书籍简介

- 名称:Go语言实战
- 作者: 威廉·肯尼迪 (William Kennedy) / 布赖恩·克特森 (Brian Ketelsen) / 埃里克·圣马丁 (Erik St.Martin)
- 内容:Go语言结合了底层系统语言的能力以及现代语言的高级特性,旨在降低构建简单、可靠、高效软件的门槛。本书向读者提供一个专注、全面且符合语言习惯的视角。Go语言实战同时关注语言的规范和实现,涉及的内容包括语法、类型系统、并发、管道、测试,以及其他一些主题。
第1章 关于Go语言的介绍
传统语言使用继承来扩展结构——Client 继承自 User, User 继承自 Entity, Go 语言与此不同,Go 开发者构建更小的类型——Customer 和 Admin,然后把这些小类型组合成更大的类型。
第4章 数组切片
如何计算长度和容量
函数 append 会智能地处理底层数组的容量增长。在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25%的容量。随着语言的演化,这种增长算法可能会有所改变。
设置长度和容量一样的好处
内置函数 append 会首先使用可用容量。一旦没有可用容量,会分配一个新的底层数组。这导致很容易忘记切片间正在共享同一个底层数组。一旦发生这种情况,对切片
进行修改,很可能会导致随机且奇怪的问题。对切片内容的修改会影响多个切片,却很难找到问题的原因。
如果在创建切片时设置切片的容量和长度一样,就可以强制让新切片的第一个 append 操作创建新的底层数组,与原有的底层数组分离。新切片与原有的底层数组分离后,可以安全地进行后续修改。
// 其长度和容量都是 5 个元素
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
// 对第三个元素做切片,并限制容量
// 其长度和容量都是 1 个元素
slice := source[2 : 4: 4]
// 向 slice 追加新字符串
slice = append(slice, "Kiwi")
fmt.Println(source) // [Apple Orange Plum Banana Grape]
fmt.Println(slice) // [Plum Banana Kiwi]
range
range 创建了每个元素的副本,而不是直接返回对该元素的引用
// 创建一个整型切片
// 其长度和容量都是 4 个元素
slice := []int{10, 20, 30, 40}
// 迭代每个元素,并显示值和地址
for index, value := range slice {
fmt.Printf("Value: %d Value-Addr: %X ElemAddr: %X
",
value, &value, &slice[index])
}
结果为
Value: 10 Value-Addr: C4200180A8 ElemAddr: C420014200
Value: 20 Value-Addr: C4200180A8 ElemAddr: C420014208
Value: 30 Value-Addr: C4200180A8 ElemAddr: C420014210
Value: 40 Value-Addr: C4200180A8 ElemAddr: C420014218
因为迭代返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以 value 的地址总
是相同的。要想获取每个元素的地址,可以使用切片变量和索引值。
在函数间传递切片
在 64 位架构的机器上,一个切片需要 24 字节的内存:指针字段需要 8字节,长度和容量字段分别需要 8字节。由于与切片关联的数据包含在底层数组里,不属于切片本身,所以将切片复制到任意函数的时候,对底层数组大小都不会有影响。复制时只会复制切片本身,不会涉及底层数组。
第5章 Go语言的类型系统
接口
如果使用指针接收者来实现一个接口,那么只有指向那个类型的指针才能够实现对应的接口。如果使用值接收者来实现一个接口,那么那个类型的值和指针都能够实现对应的接口。
第6章 并发
并发与并行
并发( concurrency)不是并行( parallelism)。并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情,这些事情可能只做了一半就被暂停去做别的事情了。在很多情况下,并发的效果比并行好,因为操作系统和硬件的总资源一般很少,但能支持系统同时做很多事情。这种“使用较少的资源做更多的事情” 的哲学,也是指导 Go 语言设计的哲学。
如果希望让 goroutine 并行,必须使用多于一个逻辑处理器。 当有多个逻辑处理器时,调度器会将 goroutine 平等分配到每个逻辑处理器上。这会让 goroutine 在不同的线程上运行。不过要想真的实现并行的效果,用户需要让自己的程序运行在有多个物理处理器的机器上。否则,哪怕 Go 语言运行时使用多个线程, goroutine 依然会在同一个物理处理器上并发运行,达不到并行的效果。

无缓冲的通道
示意图
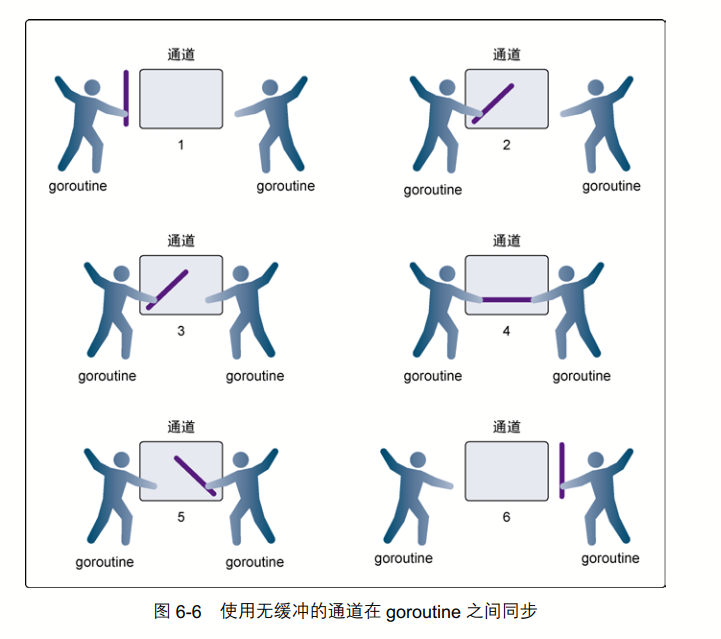
无缓冲的通道示意图
代码示例
// 这个示例程序展示如何用无缓冲的通道来模拟
// 2 个 goroutine 间的网球比赛
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
// wg 用来等待程序结束
var wg sync.WaitGroup
func init() {
rand.Seed(time.Now().UnixNano())
}
// main 是所有 Go 程序的入口
func main() {
// 创建一个无缓冲的通道
