原文链接:http://www.tuicool.com/articles/3MjURj
“全世界的网络连接起来,英特纳雄耐尔就一定要实现。”受益于这个时代,互联网从小众的角落走到了历史的中心舞台。如果无远弗届的互联网将把会整个世界转化成了一个巨型网络,那么就让这一切首先从淘宝开始吧。
最近我们试图将淘宝的交易记录中的物品和人组成一个对分网络(bipartite network)。对于这个网络的,我们有许多有趣的问题:这个网络中节点的度分布会是什么样?在这个网络中,是否也存在“权威节点”?是否也有所谓的“小世界现象”。工欲善其事必先利其器,在回答这个问题前,如何存储这个图(上亿个节点,几十亿条边),如何快速地将图算法应用到这个图上是我们小组在遇到的不可回避的问题。
通过搜索和查新,我们知道基于spark的graphX和spark原生的bagel都提供了对于图操作的API。我们使用pageRank做了两者的性能比较,发现只要图中节点的边数呈现幂律分布,当节点数比较大时(3000W以上),在graphx上的pageRank每次超步(superstep)的时间可以稳定地低于基于spark的原生图算法框架bagel。为了知其所以然,我们花了2天时间,阅读了两篇文章和其他的相关材料,动手写了代码,做了测试,结合网上的查找和自己的思考,对于背后的原因做了一些了解和思考。
- 幂律分布和自然图(natural graph)
这段主要来自:http://www.360doc.com/content/10/0124/11/8411_14273195.shtml
现实生活中存在各种不同的现象,可用不同的数学上的分布来描述它。

