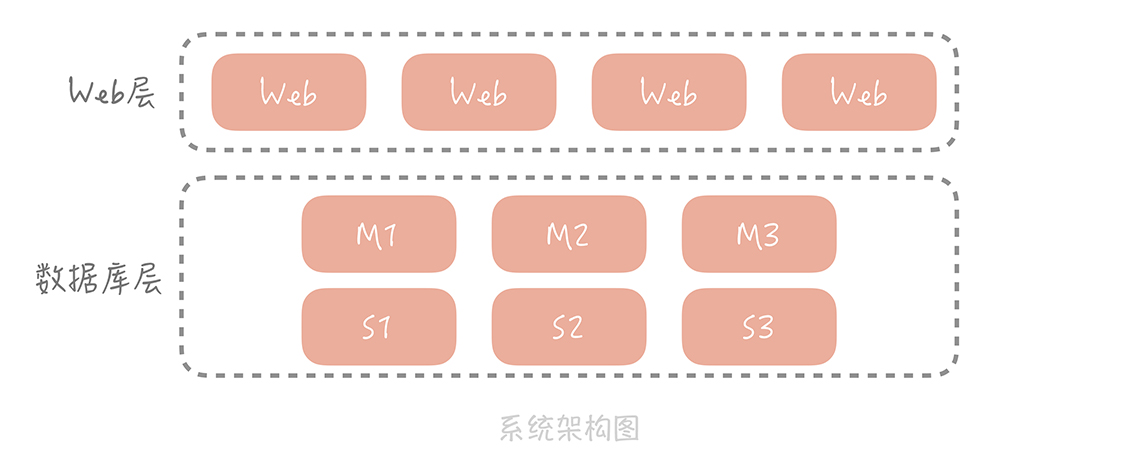
从整体上看,数据库分了主库和从库,数据也被切分到多个数据库节点上。但随着并发的增加,存储数据量的增多,数据库的磁盘 IO 逐渐成了系统的瓶颈,我们需要一种访问更快的组件来降低请求响应时间,提升整体系统性能。这时我们就会使用缓存。
缓存的不足
首先,缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性。
旦当业务场景读少写多时或者没有明显热点时,比如在搜索的场景下,每个人搜索的词都会不同,没有明显的热点,那么这时缓存的作用就不明显了。
其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,我们可以考虑使用较短的过期时间或者手动清理的方式来解决。
其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,我们可以考虑使用较短的过期时间或者手动清理的方式来解决。再次,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。因此,我们在使用缓存的时候要做数据存储量级的评估,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案。同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据。最后,缓存会给运维也带来一定的成本,运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。
缓存可以有多层,比如上面提到的静态缓存处在负载均衡层,分布式缓存处在应用层和数据库层之间,本地缓存处在应用层。我们需要将请求尽量挡在上层,因为越往下层,对于并发的承受能力越差;缓存命中率是我们对于缓存最重要的一个监控项,越是热点的数据,缓存的命中率就越高。
那么,当你在实际工作中碰到“慢”的问题时,缓存就是你第一时间需要考虑的。
缓存和缓冲区的区别,缓存是一个临时备份,为了弥补设备读取速度的不足;缓冲区是一个临时的写入点,作为高速和低俗设备的缓冲