昨天回去想想,感觉还不满意,回去学习,改好了,哈哈,就是数据处理问题
哈哈,上优化代码
1 # #lanxing 2 import os #获取路径 3 4 import pyfofa #fofa登录库 5 import pandas as pd #读取csv表格库 6 import time #时间库 7 import csv #获取到的list数据保存到csv处理库 8 start=time.time() 9 def chax(): 10 email = '' #y邮箱 11 key = '' #fofa个人key 12 search_fofa = input("请输入你要搜索的特征 :") 13 # print(type(search_fofa)) 14 # print(search_fofa) 15 # search_fofa = 'domain="baidu.com"' 16 17 search = pyfofa.FofaAPI(email, key) 18 re_date = search.get_data(search_fofa, 1, "host,title,country_name,city,ip,port,server,protocol")['results'] #搜索请求,等到想要的数据 19 # print(re_date) 20 print(type(re_date)) 21 print("*************************开始爬取url***************************") 22 # for host,title,city in search.get_data('app="TP_LINK-路由器"',1,"host,title,city")['results']: 23 # print('标题:' + title, '城市:'+city, 'url :'+host) 24 25 name = ['网站', 'Title','国家', '城市', 'ip地址', 'port','Server','协议'] #csv表格列 26 #test = pd.DataFrame(columns=name, data=re_date) 27 # print(test) 28 # test.to_csv('C:/Users/lanxing/Desktop/fofa_url.csv', encoding='utf-8') 29 print("*************************请稍等,正在爬取中**********************") 30 with open('fofa1_url.csv','w',encoding='utf-8',newline='') as f: #写入 31 writer = csv.writer(f) 32 writer.writerow(name) 33 writer.writerows(re_date) 34 35 36 37 38 39 print("*************************爬取完成***************************") 40 41 chax() 42 end=time.time() 43 sd=end-start #end-start,程序运行所需时间 44 print("******************大佬,fofa信息查询完毕!*************************") 45 lj = os.path.dirname(__file__) #获取当前目录 46 print('获取到的数据保存在:'+lj + '目录下面') 47 print('查询耗时:',str(sd)+'s') #Python 不允许直接把数字和字符拼接在一起(如果拼在一起就会报标题显示的错误),把数字型的字符串,转化为字符型就可以了,即str()就可以
运行状态
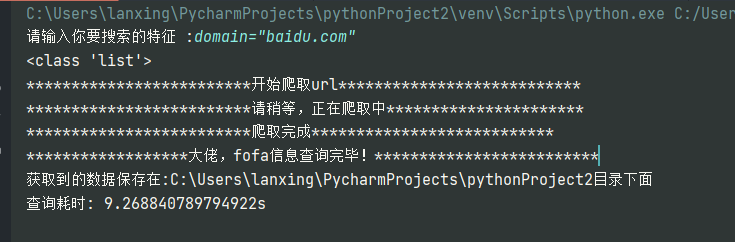
效果图
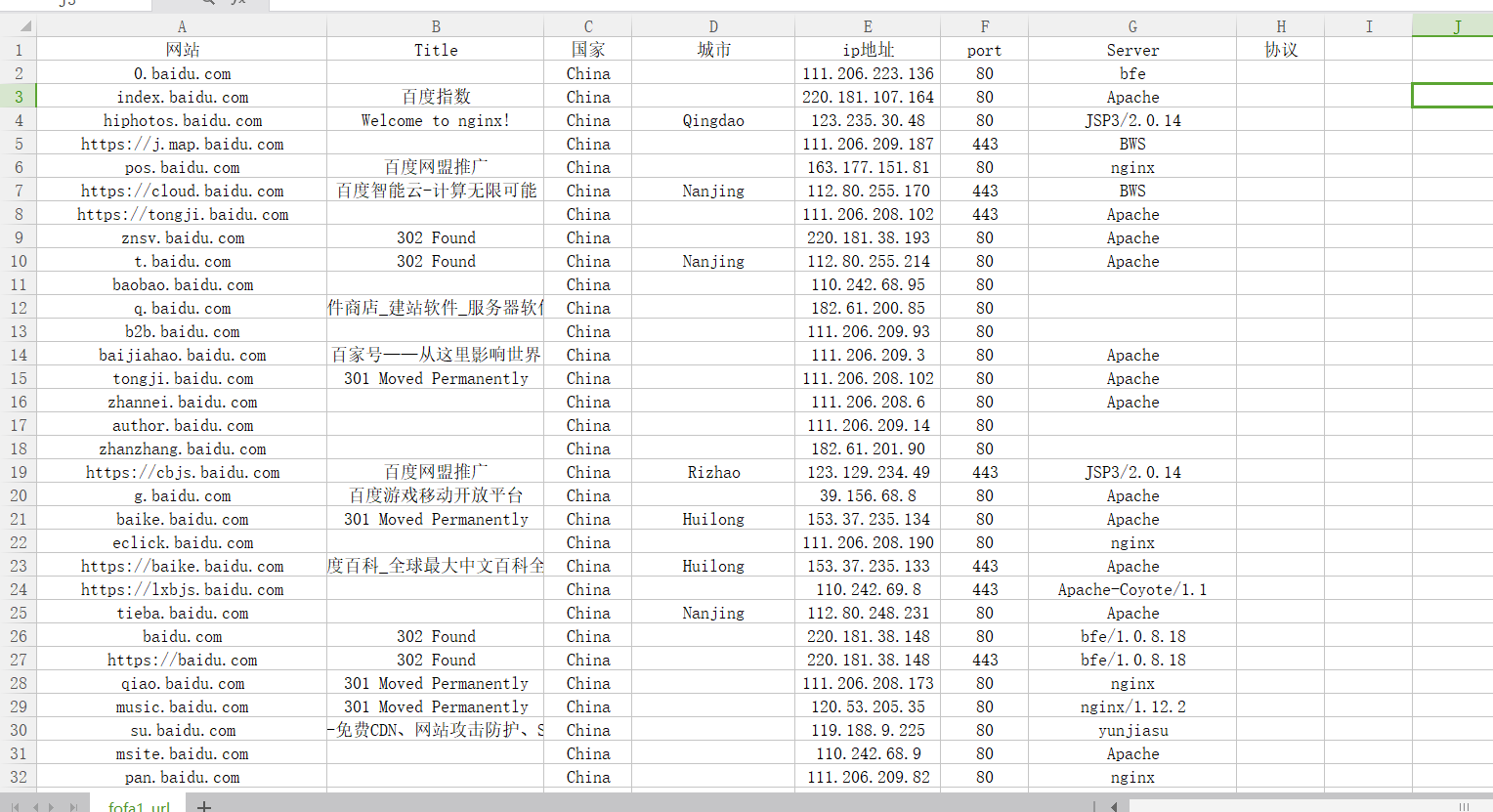
还不错,有待优化,等我去学习一下,再优化,做一个简易的GUI版本