比如我们以身高为横坐标,以取得此身高的人数为纵坐标,可画出一条钟形分布曲线,这种曲线两边衰减地极快,特别高的人和特别矮的人都是比较少见的;这种分布可以用正态分布或泊松分布来描述它。如左上图的泊松分布
但是有些分布的差距记为悬殊,比如收入为横坐标,以不低于该收入值的个体数或概率为纵坐标,可绘出一条向右偏斜得很厉害的曲线(包括梧苇在内的大多数人都在横轴接近0的地方无语飘过,囧)。这种“长尾”分布表明,绝大多数个体的尺度很小,而只有少数个体的尺 度很大(想想胡润财富榜),而且相当大个体的尺度可以在很宽的范围内变化(比如资产亿元已经可以算是巨富,但是往上,还有资产十亿,百亿,千亿的富豪),这种波动往往可以跨越多个数量级。
上面说的这个现象可以用数学语言描述为:不小于某个特定值x的概率与x的常数次幂亦存在简单的反比关系,它的公式为:P[X≥k]~x^(-k),这就是所谓的Pareto定律。这是一种幂律分布,还有很多其他形式的幂律分布,它们数 学上是等价的,它们的通式可写成y=c*x^(-r)。
1.2:自然图(natural graph)
对于图来说, 节点的度定义为与该节点相连接的节点的个数
如果每个点都是随机的和其它的点建立连接,那么生成的网络的度分布符合泊松分布这种网络称之为随机网络,度值比平均值高许多或 低许多的节点,都十分罕见。因为大家都是随机的,所以某个点突出的可能性很小。
但是随机网络只能说是理论上的网络,实际生活中的网络是出于种种现实的目的建立的。比如微博,姚晨能成为大V,背后有一个分工严谨的团队在进行运作。对于一个现实中的网络而言,当新的节点加入的时候,总是会优先连接那些在网络中最耀眼的节点。比如新用户加入微博,总是先关注那些知名大v。网络中的节点和新节点建立连接的概率与这个节点已有的连接数正相关,网络的度分布则是幂律分布,符合这种特点的网络叫无尺度网络。它的节点度值相差悬殊,往往可以跨越几个数量级,是一种极端“专制”的网络,它有个学名叫无标度网络。它节点的度符合上文提到的公式:y=c*x^(-r),因为这种网络在自然界,显示生活中的存在如此普遍,无标度网络又经常被称为natural graph(自然图)。
下面是两种图的直观展示(左图是节点的度符合泊松分布,差别不大。右图是节点的度符合幂律分布,差别悬殊,这种就是natural graph)
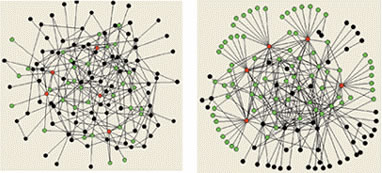
1.3:举个举个例子理解公式
对于上文反复提到的节点的度分布符合幂律分布,节点度分布可表示为y=c*x^(-r),我觉得可以这样理解的:以微博用户的粉丝个数为例,如果粉丝数100个以上的用户有100w,粉丝数200个以上的用户40w,如果微博用户的粉丝数分布符合幂律分布,那么有如下方程组:
100 0000 = c*100^(-r)
解上述方程组,c=4.4*e8,r=1.32。这个公式在这里的实际应用是:
基于上面的计算,我们可以推算出,粉丝数大于10w的用户数是 c*10 0000^(-r) 大约是108人,粉丝数大于100w的用户数是6人。同时,这个例子也说明了natural graph的自相似性,可以通过部分数据对于整个图的情况进行推测。
像Internet、电子邮件网络、电影演员合作网络、引文关系网络的节点的度都符合幂律分布,数据倾斜是很严重的现象。所以如果要对于现实中存在的”图”进行图计算,需要针对于无标度网络进行一些存储,通信等优化,graphx就对于有这种特点的图进行优化。
1.4:Network science网络科学
上述提到的图在网络科学中被称为网络。阿里有在交易,沟通,认证的过程中沉淀了大量的数据,其中不少都可以以网络的形式表现出来。比如旺旺的好友关系和聊天记录,又比如淘宝中的SNS元素,而淘宝的点击,收藏,购买的流水转变为二分图,更是一个庞大的巨型网络。我们做巨型网络的预研主要是想要从网络科学的角度来对于这些图进行一些分析,希望搞清从购买记录来看用户是否会体现出社区性(community detection),优质商品被用户发觉,接受,传播的过程中是否有“小世界”的现象。
对于一个网络,我们通常有这些维度可以作为调查的入手点:
点的度数(average degree ):对于无向网络而言,就是每个边的平均节点数,有向网络又分为出度和入度。点的度数分布和消息的传播概率P直接决定了一个消息是否可以传遍全网络,还是在传播过程中湮灭了。
平均路径(average path):对于某个点而言,计算它到网络中的所有其他点的最短路径,求和,然后除以网络中点的个数。这个值直接说明了这个点到网络中的其他节点要多少步。而对于网络的所有点的平均路径分布可以判断这个网络是均匀的(各点的平均路径大致相同), 带中心区域的(有的点平均路径大,属于边缘区,反之则为中心区)。
网络半径:所有点的计算到其他点的距离,其中的最大距离就是网络半径。MAX(shortest path)
对于点i的聚合系数(clustering cofficient)=点i的邻居间的边数/点i的邻居数。这个系数说明了i所在的社群是否是活跃的,有凝聚力的。这个特性在聚划算的效果预估,营销策略策划上有很大的应用前景。
在以上基础上,所谓的小集团(clique)是我们关注的一个重点。所谓的clique在这个是一个完全子图(sub complete graph),在这个子图中,所有点都相互连接,一些在全网络中不能大范围传播的信息会在这个小集团中反复传播,沉淀下来,称为一种类似方言,行话之类的东西。对于淘宝而言,淘宝旅游,淘宝家装就比较容易出现这样的现象,是否是这样,我们要通过对于对应的网络进行计算后进行验证。
- 巨型图的存储方式(vertex cut 和edge cut)
2.1:vertex cut和edge cut
在正式的工业级的应用中,图的规模极大,上百万个节点是经常出现的。(在研究的过程中,找到了一个包含各种真实图数据集的检索页http://snap.stanford.edu/data/ ,可以作为以后一些实验的基础。)为了提高处理速度,我们希望可以用分布式的方式来存储,处理一个图。
在最早期的图计算的框架中,估计是受到所谓:think like vertex的思维的影响,使用的是edge-cut(边分割)的存储方式,如下图a:

