一 我们得知道为何会有Redis
简单的一句话就是: 现在是大数据时代,一般的数据库(Mysql等关系型数据库)无法进行分析处理了。
意识就是,使用数据库进行存 储数据,由于数据库持久化数据主要是面向磁盘的,但是磁盘的读/写比较慢。当遇到高并发下,往往需要瞬时的进行大量的读/写要求,这是极其容易让数据库宕机。
从而,就引进了一种新的技术NoSQL技术(非关系型数据库),其实也是一种简单的数据库,主要是基于内存的数据库,也提供一定的持久化功能。
而,Redis(KV键值对类型)和MongoDB(文档型数据库)是当前失眠上用的最为广泛的NoSQL。
NoSQL= not onli sql (不仅仅时SQL),泛指非关系型数据库的。
其实为何会有NoSQL的出现了,就是为了适应现在社会的 3V+3高
3V是指
- 海量 Volume
- 多样Variety
- 实时Velocity
3高是指
- 高并发
- 高可扩 (随时水平拆分,机器不够了,可以扩展机器)
- 高性能 (保证用户体验和产品的性能)
二 Redis的优点
1.运行速度快,因为是基于ANSIC语言编写的。
2.读写速度快,因为是基于内存读写的,而不是磁盘。 -------------- Redis一秒可以写8万次,读取11万
3数据结构较简单,因为只有6中数据类型
三Redis能做什么
①内存存储、持久化,内存中是断电即失,所以持久化很重要(有两种,rdb,aof)
③发布订阅系统,也就是简单的消息队列系统
④地图信息分析
⑤计时器,计数器(浏览量)
四 Redis一般是基于Linux使用的
安装在了cd /usr/local/redis/bin
redies的启动(后端模式):
先进入:cd /usr/local/redis/bin
再启动: ./redis-server redis.conf
查看是否启动:ps -aux | grep redis
启动客户端:
先进入:cd /usr/local/redis/bin
再启动:./redis-cli

redis的停止:
方法1:在Linux命令行下输入 ./redis-cli shutdown
方法2:在Redis客户端里面输入shutdown
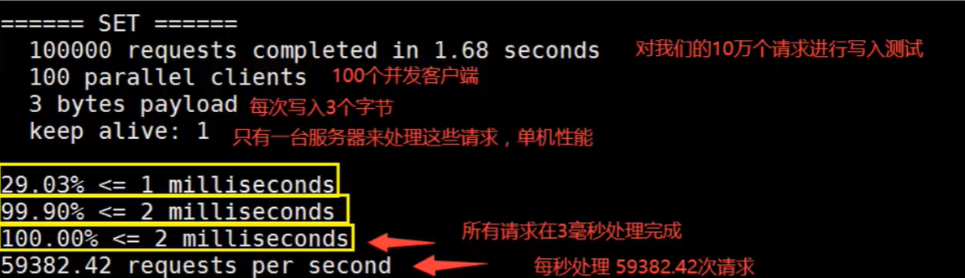
性能测试
①100个并发连接 100000请求
在linux开启redis后,输入
结果分析:
五 Redis的基本知识
- 默认使用第0个数据库,可以使用select进行切换数据库: select 3 这样来切换到第几个数据库。
- 查看所有的key ---- key *
- 清除当前数据库直接输入 flushdb即可
- 清空所有数据库 flushAll
- redis是单线程的,是基于内存操作,cpu不是redis的性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽
- 用一句话来概括Redis--- Redis是一种基于内存的,以键值存储来存储六种其数据类型的非关系数据库(NoSQL)的一种,并且提供了一定的持久化功能(rdb,aof),还支持一些事务,发布订阅消息模式,主从复制等功能
问:为何Redis是单线程的,运行速度还是很快呢?
这儿有两个误区:
误区1:高性能的服务器一定是多线程的-❌
误区2:多线程(CPU会上下切换), 所以会比单线程快-❌
那为何Redis运行速度不慢呢,是因为Redis是将所有的数据全部存储在内存中的,所有说使用单线程去操作就是最快效率最高的,而多线程会cpu的切换,这是耗时操作!!!
总结:对于内存系统来说,如果没有上下文切换效率就是最高的!多次读写都在一个cpi上,在内存情况下,这是最优方案。
六 Redis 的五大数据类型
可能会有人好奇了,为何上面说是六大数据类型,这儿却是五大呢,因为前五个用的较多。
注意:这儿的数据类型指的是值的类型(Redis的数据是以键值形式存在的)
这儿列出六个数据类型:String(字符串), List(列表),set(集合), hash(哈希结构), zset(有序集合), tHyperLogLog(基数)
| 数据类型 | 数据类型存储的值 | 说明 |
| String(字符串) | 可以保存字符串,整数,浮点数 |
堆字符串进行操作,比如增加字符串或者求字串; 如果是整数或者浮点数,可以实现计算,比如自增等 |
| List(列表) | 它是一个链表,每一个节点都包含一个字符串 |
Redis支持从链表的两端插入或者弹出节点,或者通过偏移对它进行剪裁; 可以读取一个或多个节点; 根据条件来删除或查找节点等 |
| set(集合) | 是一个收集器,但是是无序的去重的,里面每一个元素都是一个字符串 |
可以新增,读取,删除单个元素; 检测一个元素是否在集合中; 计算它和其它集合的交集,并集和差集等; 随机从集合中读取元素 |
| hash(哈希结构) | 类似于Map,是一个键值对形式的无序不去重(只要键不同)列表 |
可以增删改查单个键值对,也可以 获取所有的键值对 |
| zset(有序集合) |
是一个有序集合,可以包含字符串,整数,浮点数,分值 各个值的排序是按照大小来决定的 |
可以增删改查元素,根据分值的范围或者成员来获得对于的元素 |
| HyperLogLog(基数) | 用来计算重复的值,以确定存储的数量 | 只提供基数的运算,不提供返回功能 |
具体的Redis的六大类型的使用及其功能,请见另一个文章: