1. 下载: wget http://mirrors.shu.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
2. 解压后,假设 $SQOOP_HOME 为解压后的文件夹的位置,进入 $SQOOP_HOME/conf 目录, 运行: cp sqoop-env-template.sh sqoop-env.sh
3. 修改 sqoop-env.sh 中的内容,根据文件里的注释,设置相应的内容。如:
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/opt/programs/hadoop-2.7.3
其它的,如 HBASE_HOME和 HIVE_HOME , 如果没用到,则不需要设置。
4. 在 $SQOOP_HOME/bin 目录下运行: sqoop help 会得到所有的命令。(注:如果在第3步中,有些值没有设置,运行时会报一些 warning 的信息,这是正常的)。
5. 查看某个命令的详细信息(如:import): sqoop import --help
各个参数详细点的说明见: https://blog.csdn.net/zleven/article/details/53781111
6. 查看 mysql 中某个表(注意:需要将 mysql 的数据库连接的 jar 包复制到 lib 目录下):
bin/sqoop eval --connect jdbc:mysql://localhost:3306/sqoop_test --username sqoop --password 123456 --query "select * from student"
7. 根据关系型数据库中的表创建 Hive 表(注:只会创建表结构,不会复制数据)
bin/sqoop create-hive-table --connect jdbc:mysql://localhost:3306/sqoop_test --table student --username sqoop --password 123456 --hive-table hive_student
8. import 命令
主要作用是将关系型数据库中的数据导入到 HDFS 文件系统中(或者 HBase/hive 中),不管是导入到 HBase 中还是导入到 hive 中,都需要先导入到HDFS中,然后导入到最终的位置,一般情况下,只会采用将关系型 数据库的数据导入到 HDFS 或者 Hive 中,不会导入到 HBase中。
import 命令导入到 HDFS 中默认采用 ‘,’ 进行分割字段值,导入到 hive 中默认采用 'u0001' 来进行分割字段值,如果有特殊的分割方式,我们可以通过参数指定。
imprt 命令导入到 hive 的时候,会先在 /user/${user.name} 文件夹下创建一个同关系型数据库表名相同的文件夹作为中间文件夹,如果该文件夹存在,则会报错。错误如下:
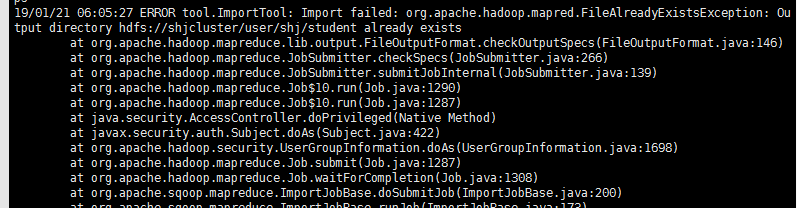
在导入时的命令中加入 --delete-target-dir 参数,可以避免这一错误。
(1) 将 mysql 表中的数据导入到 hive 的 hive_student 表(这个表如果不存在 Hive中, 会自动创建),
sqoop import --connect jdbc:mysql://localhost:3306/sqoop_test --table student --username sqoop --password 123456 --delete-target-dir --hive-import --hive-database default --hive-table hive_student --fields-terminated-by ','
我运行这个命令时,出现下面的错误:
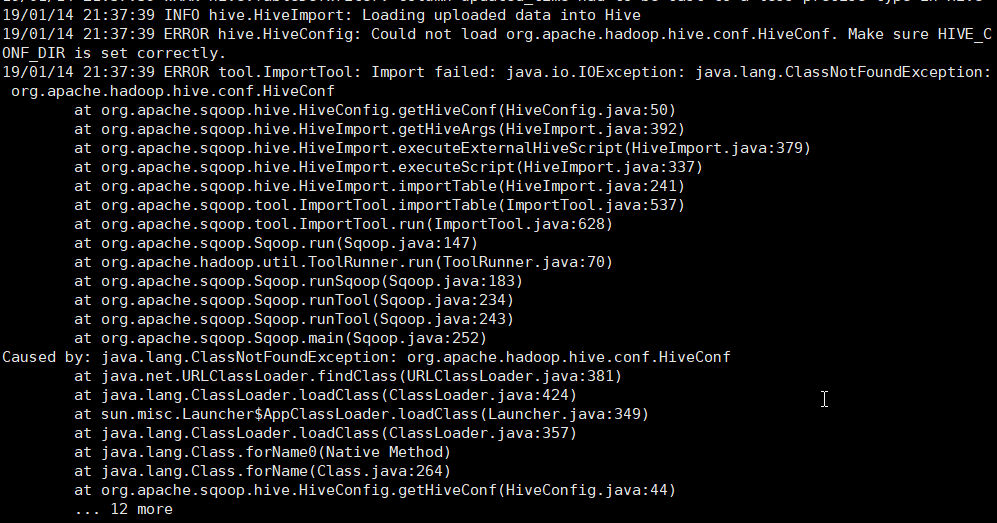
需要把 hive/lib/hive-exec*.jar 拷贝到 sqoop/lib/ 下。
(2) 再次运行上面的命令,会把数据库中所有的记录再插入 Hive 表,Hive 表中会有两份记录。如果想要先清空 Hive 中的数据,需要加一个参数 --hive-overwrite
注意: 对于同一个 Hive,导入命令中的 --fields-terminated-by 的值必须相同,否则,Hive 表中记录的值会是 NULL。如下图所示:

(3) 如果只是想把数据库表中的某几个字段导入到 Hive 表中,可以执行:
$ sqoop import --connect jdbc:mysql://bigdata1:3306/sqoop_test --username sqoop --password 123456 --query "select id,name,age from student where $CONDITIONS" --target-dir /sqoop --hive-import --hive-database default --hive-table hive_student1 -m 1
使用 --query 时, 必须同时指定 --target-dir 。最后的 -m 1 意思是指定一个 MapperReduce,默认值 2 。如果 值不为 1 的话,需要同时增加 --split-by 参数,指定按哪一个 column 进行分隔。