这个存储的思想是每个点vertex的数据都只存储在一台机器上,如例子中的点A,点A的完整数据只存放在机器1上,B的完整数据只存放在机器2上,对于边AB而言,在机器1上,存放的是A的数据和B的索引地址(即B的数据在哪台机器上),在机器1上,存放的是B的数据和A的索引地址。这样存储的好处是对于读取某个点的数据时,只要到一台机器上就可以了。缺点是当要读取一条边数据时,如果这条边的两个点在不同的机器上,那么就会引起跨机器的通信开销。当这个图是无标度网络时,这个开销将抵消节点数据只存储一份带来的好处(后面将详细说说)
graphx借鉴powerGraph,使用的是vertexcut(点分割)方式存储图。如上图b:这种存储方式特点是任何一条边只会出现在一台机器上,每个点有可能分布到不同的机器上,例如上图的点B就被分配到了2,3两条机器上。当点被分割到不同机器上时,是相同的镜像,但是有一个点作为主点(master),其他的点作为虚点(ghost),当点B的数据发生变化时,先更新点B的master的数据,然后将所有更新好的数据发送到B的ghost所在的所有机器,更新B的ghost。这样做的好处是在边的存储上是没有冗余的,而且对于某个点与它的邻居的交互操作,只要满足交换律和结合律,比如求邻居权重的和,求点的所有边的条数这样的操作,可以在不同的机器上并行进行,只要把每个机器上的结果进行汇总就可以了,网络开销也比较小。代价是每个点可能要存储多份,更新点要有数据同步开销。
2.2:把图按照vertex-cut或edge-cut的存储的算法步骤
把图存储大体上有3中方法balanced p-way edge-cut,Balanced p-way Vertex-Cut,Greedy Vertex-Cuts
2.2.1:balanced p-way edge-cut
对于图G而言,按照balanced p-way edge cut的方式存储到p台机器上是这样做:先将vertex的ID平均hash到p台机器上,每个点都会唯一对应p台机器中的一个。然后将边一条一条加到集群上。遇到一条边的两个点在不同机器上的情况时,在两个机器上分别建立缺少的那个点的ghost
2.2.2:Balanced p-way Vertex-Cut
对于图G而言,按照balanced p-way edge cut的方式存储到p台机器上是这样做:先将edge的ID(比如使用两个端点的vertexId来合成出一个边的id)平均hash到p台机器上,每个条都会唯一对应p台机器中的一个。然后对于图中的每个点,如果它在多台机器上都有,选取一个点作为master,其他点作为ghost,将点的data分发到有这个点的所有机器上。
2.2.3:Greedy Vertex-Cuts
对于图G而言,按照Greedy Vertex-Cuts的方式存储到p台机器上是这样做:对于任意一条边e而言,设它的两个端点是a,b。点a被分配的机器集合是A(a),点a被分配的机器集合是A(a)。对于下面4种情况是这样操作的:
a:A(a)和A(b)的交集不为空,那么就把e分配到交集的机器上
b:A(a),A(b)的交集为空,但是A(a),A(b)都不为空,那就把e分配到A(a)和A(b)的并集中已经分配到的边数最小的那台机器上。
c:如果a已经被分配过,b没有分配,那么就把e分配到有a的机器上,反之亦然
d:a,b都没有被分配过,那就把e分配到负载最小的机器上。
简单地说,这样做的目的就是让点尽可能分配得紧密一点,一个指定的点分配到包含这个点的边最多的那台机器上。
整体而言,Greedy Vertex-Cuts载入速度最慢,但是最终占用的空间最小,数据局部性效果最好,可以在随后的计算中带来速度上的收益,如下面的两张图


2.3对于vertex-cut,edge-cut的量化分析:
这段内容算有关graphx的知识体系中最困难的部分了,花了不少时间看懂了大概,但还是有不少遗留的问题,公式的推导以后打算录个视频,详细说说,但是这里可以先写一下
如果我们将一个图的点随机的分配到P台机器上,那么图中的任意一条边被切断的可能性是

的指数分布的时候,它的每个点所在的那些边被切断的可能性是:

