文章来源:https://zhuanlan.zhihu.com/p/25539690
Java的性能优化,整理出一篇文章,供以后温故知新。
JVM GC(垃圾回收机制)
在学习Java GC 之前,我们需要记住一个单词:stop-the-world 。它会在任何一种GC算法中发生。stop-the-world 意味着JVM因为需要执行GC而停止了应用程序的执行。当stop-the-world 发生时,除GC所需的线程外,所有的线程都进入等待状态,直到GC任务完成。GC优化很多时候就是减少stop-the-world 的发生。
JVM GC回收哪个区域内的垃圾?
需要注意的是,JVM GC只回收堆区和方法区内的对象。而栈区的数据,在超出作用域后会被JVM自动释放掉,所以其不在JVM GC的管理范围内。
JVM GC怎么判断对象可以被回收了?
· 对象没有引用
· 作用域发生未捕获异常
· 程序在作用域正常执行完毕
· 程序执行了System.exit()
· 程序发生意外终止(被杀线程等)
在Java程序中不能显式的分配和注销缓存,因为这些事情JVM都帮我们做了,那就是GC。
有些时候我们可以将相关的对象设置成null 来试图显示的清除缓存,但是并不是设置为null 就会一定被标记为可回收,有可能会发生逃逸。
将对象设置成null 至少没有什么坏处,但是使用System.gc() 便不可取了,使用System.gc() 时候并不是马上执行GC操作,而是会等待一段时间,甚至不执行,而且System.gc() 如果被执行,会触发Full GC ,这非常影响性能。
JVM GC什么时候执行?
eden区空间不够存放新对象的时候,执行Minro GC。升到老年代的对象大于老年代剩余空间的时候执行Full GC,或者小于的时候被HandlePromotionFailure 参数强制Full GC 。调优主要是减少 Full GC 的触发次数,可以通过 NewRatio 控制新生代转老年代的比例,通过MaxTenuringThreshold 设置对象进入老年代的年龄阀值(后面会介绍到)。
按代的垃圾回收机制
新生代(Young generation):绝大多数最新被创建的对象都会被分配到这里,由于大部分在创建后很快变得不可达,很多对象被创建在新生代,然后“消失”。对象从这个区域“消失”的过程我们称之为:Minor GC 。
老年代(Old generation):对象没有变得不可达,并且从新生代周期中存活了下来,会被拷贝到这里。其区域分配的空间要比新生代多。也正由于其相对大的空间,发生在老年代的GC次数要比新生代少得多。对象从老年代中消失的过程,称之为:Major GC 或者 Full GC。
持久代(Permanent generation)也称之为 方法区(Method area):用于保存类常量以及字符串常量。注意,这个区域不是用于存储那些从老年代存活下来的对象,这个区域也可能发生GC。发生在这个区域的GC事件也被算为 Major GC 。只不过在这个区域发生GC的条件非常严苛,必须符合以下三种条件才会被回收:
1、所有实例被回收
2、加载该类的ClassLoader 被回收
3、Class 对象无法通过任何途径访问(包括反射)
可能我们会有疑问:
如果老年代的对象需要引用新生代的对象,会发生什么呢?
