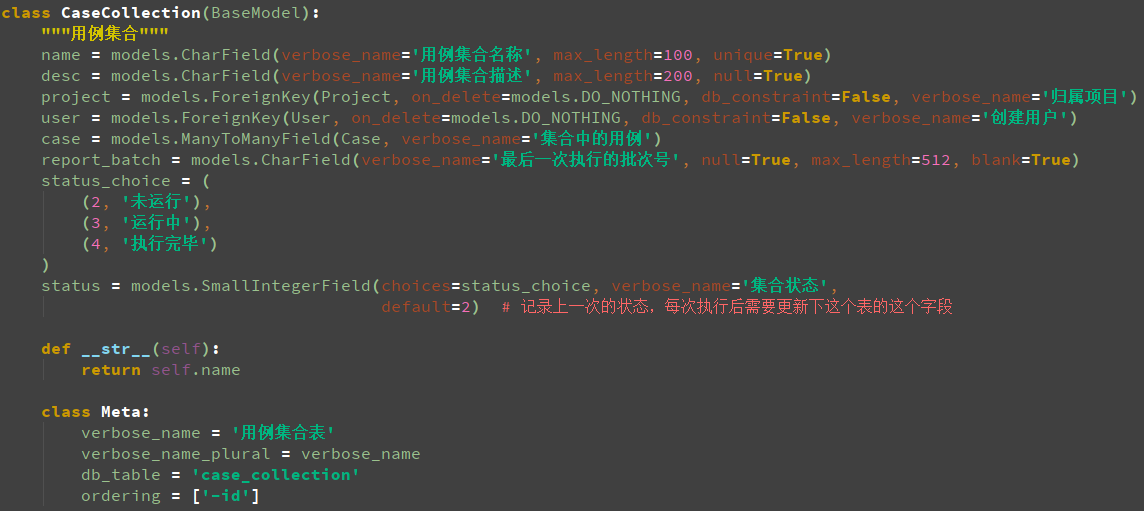
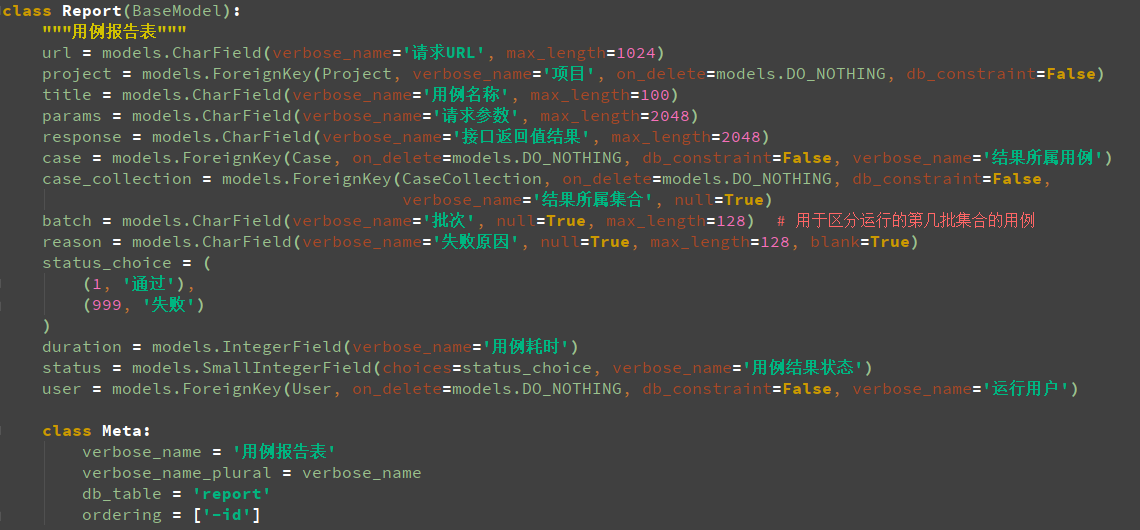

case表里的无法做到关联,生成一个case_premise表,通过case_id和premise_case_id外键到case表做到case_id依赖于premise_case_id,一共是8个类,related_name是给这个外键定义好一个名称,应该生成9张表(包括一个多对多的表,即case_collection_case),生成表结构时一定要注释sksystem目录下的urls.py文件里的urlpatterns里的代码,Copy Path看数据库里的表,把库里所有的表都删除,运行时要加上app的名字,python manage.py makemigrations sksystem(生成初始化文件,在E:earthsksystemmigrations�001_initial.py路径下)和python manage.py migrate sksystem(同步到数据库),生成表结构后连接sqlite数据库,连接数据库时不用输入用户名和密码,正常生成了10个表,生成的表如下图:

