一、通过json文件驱动
import unittest
from ddt import ddt, file_data
@ddt
class MyTest(unittest.TestCase):
# test_data_list.json里的数据是[1,2,3]
@file_data('test_data_list.json')
def test_data_list(self, value):
print(value)
# test_data_dict.json里的数据是{"name": "张三", "age": 19},k-v必须是双引号格式
@file_data('test_data_dict.json')
def test_data_dict(self, value):
print(value)
if __name__ == '__main__':
unittest.main(verbosity=2)
打印的结果为:

二、通过yaml文件驱动
pip install pyyaml进行安装,直接import yaml,右键运行py文件,不报错,则为导入成功
PyYaml简介:
YAML是一种容易阅读、适合表示程序语言的数据结构、可用于不同程序间交换数据、丰富的表达能力和可扩展性、易于使用的语言,通过缩进或符号来表示数据类型
Yaml提供了多种方法,常用的为yaml.load和yaml.dump
它的基本语法规则如下:
1、大小写敏感
2、使用缩进表示层级关系
3、缩进时不允许使用Tab键,只允许使用空格
4、缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
5、# 表示注释,从这个字符一直到行尾,都会被解析器忽略,这个和python的注释一样
PyYaml文件编写格式:
yaml文档除了可以通过dump进行转化之外,也可以根据yaml文档的格式进行编写
1、对象的一组键值对,使用冒号结构表示
2、一组减号开头的行,构成一个list
3、对象和数组可以结合使用,形成复合结构
4、~ 代表None
5、布尔类型直接写bool: True False
YAML支持的数据结构有三种:
1、对象:键值对的集合,又称为映射(mapping)/哈希(hashes)/字典(dictionary)
2、数组:一组按次序排列的值,又称为序列(sequence)/列表(list)
3、纯量(scalars):单个的、不可再分的值。字符串、布尔值、整数、浮点数、Null、时间、日期
# 写入yaml文件
import yaml
with open('dump.yml', 'w') as f:
d = {
'student': {
'name': 'aa',
'age': 20,
'love': {
'ball': 'volleyball',
'book': 'python'
}
},
'teacher': {
'name': 'bb',
'age': 20
},
'data': [2, 3, 4, 5]
}
yaml.dump(d, f)
yaml.dump([data,filehandle])
yaml.dump将一个python对象生成为yaml文档,参数一为要转为yaml文档的数据,参数二必须为一个已经打开的文件对象,这里是将转成的yaml格式保存到文件里,以下是保存到文件(dump.yml)里的数据:
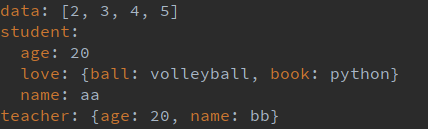
# 加载yaml文件
with open('dump.yml', 'r') as f:
data = yaml.load(f)
print(data)
yaml.load([filehandle])
yaml.load接收文件句柄,将yml文件中的数据转为python的数据类型,下面是输出的结果:
可以将yaml与ddt联合应用,将yaml作为数据存储,可以将test case写在yaml文件里:

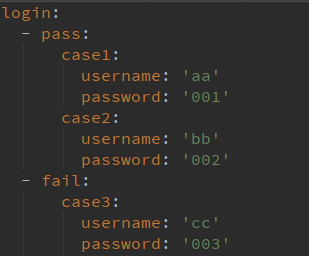
import unittest
from ddt import ddt, file_data
@ddt
class My_test(unittest.TestCase):
@file_data('dump.yml')
def test_data_yaml(self, value):
print(value)
print(type(value))
if __name__ == '__main__':
unittest.main(verbosity=2)
打印的结果为:

1、组合使用后,通过yaml的数据来控制case的执行
2、yaml文档的使用,使case维护更加方便快捷