本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
作业要求
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
2.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
作业题目:爬取电影《何以为家》影评并进行综合分析
大数据案列:
1.准备本地数据文件
对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacases/datasets文件夹,具体的步骤为:
① cd /usr/local② sudo mkdir bigdatacase③ cd bigdatacase/④ sudo mkdir dataset⑤ cd dataset/
效果如下:
其次,我们把gggg.csv文件放到下载这个文件夹中,具体步骤如下:
① sudo cp /home//下载/gggg.csv /usr/local/bigdatacases/datasets/ #把gggg.csv文件拷到刚刚所创建的文件夹中

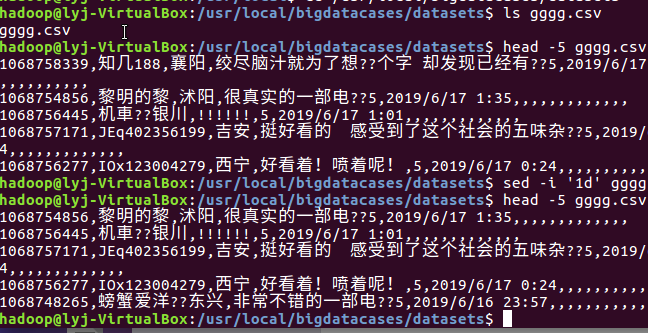
2.在本地查看数据集
head -5 gggg.csv #查看这个文件的前五行

3.数据集的预处理---删除没必要的属性
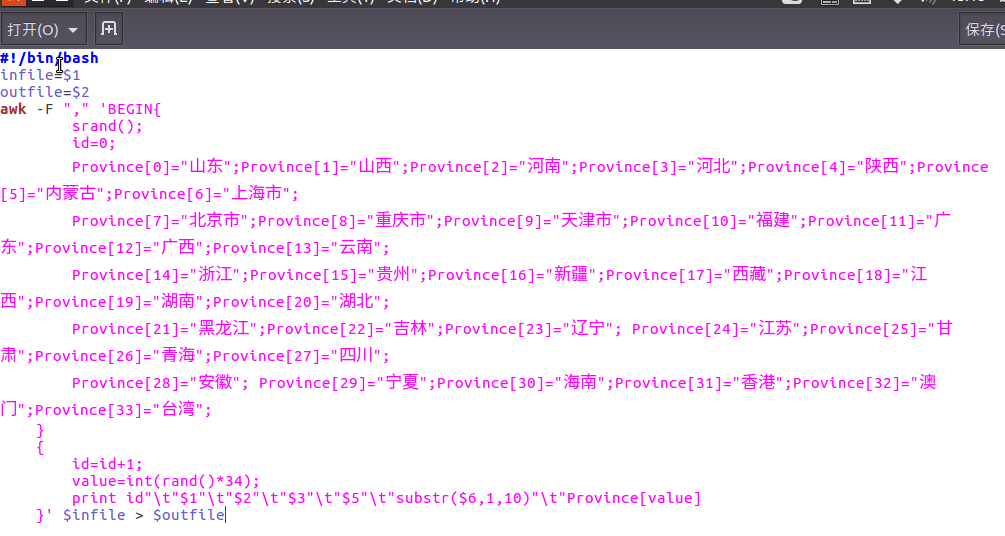
4.建立一个脚本文件,对数据进行预处理
具体用一个pre_deal.sh文件,用gedit pre_deal.sh编辑脚本文件
效果如下:
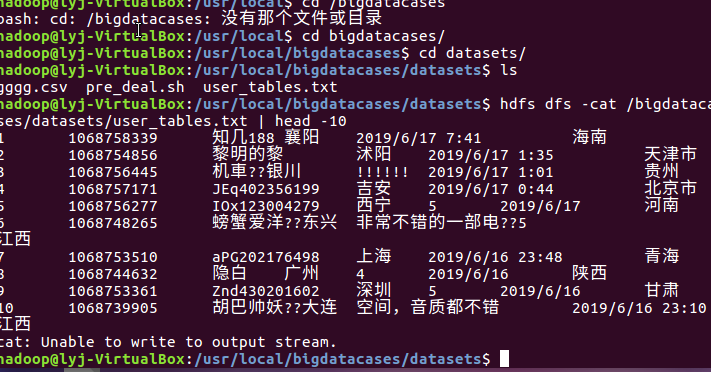
5.准备本地数据文件,并将爬虫大作业产生的csv文件上传到HDFS,再一次对csv文件进行处理,生成无标题文本文件
① hdfs dfs -mkdir -p /bigdatacases/datasets #在hdfs上新建/bigdatacases/datasets
② hdfs dfs -ls /

③ hdfs dfs -put ./gggg.csv /bigdatacases/datasets #把本地文件gggg.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacases/datasets #查看

⑤ hdfs dfs -cat /bigdatacases/datasets/gggg.csv | head -5 #查看hdfs中gggg.csv的前五行
6.把数据准备好之后,启动mysql hadoop hive 把hdfs中的数据导入到数据仓库hive中
启动mysql和hadoop:


启动hdfs:

7.把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database lyj; -- 创建数据库dblab:

② use lyj;