在项目sksystem目录下新建一个文件models_test.py,把下面三行代码复制进去,如下:
import django, os
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'earth.settings') # 设置django的配置文件
django.setup()
然后运行一下,如果没有问题即可,如果报错查看一下是什么问题,我运行报没有找到corsheaders这个错误,这个是允许跨域的app,在python3.5的项目里已经安装过了,3.7的django项目里没有安装,因此需要安装django-cors-headers,安装成功在运行就不报错了,然后去user表里手动新增一条数据,新增数据如下图:

然后在models_test.py文件里,输入如下代码:
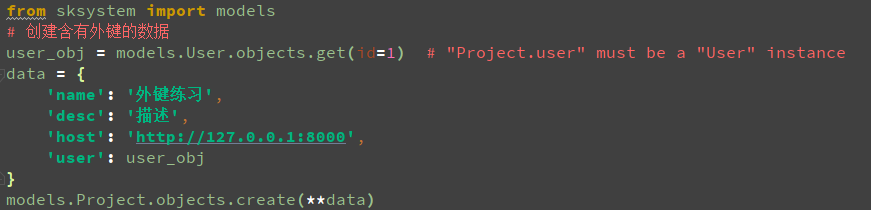
运行一下,没有报错,去数据表project里看是否新增了一条数据,新增成功,如下图:

查询操作如下图:

删除操作如下图:

然后往case表里插入两条数据,sql语句如下:
INSERT INTO `case`( `is_delete`, `create_time`, `update_time`, `title`, `method`, `cache_field`, `check`, `params`, `headers`, `is_json`, `json`, `status`, `report_batch`, `project_id`, `user_id`, `interface_id`) VALUES ( 1, '2020-03-12 11:06:42.375921', '2020-03-12 11:06:42.375921', '测试平台登录接口', 1, 'token', 'code=0', '{}', '{}', 0, NULL, 1, '79c06685-5658-4dba-bbac-7ebdeb0201d3', 1, 2, 1);
INSERT INTO `case`( `is_delete`, `create_time`, `update_time`, `title`, `method`, `cache_field`, `check`, `params`, `headers`, `is_json`, `json`, `status`, `report_batch`, `project_id`, `user_id`, `interface_id`) VALUES ( 1, '2020-03-12 11:06:52.375921', '2020-03-12 11:06:52.375921', '测试平台项目接口', 2, NULL, 'code=0', '{}', '{}', 0, NULL, 1, '866dbcf2-cdf8-4e6e-a696-3f2977829f8f', 1, 2, 2);
运行sql语句,成功往case表里插入两条数据,如下图:



case_obj可以.case,也可以.premise_case,qs = case_obj.case.all()相当于case_id为1的这条数据,case_obj.case.all() == select * from CasePremise where case_id= 1;,qs相当于[case_id为1的CasePremise数据]
然后往case_collection表里插入一条数据,sql语句如下:
INSERT INTO `case_collection`(`id`, `is_delete`, `create_time`, `update_time`, `name`, `desc`, `report_batch`, `status`, `project_id`, `user_id`) VALUES (1, 1, '2020-03-15 15:08:04.594509', '2020-03-15 15:08:04.594509', '测试平台回归', '登录和项目的回归', 'b4a64581-5805-49d5-8991-20c34656e07b', 4, 1, 2);
运行sql语句,成功往case_collection表里插入一条数据,如下图:
多对多(ManyToMany)
用例集合和用例是多对多的关系
A集合和B集合,A用例和B用例,A集合 -- A用例、B用例,B集合 -- A用例、B用例
还可以通过存在的case_id进行add,collection_obj.case.add(2),这种也ok
创建成功就会在case_collection_case表中插入两条数据,如下图: