编译器对关联容器的实现有两个版本,上一节总结了以红黑树做为基础的实现版本,这一节总结以哈希表(hash table,散列表)为底部结构的实现版本。
一、Hashtable简单介绍
Hashtable相比红黑树版本来说简单的多,但是内存占用来说大于红黑树,Hashtable把每一个要放入的元素折射成一个数值,在内存完全足够的情况下,需要的空间大小是sizeof(元素)*2的32次方,也就是说每个元素都要有4g*当前元素大小的空间,当放入元素时元素编号是多少就放入对应编号的位置,但实际上内存不可能有这么充足,所以我们就会面临一个问题,元素多空间少,此时我们放入时就要拿当前元素编号除以空间大小得到余数,元素就放到余数对应的编号位置,接下来会带来一个问题,发生碰撞(多个元素要放入的位置相同),这个时候早期设计者就会再次设计一系列的算法,遵循先来后到的原则,后到的经过算法挪到别的位置上去,有碰撞就再次设计新的算法再强制分开
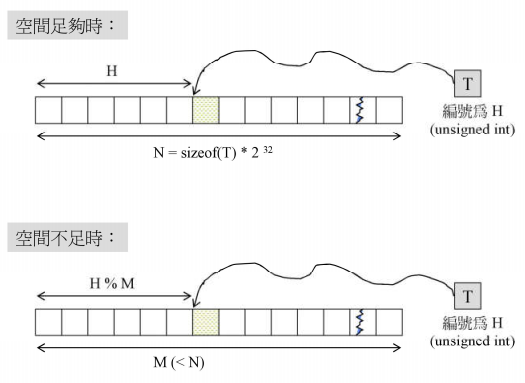
由于Hashtable的设计理念就是要快速的查找和搜寻,现在确把大量的时间花在处理碰撞的情况上,显然效率太低下,所以后来新做法:把需要碰撞处理的元素直接让它像链表一样串起来(separate chaining分离链表法)
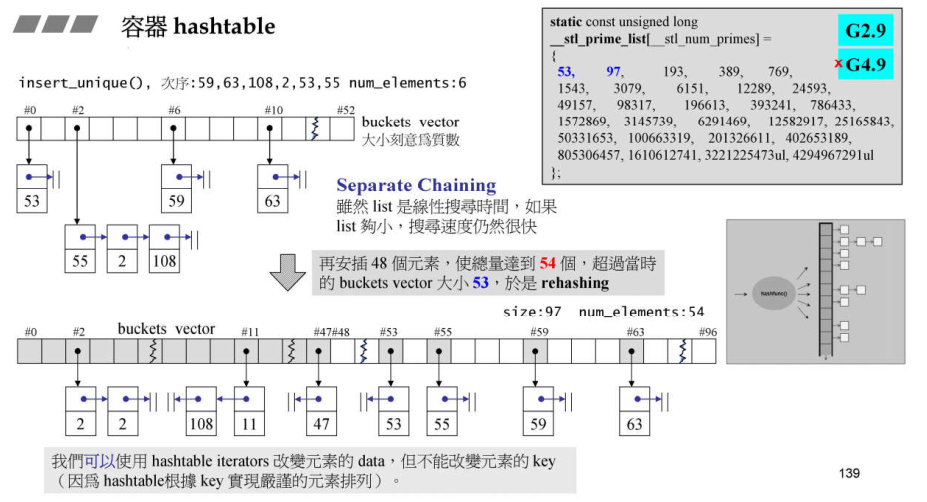
注意:为了防止其中某一个链表过长,就需要在合适时间打散所有元素重新排列,我们把初始的hashtable空间叫做篮子(bucket),当我们放入的元素个数大于篮子个数时(gunc初始篮子个数为53),就要扩充篮子个数,扩充数量为当前篮子个数2倍附近的一个质数(比如:53扩充到97),然后将所有元素重新从头开始放入新篮子。

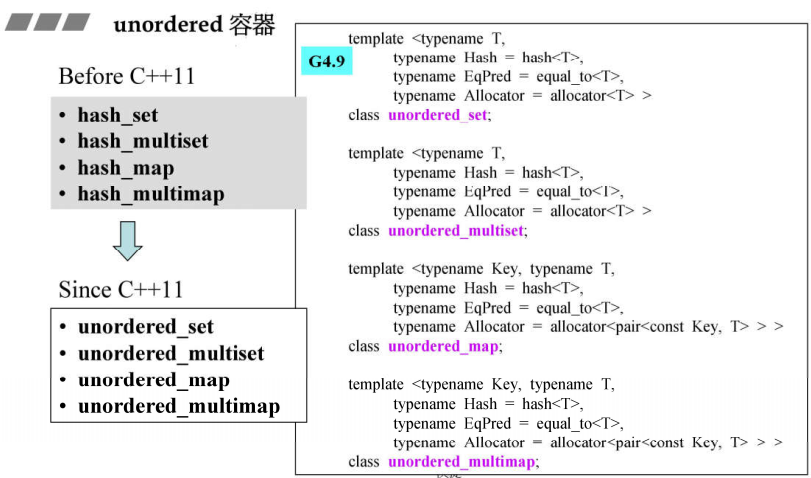
二、unordered(不定序)容器
unordered containered容器在c++11引入,由之前得hash过渡过来
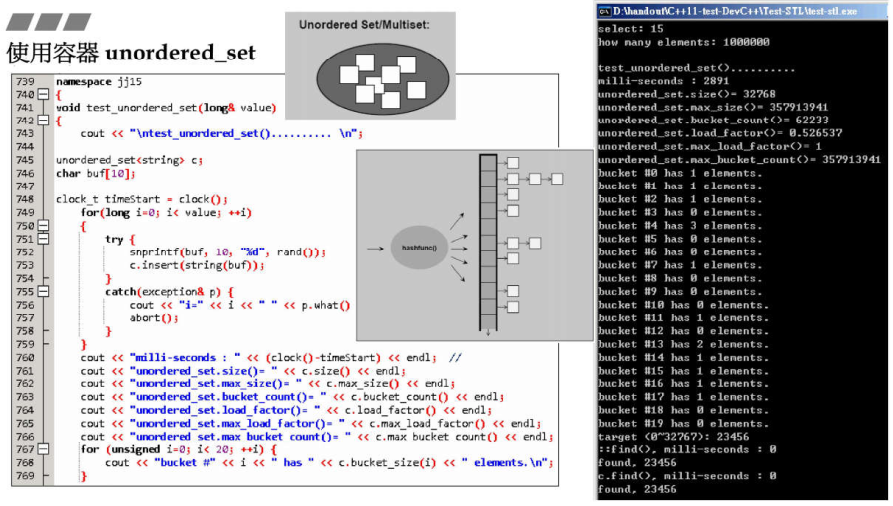
2.1 unordered_set 使用示例