爬了一下腾讯漫画的网页,因为腾讯漫画中的国漫是非常多的,也想看看国漫的近况:
url:http://ac.qq.com/Comic/all/search/time/page/1
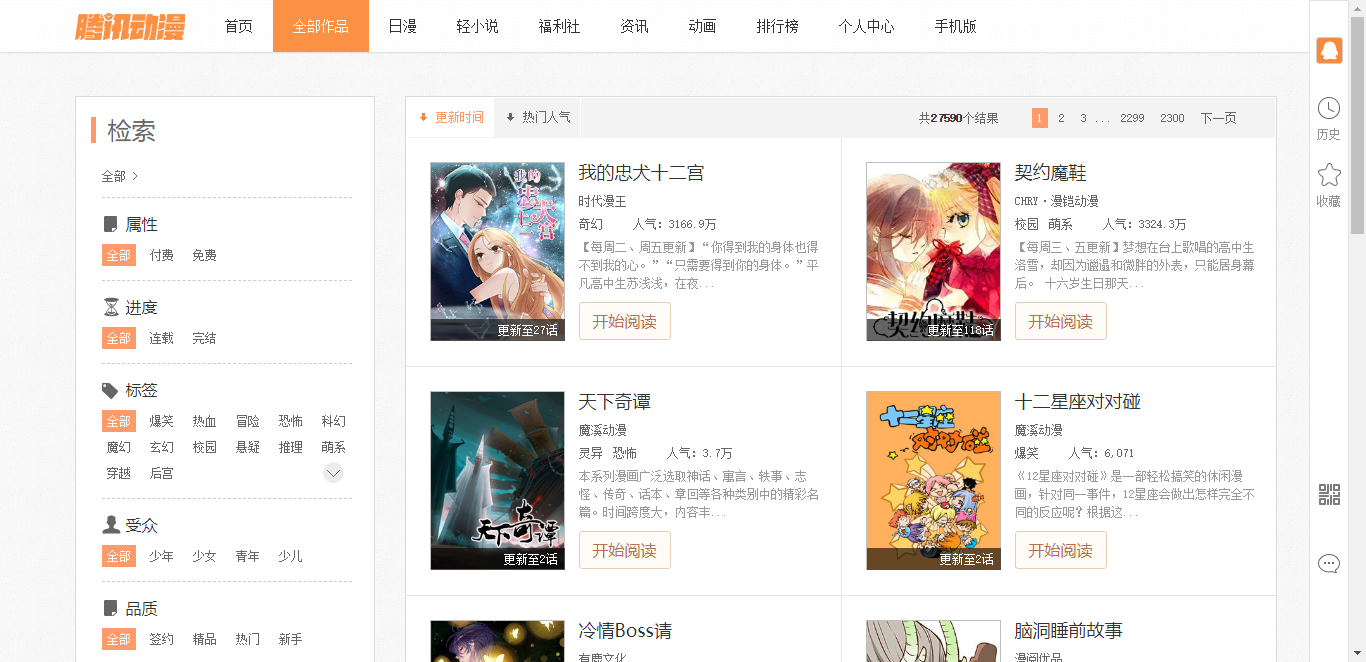
实现过程:
1、获取腾讯漫画上面的“作者”,“人气”,“状态”元素
def getCartoonDetail(cartoonUrl):
resd = requests.get(cartoonUrl)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
# print(cartoonUrl)
cartoons = {}
p1 = soupd.select('.works-intro-digi')[0]
p2 = soupd.select('.works-score.clearfix')[0]
p3 = soupd.select('.works-cover.ui-left')[0]
# print(p3)
# 作者
cartoons['作者'] = p1.select('.first')[0].text.lstrip('作者:').replace('xa0', " ")
#人气
# cartoons['人气'] = p2.select('.ui-text-orange')[0].text.replace('xa0'," ")...
#状态
cartoons['状态'] = p3.select('.works-intro-status')[0].text.replace('xa0'," ")
# + cartoons['人气'] + ' '
writeCartoonDetail(cartoons['作者'] + ' ' + cartoons['状态'] + '
')
return cartoons
2、从漫画中的列表页中提取所有漫画
def getListPage(pageUrl):
res = requests.get(pageUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
cartoonlist = []
for cartoon in soup.select('.ret-works-info'):
if len(cartoon.select('.ret-works-title.clearfix')) > 0:
a = cartoon.select('a')[0].attrs['href']#链接
a1 = 'http://ac.qq.com'
url = a1 + a
# print(url)
cartoonlist.append(getCartoonDetail(url))
# print(cartoonlist)
return cartoonlist
3、从尾页列表页中获取总的漫画列表页数
def getPageN():
res = requests.get('http://ac.qq.com/Comic/all/search/time/page/2300')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
p = soup.select('.ret-page-wr.mod-page')[0]
n = 2300
# n = int(soup.select('.current')[0].text)
# print(n)
return n
4、获取详情并保存在execl文档和记事本中
def writeCartoonDetail(content):
f=open('t.txt', 'a', encoding='utf-8')
f.write(content)
f.close()
cartoontotal = []
pageUrl = 'http://ac.qq.com/Comic/all/search/time/page/1'
cartoontotal.extend(getListPage(pageUrl))
# print(pageUrl)
print(cartoontotal)
n = getPageN()
# print(n)
for i in range(2, 2299):
pageUrl = 'http://ac.qq.com/Comic/all/search/time/page/{}'.format(i)
cartoontotal.extend(getListPage(pageUrl))
# print(cartoontotal)
# print(cartoontotal)
cartoonsList = {}
for c in cartoontotal:
# print(c)
cartoonsList['作者'] = c['作者']