为了解决这个问题,老年代中存在一个 card table ,它是一个512byte大小的块。所有老年代的对象指向新生代对象的引用都会被记录在这个表中。当针对新生代执行GC的时候,只需要查询 card table 来决定是否可以被回收,而不用查询整个老年代。这个 card table 由一个write barrier 来管理。write barrier给GC带来了很大的性能提升,虽然由此可能带来一些开销,但完全是值得的。
默认的新生代(Young generation)、老年代(Old generation)所占空间比例为 1 : 2 。
新生代空间的构成与逻辑
为了更好的理解GC,我们来学习新生代的构成,它用来保存那些第一次被创建的对象,它被分成三个空间:
· 一个伊甸园空间(Eden)
· 两个幸存者空间(Fron Survivor、To Survivor)
默认新生代空间的分配:Eden : Fron : To = 8 : 1 : 1
每个空间的执行顺序如下:
1、绝大多数刚刚被创建的对象会存放在伊甸园空间(Eden)。
2、在伊甸园空间执行第一次GC(Minor GC)之后,存活的对象被移动到其中一个幸存者空间(Survivor)。
3、此后,每次伊甸园空间执行GC后,存活的对象会被堆积在同一个幸存者空间。
4、当一个幸存者空间饱和,还在存活的对象会被移动到另一个幸存者空间。然后会清空已经饱和的哪个幸存者空间。
5、在以上步骤中重复N次(N = MaxTenuringThreshold(年龄阀值设定,默认15))依然存活的对象,就会被移动到老年代。
从上面的步骤可以发现,两个幸存者空间,必须有一个是保持空的。如果两个两个幸存者空间都有数据,或两个空间都是空的,那一定是你的系统出现了某种错误。
我们需要重点记住的是,对象在刚刚被创建之后,是保存在伊甸园空间的(Eden)。那些长期存活的对象会经由幸存者空间(Survivor)转存到老年代空间(Old generation)。
也有例外出现,对于一些比较大的对象(需要分配一块比较大的连续内存空间)则直接进入到老年代。一般在Survivor 空间不足的情况下发生。
老年代空间的构成与逻辑
老年代空间的构成其实很简单,它不像新生代空间那样划分为几个区域,它只有一个区域,里面存储的对象并不像新生代空间绝大部分都是朝闻道,夕死矣。这里的对象几乎都是从Survivor 空间中熬过来的,它们绝不会轻易的狗带。因此,Full GC(Major GC)发生的次数不会有Minor GC 那么频繁,并且做一次Major GC 的时间比Minor GC 要更长(约10倍)。
JVM GC 算法讲解
1、根搜索算法
根搜索算法是从离散数学中的图论引入的,程序把所有引用关系看作一张图,从一个节点GC ROOT 开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点的引用节点。当所有的引用节点寻找完毕后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。