③ create external table lyj(id string,username string,comment string,pingf string,time string) row format delimited fields terminated by ' ' stored as textfile location '/bigdatacases/datasets/'; -- 创建表lyj并把hdfs中/bigdatacases/datasets/目录下的数据加载到表中
④ select * from cucn limit 10; -- 查看lyj中前10行的数据
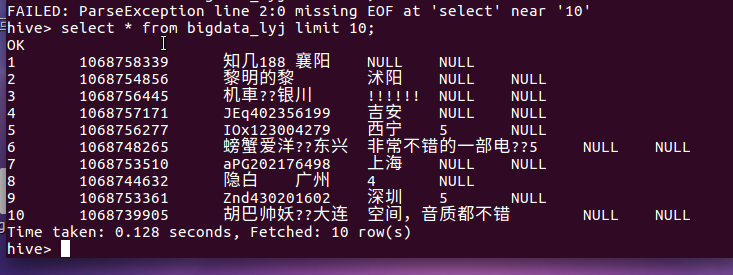
用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析):
查询评分为5的电影:
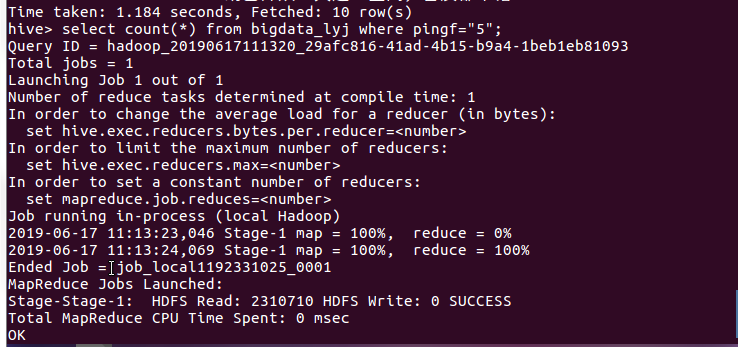
分析:在所爬数据中,评分为5的电影有6782条,在所爬的数据中占比一半,由此看出评分为5的比例是相当高的
查询评分为4的电影:
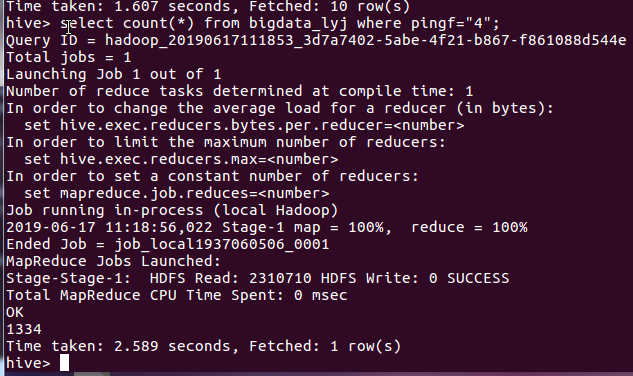
分析:评分为4的电影达到1334条,在所爬数据中占比不大,但是也是唯二上1000条评分的一个评分区间。
查询评分为3的电影:
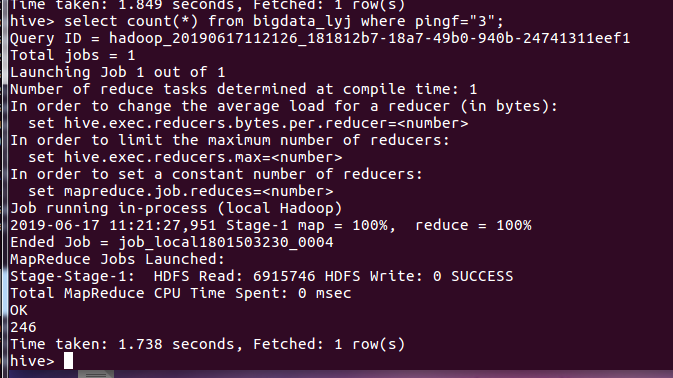
分析:评分为3的电影条数为246条,占据小部分,在整体评分中的比例很少。
查询评分为2的电影:

分析:评分为2的电影有75条,在10000多条评论中占比不重。
查询评分为1的电影:

分析:如图所示,评分为1的电影评价有45条,该电影属于差评的评分相当少。
查询电影的平均分:

分析:电影的平均分在4.44左右,在电影5分评分中占比例88.8%,单纯在电影评分中属于优秀的水平,从平均分分析出《何以为家》电影质量相当好。
电影评分调查的综合分析:
电影简介:黎巴嫩一个小城镇里的法庭,12岁的男孩扎因因为持刀伤人被判入狱,不过在律师的支持下,扎因起诉自己的父母,是因为父母不能为他提供保护和安全感。扎因的父母很穷,负担不起抚养孩子们的费用,这意味着扎因不能获得身份证,所以扎因是一个没有资格获得护照的黑户,无法去学校上学,甚至在紧急情况下也无法在医院获得救助。
1.电脑原因,我的电脑不能顺利打开我在教室做的hadoop,显示不能为虚拟电脑Ubuntu打开一个新任务,最后都无法打开,是用教室电脑完成。
2.爬取数据不够多,在爬取过程中,当请求过于频繁时,服务器会拒绝连接,实际上是服务器的反爬虫策略,在每个请求间增加延时0.1秒,尽量减少请求被拒绝,如果被拒绝,则0.5秒后重试,
因此没有爬取全部的电影评论,而是截取了其中的一万多条数据,未做到无限接近实际情况。
3.create创建表中有不少null的项,可能是属性类型的错误,后来改了之后得到解决。
4. 尽管可能座过数据清洗,但可能还会存在脏数据的情况。电脑允许的情况下可以通过增大数据量来减少这种误差。
心得体会:本学期在老师的带领下,学习更了解大数据方面的知识了,包括爬虫可视化方面的知识和hadoop方面的知识,在老师的帮助下,安装Ubuntu,hive,hadoop,等等完成这次作业,其中还复习了数据库的知识,在Ubuntu上完成了对数据库的操作,这感觉很棒,还可以解决一些基本而又实际的问题---如爬取影评,令我获得了相关的学习能力,感觉很不错。