# cartoonsList['人气'] = c['人气']..
cartoonsList['状态'] = c['状态']
print(cartoonsList)
df = pandas.DataFrame(cartoontotal)
print(df)
df.to_excel('t.xlsx', encoding='utf-8')
5、下载wordcloud,将爬到的数据读取并制成词云图
def ToDict():
f = open("t.txt", "r", encoding='utf-8')
str = f.read()
stringList = list(jieba.cut(str))
title_dict = {}
for i in stringSet:
title_dict[i] = stringList.count(i)
return title_dict
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
title_dict = ToDict()
graph = np.array(title_dict)
font = r'C:WindowsFontssimhei.ttf'
backgroud_Image = plt.imread("C:UsersAdministratorDesktop ext.jpg")
wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image)
WordCloud(background_color='white',max_words=500,font_path=font)
wc.generate_from_frequencies(title_dict)
plt.imshow(wc)
plt.axis("off")
plt.show()

解释分析:由以上这张词云图,我们可以看到,腾讯漫画中的大多数漫画是处于连载中的,而且在其中,有着不少小说家的名字,如天蚕土豆,唐家三少等,暗示有名小说进军漫画界并且有着很高人气,而且国内产业对于漫画的支持也是很高,如其中的触漫,开源动漫等大公司都有不少作品在其中。
问题及解决方法:主要还是词云的问题,之前是Pycharm提示需要安装Visual C++ Build Tools,但是因为本人使用的校园网网速极差,下载了很久却没见成功,于是就用了第二个方法:
下载wordcloud-1.4.1-cp36-cp36m-win32.whl,然后在cmd中,用cd指令打开到文件目录下,
pip install wordcloud-1.4.1-cp36-cp36m-win32.whl
pip install wordcloud
完成安装。
另外在爬去网站的信息是,有些元素的class是两个单词,则需要在其中加点,才能爬取:
soupd.select('.works-score.clearfix')[0]
完整代码:
import requests
import re
from bs4 import BeautifulSoup
import pandas
import jieba
def getCartoonDetail(cartoonUrl):
resd = requests.get(cartoonUrl)
resd.encoding = 'utf-8'
soupd = BeautifulSoup(resd.text, 'html.parser')
# print(cartoonUrl)
cartoons = {}
p1 = soupd.select('.works-intro-digi')[0]
p2 = soupd.select('.works-score.clearfix')[0]
p3 = soupd.select('.works-cover.ui-left')[0]
# print(p3)
# 作者
cartoons['作者'] = p1.select('.first')[0].text.lstrip('作者:').replace('xa0', " ")
#人气
# cartoons['人气'] = p2.select('.ui-text-orange')[0].text.replace('xa0'," ")...
#状态
cartoons['状态'] = p3.select('.works-intro-status')[0].text.replace('xa0'," ")
# + cartoons['人气'] + ' '
writeCartoonDetail(cartoons['作者'] + ' ' + cartoons['状态'] + '
')
return cartoons
def getListPage(pageUrl):
res = requests.get(pageUrl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
cartoonlist = []
for cartoon in soup.select('.ret-works-info'):
if len(cartoon.select('.ret-works-title.clearfix')) > 0:
a = cartoon.select('a')[0].attrs['href']#链接
a1 = 'http://ac.qq.com'
url = a1 + a
# print(url)
cartoonlist.append(getCartoonDetail(url))
# print(cartoonlist)
return cartoonlist
def getPageN():
res = requests.get('http://ac.qq.com/Comic/all/search/time/page/2300')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
p = soup.select('.ret-page-wr.mod-page')[0]
n = 2300
# n = int(soup.select('.current')[0].text)
# print(n)
return n
def writeCartoonDetail(content):
f=open('t.txt', 'a', encoding='utf-8')
f.write(content)
f.close()
cartoontotal = []
pageUrl = 'http://ac.qq.com/Comic/all/search/time/page/1'
cartoontotal.extend(getListPage(pageUrl))
# print(pageUrl)
print(cartoontotal)
n = getPageN()
# print(n)
for i in range(2, 2299):
pageUrl = 'http://ac.qq.com/Comic/all/search/time/page/{}'.format(i)
cartoontotal.extend(getListPage(pageUrl))
# print(cartoontotal)
# print(cartoontotal)
cartoonsList = {}
for c in cartoontotal:
# print(c)
cartoonsList['作者'] = c['作者']
# cartoonsList['人气'] = c['人气']..
cartoonsList['状态'] = c['状态']
print(cartoonsList)
df = pandas.DataFrame(cartoontotal)
print(df)
df.to_excel('t.xlsx', encoding='utf-8')
def ToDict():
f = open("t.txt", "r", encoding='utf-8')
str = f.read()
stringList = list(jieba.cut(str))
title_dict = {}
for i in stringSet:
title_dict[i] = stringList.count(i)
return title_dict
from PIL import Image,ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud,ImageColorGenerator
title_dict = ToDict()
graph = np.array(title_dict)
font = r'C:WindowsFontssimhei.ttf'
backgroud_Image = plt.imread("C:UsersAdministratorDesktop ext.jpg")
wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image)
WordCloud(background_color='white',max_words=500,font_path=font)
wc.generate_from_frequencies(title_dict)
plt.imshow(wc)
plt.axis("off")
plt.show()