一、 参考书《数据压缩导论(第4版)》Page 66
2、 利用程序huff_enc和huff_dec进行以下操作(在每种情况下,利用由被压缩图像生成的码本)。
(a) 对Sena、Sinan和Omaha图像时行编码。
给出以上每一试验得出的文件大小,并解释其差别。
答:
| 文件名 | 压缩前文件大小 | 压缩后文件大小 | 压缩比 |
| Sena | 64KB | 56.1KB | 87.66% |
| Sinan | 64KB | 60.2KB | 94.06% |
| Omaha | 64KB | 57KB | 89.06% |
4 、一个信源从符号集A={a1, a2, a3, a4, a5}中选择字母,概率为P(a1)=0.15,P(a2)=0.04,P(a3)=0.26,P(a4)=0.05,P(a5)=0.50。
(a) 计算这个信源的熵。
(b) 求这个信源的霍夫曼码。
(c) 求(b)中代码的平均长度及其冗余度。
答:(a) =1*0.15*(-log20.15)+1*0.04*(-log20.04)+1*0.26*(-log20.26)+1*0.05*(-log20.05)+1*0.50*(-log20.05)
=0.547
(b) 将概率按从大到小的顺序排列为:
P(a5)=0.50
P(a3)=0.26
P(a1)=0.15
P(a4)=0.05
P(a2)=0.04
对其进行划分:
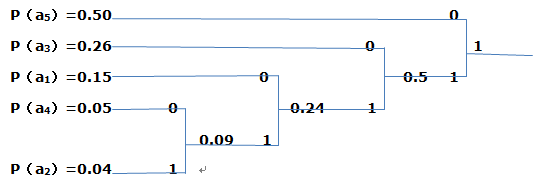
所以这个信源的霍夫曼码为:
a5 0
a3 10
a1 110
a4 1110
a2 1111
(c)平均长度: l=1*0.5+2*0.26+3*0.15+4*0.05+4*0.04
=1.83 (bit/pel)
冗余度:r=Hmax(x)-H(x)=logm-H(x)
=logm-H(x)
=1.83-0.547
=1.283(bit/pel)
5 一个符号集A={a1, a2, a3, a4,},其概率为P(a1)=0.1,P(a2)=0.3,P(a3)=0.25,P(a4)=0.35,使用以下过程找出一种霍夫曼码:
(a)本章概述的第一种过程:
(b)最小方差过程。
解释这两种霍夫曼码的区别。
答:(a) 1、将信号源的符号按照概率的大小按从大到小的顺序排列。
2、然后将出现概率最小的进行合并相加,并对其中的一个赋“1”,另一个赋“0”,相加得到的结果在与其它的比较。
3、重复“2”的过程直到最后两个符号的概率相加得1位置
(b) 将概率按从大到小的顺序排列为:
P(a4)=0.35
P(a2)=0.3
P(a3)=0.25
P(a1)=0.1
对其进行划分:
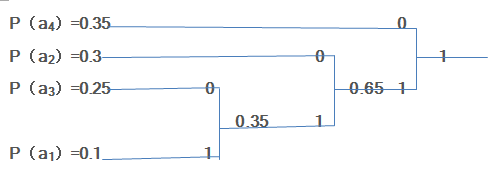
所以这个信源的霍夫曼编码为:
a4 0
a2 10
a3 110
a1 111
(b)最小方差:
因为
熵: H=-(0.1* log2*0.1+0.3* log2*0.3+0.25* log2*0.25+0.35* log2*0.35)
=0.568bits/symbol
平均码长:l=0.1*3+0.3*3+0.25*2+0.35*1
=1.85(bit/pel)
冗余度:r=Hmax(x)-H(x)=logm-H(x)
=logm-H(x)
=1.85-0.568
=1.282(bit/pel)
最小方差过程:
S2=0.1(3-1.282)2+0.3(3-1.282)2+0.25(2-1.282)2+0.35(1-1.282)2
=1.337
6 在配套的数据集中有几个图像和语音文件。
(a) 编写一段程序,计算其中一些图像和语音文件的一阶熵。
(b) 选择一个图像文件,并计算其二阶熵。试解释一阶熵与二阶熵之间的差别。
(c) 对于(b)中所用的图像文件,计算其相邻像素之差的熵。试解释你的发现。
答:(a)程序代码是老师提供的,由程序计算出文件中的一些图像和语音文件的一阶熵分别为:
|
文件名 |
一阶熵 |
| EARTH.IMG | 4.770801bit/字符; |
| GABE.RAM | 7.116338bit/字符; |
| BERK.RAW | 7.151537bit/字符; |
| OMAHA.IMG | 6.942426bit/字符; |
| SENA.IMG | 6.834299bit/字符; |
| SENSIN.IMG | 7.317944bit/字符; |
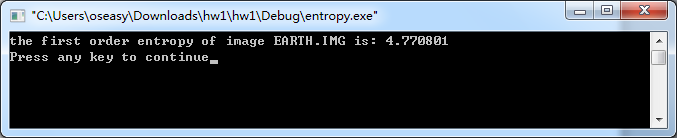

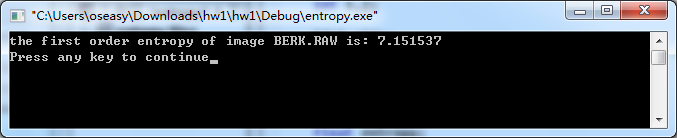
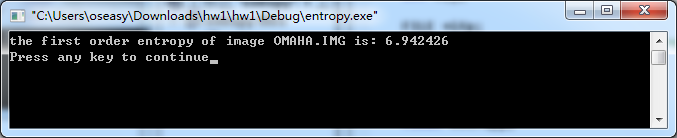


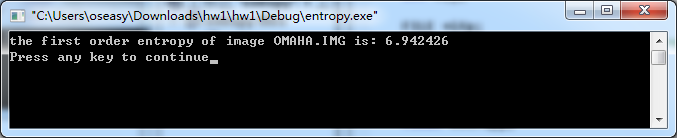
(b)选择图像文件OMAHA.IMG。其一阶熵为: 6.942426
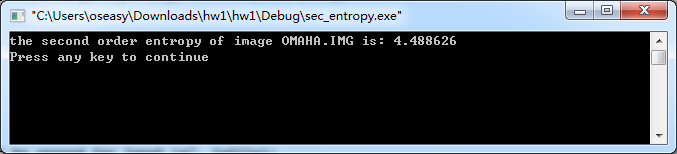
其二阶熵为:4.488626
从上面我们可以清楚的看到,该图片的一阶熵和二阶熵比较,二阶熵要小,因
此文件经过二阶压缩处理要比一阶压缩处理要好,减少存储空间。
(c)图像文件OMAHA.IMG的差分熵为:6.286834

由(b)中可知差分熵位于一阶熵和二阶熵之间,但与一阶熵比较接近,因此我们如果要选择压缩方
法的话我觉得因该选择二阶熵