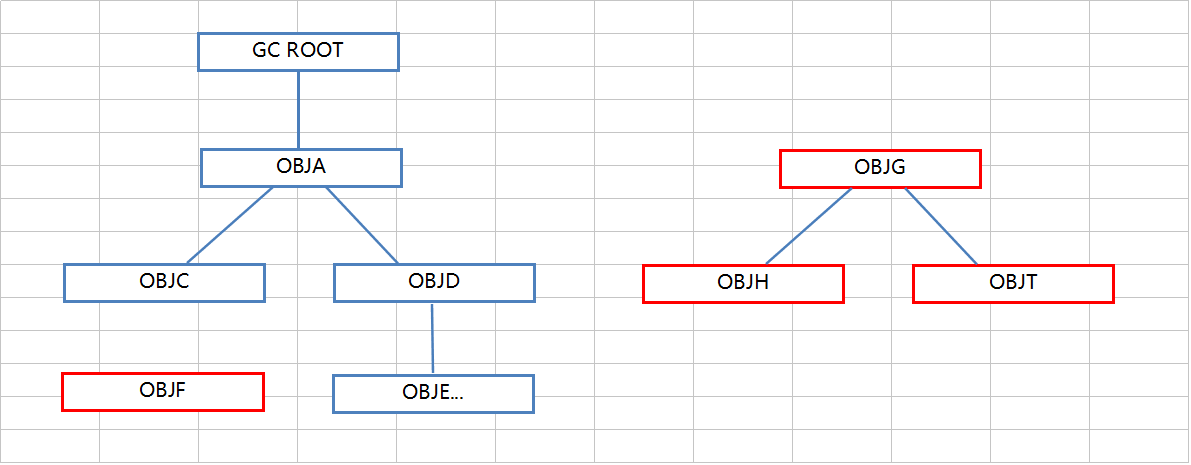
上图红色为无用的节点,可以被回收。
目前Java中可以作为GC ROOT的对象有:
1、虚拟机栈中引用的对象(本地变量表)
2、方法区中静态属性引用的对象
3、方法区中常亮引用的对象
4、本地方法栈中引用的对象(Native对象)
基本所有GC算法都引用根搜索算法这种概念。
2、标记 - 清除算法
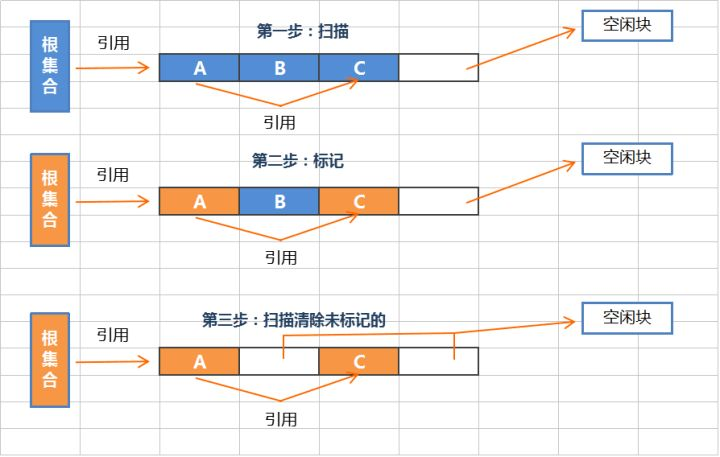
标记-清除算法采用从根集合进行扫描,对存活的对象进行标记,标记完毕后,再扫描整个空间中未被标记的对象进行直接回收,如上图。
标记-清除算法不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活的对象比较多的情况下极为高效,但由于标记-清除算法直接回收不存活的对象,并没有对还存活的对象进行整理,因此会导致内存碎片。
3、复制算法
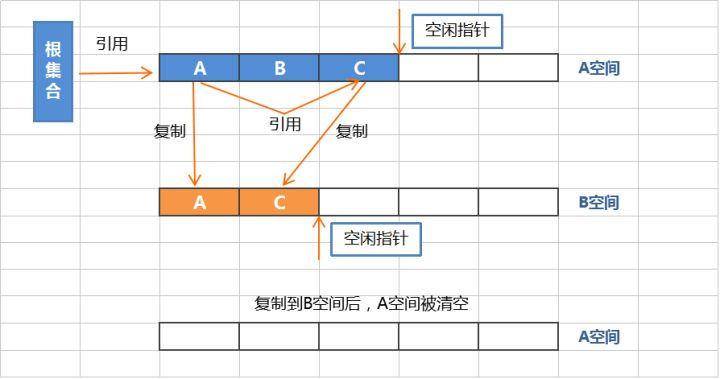
复制算法将内存分为两个区间,使用此算法时,所有动态分配的对象都只能分配在其中一个区间(活动区间),而另外一个区间(空间区间)则是空闲的。
复制算法采用从根集合扫描,将存活的对象复制到空闲区间,当扫描完毕活动区间后,会的将活动区间一次性全部回收。此时原本的空闲区间变成了活动区间。下次GC时候又会重复刚才的操作,以此循环。
复制算法在存活对象比较少的时候,极为高效,但是带来的成本是牺牲一半的内存空间用于进行对象的移动。所以复制算法的使用场景,必须是对象的存活率非常低才行,而且最重要的是,我们需要克服50%内存的浪费。
4、标记 - 整理算法
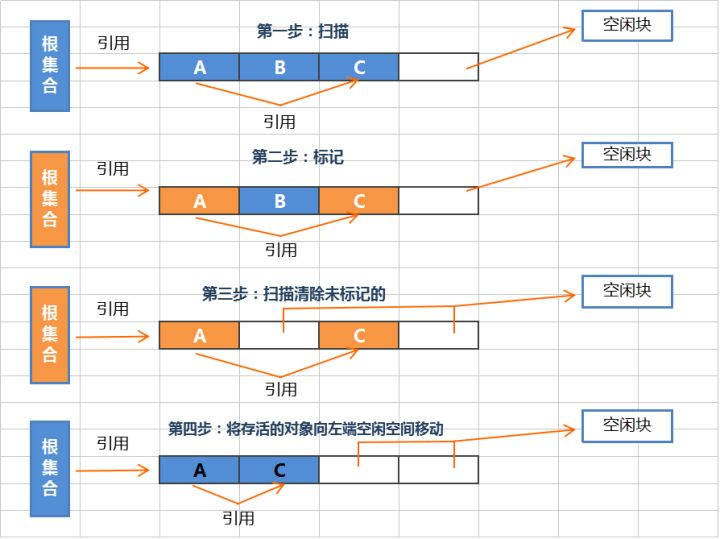
标记-整理算法采用 标记-清除 算法一样的方式进行对象的标记、清除,但在回收不存活的对象占用的空间后,会将所有存活的对象往左端空闲空间移动,并更新对应的指针。标记-整理 算法是在标记-清除 算法之上,又进行了对象的移动排序整理,因此成本更高,但却解决了内存碎片的问题。
JVM为了优化内存的回收,使用了分代回收的方式,对于新生代内存的回收(Minor GC)主要采用复制算法。而对于老年代的回收(Major GC),大多采用标记-整理算法。
垃圾回收器简介
需要注意的是,每一个回收器都存在Stop The World 的问题,只不过各个回收器在Stop The World 时间优化程度、算法的不同,可根据自身需求选择适合的回收器。
1、Serial(-XX:+UseSerialGC)
从名字我们可以看出,这是一个串行收集器。