court := make(chan int)
// 计数加 2,表示要等待两个 goroutine
wg.Add(2)
// 启动两个选手
go player("Nadal", court)
go player("Djokovic", court)
// 发球
court <- 1
// 等待游戏结束
wg.Wait()
}
// player 模拟一个选手在打网球
func player(name string, court chan int) {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
for {
// 等待球被击打过来
ball, ok := <-court
if !ok {
// 如果通道被关闭,我们就赢了
fmt.Printf("Player %s Won
", name)
return
}
// 选随机数,然后用这个数来判断我们是否丢球
n := rand.Intn(100)
if n % 13 == 0 {
fmt.Printf("Player %s Missed
", name)
// 关闭通道,表示我们输了
close(court)
return
}
// 显示击球数,并将击球数加 1
fmt.Printf("Player %s Hit %d
", name, ball)
ball++
// 将球打向对手
court <- ball
}
}
有缓冲的通道
示意图
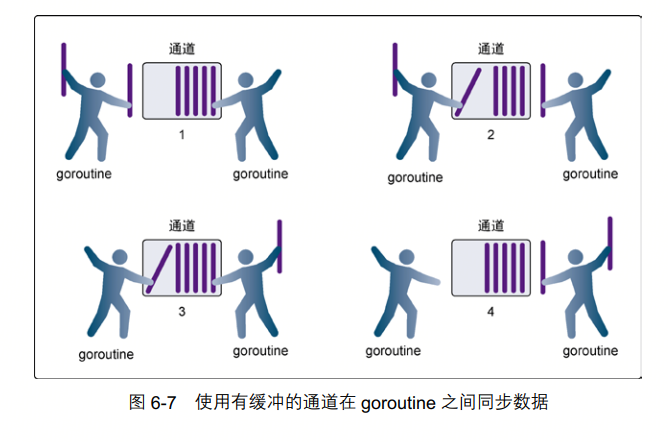
有缓冲的通道示意图
代码示例
// 这个示例程序展示如何使用
// 有缓冲的通道和固定数目的
// goroutine 来处理一堆工作
package main
import (
"fmt"
"math/rand"
"sync"
"time"
)
const (
numberGoroutines = 4 // 要使用的 goroutine 的数量
taskLoad = 10 // 要处理的工作的数量
)
// wg 用来等待程序完成
var wg sync.WaitGroup
// init 初始化包, Go 语言运行时会在其他代码执行之前
// 优先执行这个函数
func init() {
// 初始化随机数种子
rand.Seed(time.Now().Unix())
}
// main 是所有 Go 程序的入口
func main() {
// 创建一个有缓冲的通道来管理工作
tasks := make(chan string, taskLoad)
// 启动 goroutine 来处理工作
wg.Add(numberGoroutines)
for gr := 1; gr <= numberGoroutines; gr++ {
go worker(tasks, gr)
}
// 增加一组要完成的工作
for post := 1; post <= taskLoad; post++ {
tasks <- fmt.Sprintf("Task : %d", post)
}
// 当所有工作都处理完时关闭通道
// 以便所有 goroutine 退出
close(tasks)
// 等待所有工作完成
wg.Wait()
}
// worker 作为 goroutine 启动来处理
// 从有缓冲的通道传入的工作
func worker(tasks chan string, worker int) {
// 通知函数已经返回
defer wg.Done()
for {
// 等待分配工作
task, ok := <-tasks
if !ok {
// 这意味着通道已经空了,并且已被关闭
fmt.Printf("Worker: %d : Shutting Down
", worker)
return
}
// 显示我们开始工作了
fmt.Printf("Worker: %d : Started %s
", worker, task)
// 随机等一段时间来模拟工作
sleep := rand.Int63n(100)
time.Sleep(time.Duration(sleep) * time.Millisecond)
// 显示我们完成了工作
fmt.Printf("Worker: %d : Completed %s
", worker, task)
}
}
当通道关闭后, goroutine 依旧可以从通道接收数据,但是不能再向通道里发送数据。能够从已经关闭的通道接收数据这一点非常重要,因为这允许通道关闭后依旧能取出其中缓冲的全部值,而不会有数据丢失。从一个已经关闭且没有数据的通道里获取数据,总会立刻返回,并返回一个通道类型的零值。如果在获取通道时还加入了可选的标志,就能得到通道的状态信息。
第8章 标准库
编码/解码
type gResult struct {
GsearchResultClass string `json:"GsearchResultClass"`
UnescapedURL string `json:"unescapedUrl"`
URL string `json:"url"`
VisibleURL string `json:"visibleUrl"`
CacheURL string `json:"cacheUrl"`
Title string `json:"title"`
TitleNoFormatting string `json:"titleNoFormatting"`
Content string `json:"content"`
}
你会注意到每个字段最后使用单引号声明了一个字符串。这些字符串被称作标签( tag),是提供每个字段的元信息的一种机制,将 JSON 文档和结构类型里的字段一一映射起来。如果不存在标签,编码和解码过程会试图以大小写无关的方式,直接使用字段的名字进行匹配。如果无法匹配,对应的结构类型里的字段就包含其零值。