
提交Spark程序的机器一般一定和Spark集群在同样的网络环境中(Driver频繁和Executors通信),且其配置和普通的Worker一致
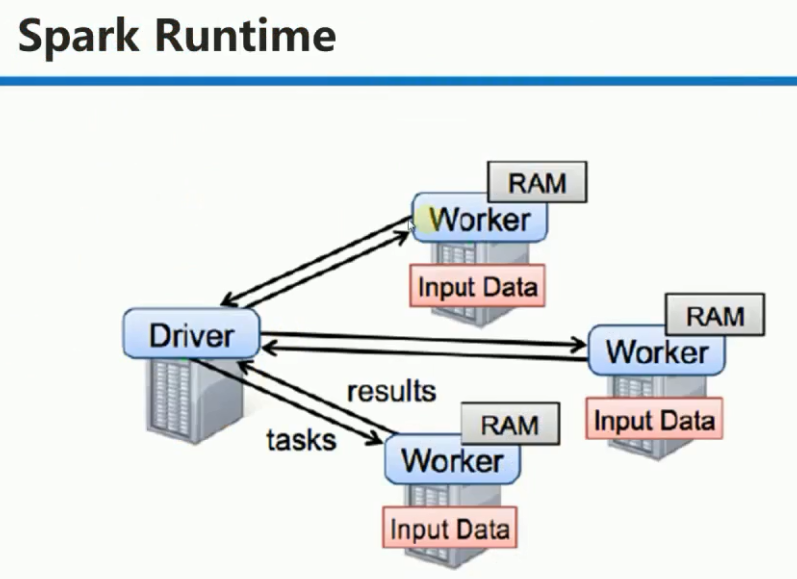
1. Driver: 具有main方法的,初始化 SparkContext 的程序。Driver运行在提交Spark任务的机器上。
Driver 部分的代码: SparkConf + SparkContext
SparkContext: 创建DAGScheduler, TaskScheduler, SchedulerBackend, 在实例化的过程中Register当前程序给Master。 Master接
受注册,如果没有问题,Master会为当前程序分配AppId并分配计算资源
Cluster Manager:获取集群资源的外部服务。Spark应用程序的运行不依赖于Cluster Manager。
Master: 接受用户提交的程序并发送指令给Worker,让其为当前程序分配计算资源,每个Worker所在节点默认为当前程序分配一个
Executor,在Executor中通过线程池并发执行。
可以通过以下三种途径得到要为当前程序分配多少计算资源:
(1). spark-env.sh 和 spark-default.sh 中的配置信息
(2) submit 提供的参数
(3) 程序中,conf里定义的
Worker:不运行程序的代码,它管理当前节点的内存、CPU等计算资源,并接收Master的指令来分配具体的计算资源Executor(在新的进程中分配)
Worker只有在启动时才会向Master发送状态报告。
以下情况会触发Job: 1. Action 2. checkpoint 3. 排序
Spark 提交任务概述:

注意: Master 给 Worker 发送指令,要求其为Application 分配资源时,并不关心具体的资源是否已经分配。也就是说Master发指令后就记录了资源的分配,
以后其它客户端提交程序的时候就不会再分配该资源了。其弊端: 是其它要提交的程序可能分配不到本来可以分配的资源。
优势:在 Spark 分布式系统弱耦合的基础上最快的执行程序(否则如果Master要等到Worker最终分配成功后才通知 Driver的话,就会造成Driver阻塞,不
能够最大化并行计算资源的使用率)。默认情况下,Spark中的任务是排队的,也就是说同时只有一个任务在执行,所以其弊端并不明显。