Serial收集器是Java虚拟机中最基本、历史最悠久的收集器。在JDK1.3之前是Java虚拟机新生代收集器的唯一选择。目前也是ClientVM下ServerVM 4核4GB以下机器默认垃圾回收器。Serial收集器并不是只能使用一个CPU进行收集,而是当JVM需要进行垃圾回收的时候,需暂停所有的用户线程,直到回收结束。
使用算法:复制算法

JVM中文名称为Java虚拟机,因此它像一台虚拟的电脑在工作,而其中的每一个线程都被认为是JVM的一个处理器,因此图中的CPU0、CPU1实际上为用户的线程,而不是真正的机器CPU,不要误解哦。
Serial收集器虽然是最老的,但是它对于限定单个CPU的环境来说,由于没有线程交互的开销,专心做垃圾收集,所以它在这种情况下是相对于其他收集器中最高效的。
2、SerialOld(-XX:+UseSerialGC)
SerialOld是Serial收集器的老年代收集器版本,它同样是一个单线程收集器,这个收集器目前主要用于Client模式下使用。如果在Server模式下,它主要还有两大用途:一个是在JDK1.5及之前的版本中与Parallel Scavenge收集器搭配使用,另外一个就是作为CMS收集器的后备预案,如果CMS出现Concurrent Mode Failure,则SerialOld将作为后备收集器。
使用算法:标记 - 整理算法
运行示意图与上图一致。
3、ParNew(-XX:+UseParNewGC)
ParNew其实就是Serial收集器的多线程版本。除了Serial收集器外,只有它能与CMS收集器配合工作。
使用算法:复制算法

ParNew是许多运行在Server模式下的JVM首选的新生代收集器。但是在单CPU的情况下,它的效率远远低于Serial收集器,所以一定要注意使用场景。
4、ParallelScavenge(-XX:+UseParallelGC)
ParallelScavenge又被称为吞吐量优先收集器,和ParNew 收集器类似,是一个新生代收集器。
使用算法:复制算法
ParallelScavenge收集器的目标是达到一个可控件的吞吐量,所谓吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)。如果虚拟机总共运行了100分钟,其中垃圾收集花了1分钟,那么吞吐量就是99% 。
5、ParallelOld(-XX:+UseParallelOldGC)
ParallelOld是并行收集器,和SerialOld一样,ParallelOld是一个老年代收集器,是老年代吞吐量优先的一个收集器。这个收集器在JDK1.6之后才开始提供的,在此之前,ParallelScavenge只能选择SerialOld来作为其老年代的收集器,这严重拖累了ParallelScavenge整体的速度。而ParallelOld的出现后,“吞吐量优先”收集器才名副其实!