对于这个公式我是这样理解的D[v]是节点v的度,即有多少边从点v中伸展出来。每一条边被切断的可能性是1-1/p,所以一个点伸出去的边被切断的数目是(1-1/p)*E[ D[ v ] ],于是问题就转换为一个图的点的度符合系数是 的指数分布的时候,平均每个点的度是多少呢?
初步的看法是这样的D[v]表示的是点v度,如上面例子中的点c被分配到了2,3两台机器上,那么D[c]={2,3},E[ D[ v ] ]表示每个点被分配到的机器的期望数,E[D[v] = ]
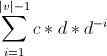
Balanced p-way Vertex-Cut
对于Balanced p-way Vertex-Cut而言,要尽可能的使得存储的空间小,相当于是要解决这个问题:

5.3中A(v)是点v被分配到的机器的集合,如上面例子中,点c被分配到了2,3两台机器上,于是A(v) = {2,3} ,|A(v)|=2。等式5.3表示的是要让每平均个点被分配到机器数尽量小,这样可以减少额外的存储。那么我把所有点都分配到同一台机器上不就可以了吗?当然没有这么简单。同时,又要符合5.4,对于p台机器中的任何一台,它被分配到的边的个数不能大于 
对于Randomized Vertex Cuts来说,每个点被重复的次数是

这个公式可以这样理解:一张图被分配到p个机器上,一个点v它的度数是D[v],它不被分配到某个指定的机器的可能性是(1-1/p)^D[v],所以它被分配到这个机器上的可能性是1-(1-1/p)^D[v],一共有P台机器,故这个点可能的重复次数是p*(1-1/p)^D[v],于是5.5式得证。
将图的指数分布带入,可以得到使用Balanced p-way Vertex-Cut存储一个边的度数分布符合幂律分布的图时,每个点要被存储的拷贝数是:

从5.12可以知道当 越小,也就是指数分布得越倾斜的时候,根据点分割得到的存储方式相对于边分割而言,优势越明显。
- 测试结果

左图可见随着a的变小(即点的连接数分布曲线变得陡峭起来),使用vertex-cut来存放图,额外的存储随着机器的增加比较平缓地增长。
右图中纵坐标是edge-cut的存储通信成本/vertex-cut的存储通信成本,曲线越在上方,说明vertex-cut的改进越显著,如图可见可见随着a的变小,所用机器越少,vertex-cut的性能改善越明显。
- 总结和遗留的问题
我觉得graphx的改进再一次说明了要优化一个数据项目,一定要结合具体的数据分布来进行。同时,跨学科的知识也很重要,尤其是数学,统计和计算机的结合。
4.1:在做graphx的过程中比较深入地了解了natural graph的特性,并且进一步地,接触到一个领域叫network science: http://en.wikipedia.org/wiki/Network_science 这里主要说一个对于一个动态的图,可以从哪些角度来思考,有那些指标和问题比如图密度,图半径,图中的关键节点,小集群现象等等,对于它的理解可以让我们把社交化做得更好,对于如何优化信息在社交网络上的传播有指导意义。在搞graphx的过程中对于它有了点了解,打算把它加到taobaoSNS的数据挖掘中。
4.2:在编写graphx和bagel代码的过程中,对于spark的运行机制有了一点了解,这个打算以后再写一篇详细地记录一下。
4.3:目前对于图的edge-cut,vertex-cut的存储开销分析较多,但是对于计算中它们不同的通信量没有触及,以后再做测试的时候,不但要看时间,而且要看看监控中的其他指标,对于性能做更全面的分析
- 资料汇总
关于幂律详细:http://www.360doc.com/content/10/0124/11/8411_14273195.shtml
关于幂律简单介绍: http://zh.wikipedia.org/zh-cn/%E9%BD%8A%E5%A4%AB%E5%AE%9A%E5%BE%8B
各种图数据集的检索页 http://snap.stanford.edu/data/
network science: http://en.wikipedia.org/wiki/Network_science
关于巨型图存储的简单介绍:PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs 第5章
关于巨型图存储的深入介绍:GraphBuilder: A Scalable Graph ETL Framework
PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs
GraphX A Resilient Distributed Graph System on Spark annotated
GraphBuilder: A Scalable Graph ETL Framework