使用算法:标记 - 整理算法

在注重吞吐量与CPU数量大于1的情况下,都可以优先考虑ParallelScavenge + ParalleloOld收集器。
6、CMS (-XX:+UseConcMarkSweepGC)
CMS是一个老年代收集器,全称 Concurrent Low Pause Collector,是JDK1.4后期开始引用的新GC收集器,在JDK1.5、1.6中得到了进一步的改进。它是对于响应时间的重要性需求大于吞吐量要求的收集器。对于要求服务器响应速度高的情况下,使用CMS非常合适。
CMS的一大特点,就是用两次短暂的暂停来代替串行或并行标记整理算法时候的长暂停。
使用算法:标记 - 清理
CMS的执行过程如下:
· 初始标记(STW initial mark)
在这个阶段,需要虚拟机停顿正在执行的应用线程,官方的叫法STW(Stop Tow World)。这个过程从根对象扫描直接关联的对象,并作标记。这个过程会很快的完成。
· 并发标记(Concurrent marking)
这个阶段紧随初始标记阶段,在“初始标记”的基础上继续向下追溯标记。注意这里是并发标记,表示用户线程可以和GC线程一起并发执行,这个阶段不会暂停用户的线程哦。
· 并发预清理(Concurrent precleaning)
这个阶段任然是并发的,JVM查找正在执行“并发标记”阶段时候进入老年代的对象(可能这时会有对象从新生代晋升到老年代,或被分配到老年代)。通过重新扫描,减少在一个阶段“重新标记”的工作,因为下一阶段会STW。
· 重新标记(STW remark)
这个阶段会再次暂停正在执行的应用线程,重新重根对象开始查找并标记并发阶段遗漏的对象(在并发标记阶段结束后对象状态的更新导致),并处理对象关联。这一次耗时会比“初始标记”更长,并且这个阶段可以并行标记。
· 并发清理(Concurrent sweeping)
这个阶段是并发的,应用线程和GC清除线程可以一起并发执行。
· 并发重置(Concurrent reset)
这个阶段任然是并发的,重置CMS收集器的数据结构,等待下一次垃圾回收。
CMS的缺点:
1、内存碎片。由于使用了 标记-清理 算法,导致内存空间中会产生内存碎片。不过CMS收集器做了一些小的优化,就是把未分配的空间汇总成一个列表,当有JVM需要分配内存空间的时候,会搜索这个列表找到符合条件的空间来存储这个对象。但是内存碎片的问题依然存在,如果一个对象需要3块连续的空间来存储,因为内存碎片的原因,寻找不到这样的空间,就会导致Full GC。
2、需要更多的CPU资源。由于使用了并发处理,很多情况下都是GC线程和应用线程并发执行的,这样就需要占用更多的CPU资源,也是牺牲了一定吞吐量的原因。
3、需要更大的堆空间。因为CMS标记阶段应用程序的线程还是执行的,那么就会有堆空间继续分配的问题,为了保障CMS在回收堆空间之前还有空间分配给新加入的对象,必须预留一部分空间。CMS默认在老年代空间使用68%时候启动垃圾回收。可以通过-XX:CMSinitiatingOccupancyFraction=n来设置这个阀值。
7、GarbageFirst(G1)
这是一个新的垃圾回收器,既可以回收新生代也可以回收老年代,SunHotSpot1.6u14以上EarlyAccess版本加入了这个回收器,Sun公司预期SunHotSpot1.7发布正式版本。通过重新划分内存区域,整合优化CMS,同时注重吞吐量和响应时间。杯具的是Oracle收购这个收集器之后将其用于商用收费版收集器。因此目前暂时没有发现哪个公司使用它,这个放在之后再去研究吧。
整理一下新生代和老年代的收集器。
新生代收集器:
Serial (-XX:+UseSerialGC)
ParNew(-XX:+UseParNewGC)
ParallelScavenge(-XX:+UseParallelGC)
G1 收集器
老年代收集器:
SerialOld(-XX:+UseSerialOldGC)
ParallelOld(-XX:+UseParallelOldGC)
CMS(-XX:+UseConcMarkSweepGC)
G1 收集器
内存溢出和内存泄露的区别
1、内存溢出
内存溢出指的是程序在申请内存的时候,没有足够大的空间可以分配了。
2、内存泄露
内存泄露指的是程序在申请内存之后,没有办法释放掉已经申请到内存,它始终占用着内存,即被分配的对象可达但无用。内存泄露一般都是因为内存中有一块很大的对象,但是无法释放。
从定义上可以看出,内存泄露终将导致内存溢出。
注意,定位虚拟机问题内存问题的时候第一步就是要判断到底是内存溢出还是内存泄露,前者好判断,跟踪堆栈信息就可以了;后者比较复杂一点,一般都是老年代中的大对象没释放掉,要通过各种办法找出老年代中的大对象没有被释放的原因。
并行和并发的区别
这两个名词都是并发编程中的概念,在谈论垃圾收集器的上下文语境中,可以这么理解这两个名词:
1、并行Parallel
多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态
2、并发Concurrent
指用户线程与垃圾收集线程同时执行(但并不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个CPU上
Minor GC和Full GC的区别
1、新生代GC(Minor GC)
指发生在新生代的垃圾收集动作,因为大多数Java对象存活率都不高,所以Minor GC非常频繁,一般回收速度也比较快
2、老年代GC(Major GC/Full GC)
指发生在老年代的垃圾收集动作,出现了Major GC,经常会伴随至少一次的Minor GC(但并不是绝对的)。Major GC的速度一般要比Minor GC慢上10倍以上
Client模式和Server模式的区别
部分商用虚拟机中,Java程序最初是通过解释器对.class文件进行解释执行的,当虚拟机发现某个方法或代码块运行地特别频繁的时候,就会把这些代码认定为热点代码Hot Spot Code(这也是我们使用的虚拟机HotSpot名称的由来)。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器叫做即时编译器(Just In Time Compiler,即JIT编译器)。JIT编译器并不是虚拟机必需的部分,Java虚拟机规范并没有要求要有JIT编译器的存在,更没有限定或指导JIT编译器应该如何去实现。但是,JIT编译器性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键指标之一。
解释器和编译器其实和编译器各有优势:
1、当程序需要迅速启动和执行的时候,解释器可以先发挥作用,省去编译的时间,立即执行
2、在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获取更高的执行效率
我们使用的HotSpot中内置了两个JIT编译器,即C1编译器和C2编译器,默认采用的是解释器和一个编辑器配合的方式进行工作。HotSpot在启动的时候会根据自身版本以及宿主机器的硬件性能自动选择运行模式,比如会检测宿主机器是否为服务器、比如J2SE会检测主机是否有至少2个CPU和至少2GB的内存。
1、如果是,则虚拟机会以Server模式运行,该模式与C2编译器共同运行,更注重编译的质量,启动速度慢,但是运行效率高,适合用在服务器环境下,针对生产环境进行了优化
2、如果不是,则虚拟机会以Client模式运行,该模式与C1编译器共同运行,更注重编译的速度,启动速度快,更适合用在客户端的版本下,针对GUI进行了优化
有两种方法查看虚拟机是运行在Client模式下还是Server模式下:
1、在程序命令行运行“java -version”命令,查看的是你本地安装的虚拟机是信息

2、比如我们用Eclipse或者MyEclipse运行程序,一般使用的都是工具自带的JRE,虚拟机并不是本地安装的虚拟机。这时候怎么办呢,可以通过在程序中运行下面的语句来查看虚拟机信息
System.out.println(System.getProperty("java.vm.name"));
我这里的运行结果是
Java HotSpot(TM) 64-Bit Server VM
当然要改变虚拟机运行的模式也可以,只需要改jvm.cfg就可以了。我们可以从以下几个地方找到jvm.cfg:
1、32位的JDK的文件路径是 JAVA_HOME/jre/lib/i386/jvm.cfg
2、64位的JDK的文件路径是 JAVA_HOME/jre/lib/amd64/jvm.cfg
3、MyEclipse在 .../Common/binary/com.sun.java.jdk.win32.x86_64_1.6.0.013/jre/lib/amd64/jvm.cfg
目前64位只支持Server模式,文件内容都是一样的,上面的注释不去管它,剩下的就是这些:
-server KNOWN -client IGNORE -hotspot ALIASED_TO -server -classic WARN -native ERROR -green ERROR
由于我的电脑装的是64位JDK,所以是“-client INGORE”。同时支持Server模式和Client模式的,应该是“-server KNOWN”和“-client KNOWN”,一般只需要变更这两个配置的先后顺序即可,但是前提是JAVA_HOME/jre/bin目录下同时存在server和client两个文件夹,分别对应着各自的虚拟机,缺少一个,切换后就会报错。