准备数据
前期已经将数据生成了tfrecord格式,这里主要是研究如果从tfrecord格式文件中读取数据batch
读文件名
获取tf_record格式的文件名列表
1 tf_record_pattern = os.path.join(FLAGS.data_dir,'%s-*' %self.subset) # subset in ['train','validation'] 2 data_files = tf.gfile.Glob(tf_record_pattern)
或者
1 data_files = tf.train.match_filenames_once(tf.record_pattern)
文件名队列
用tf.train.string_input_prodecer函数来生成一个队列,放置文件名,之后文件阅读器会需要它来读取数据
注意:并不是一次性将所有文件名都放进队列,它是有容量大小限制的,也就是说队列大小为capacity

string_tensor: 文件名列表,一般就是类似 train-00000-of-00008这种
num_epochs=None: 就是说文件名列表放进队列后是循环无限次,如果设定了特定的值,那么整个队列只能循环num_epochs次,这里epoch就是指遍历所有文件名一次,也相当于说对所有数据进行迭代一个epoch
shuffle: 如果为真的话,文件名在每个epoch中都会随机重排
capacity: 队列的大小
后面三个参数都不重要
Return: A queue with the output strings. A Queue is added to the current Graph's QUEUE_RUNNER collection.
这个QueueRunner的工作线程是独立于文件阅读器的线程,因此乱序和将文件名推入到文件名队列这些过程不会阻塞文件阅读器运行。
tf.train.slice_input_producer
这里,如果直接准备的是数据的话,不需要文件名队列,可以直接产生数据队列
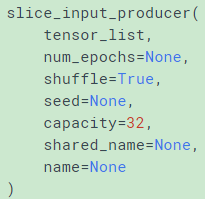
看函数名也可以看出队列中的数据时一条slice数据(打乱后shuffle=True),然后拿tf.train.batch()直接取batch就可以获得乱序batch
文件读取器
根据不同的文件格式,来选择对应的文件阅读器,然后将文件名队列提供给阅读器的read方法。阅读器的read方法会输出一个key来表征输入的文件和一个字符串标量解码成张量从而构造成样本。
1. 从csv文件中读取数据,需要使用TextLineReader和decode_csv操作
1 filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"]) 2 3 reader = tf.TextLineReader() 4 key, value = reader.read(filename_queue) 5 6 # Default values, in case of empty columns. Also specifies the type of the 7 # decoded result. 8 record_defaults = [[1], [1], [1], [1], [1]] 9 col1, col2, col3, col4, col5 = tf.decode_csv( 10 value, record_defaults=record_defaults) 11 features = tf.concat(0, [col1, col2, col3, col4]) 12 13 with tf.Session() as sess: 14 # Start populating the filename queue. 15 coord = tf.train.Coordinator() 16 threads = tf.train.start_queue_runners(coord=coord) 17 18 for i in range(1200): 19 # Retrieve a single instance: 20 example, label = sess.run([features, col5]) 21 22 coord.request_stop() 23 coord.join(threads)
每次read的执行都会从文件中读取一行内容, decode_csv 操作会解析这一行内容并将其转为张量列表。如果输入的参数有缺失,record_default参数可以根据张量的类型来设置默认值。
在调用run或者eval去执行read之前, 你必须调用tf.train.start_queue_runners来将文件名填充到队列。否则read操作会被阻塞到文件名队列中有值为止。
2. 从二进制文件中读取固定长度记录,可以使用tf.FixedLengthRecordReader的tf.decode_raw操作。decode_raw操作可以讲一个字符串转换为一个uint8的张量。
举例来说,the CIFAR-10 dataset的文件格式定义是:每条记录的长度都是固定的,一个字节的标签,后面是3072字节的图像数据。uint8的张量的标准操作就可以从中获取图像片并且根据需要进行重组。 例子代码可以在tensorflow/models/image/cifar10/cifar10_input.py找到
3.标准tensorflow格式,将数据转换成TFRecords文件
从TFRecords文件中读取数据, 可以使用tf.TFRecordReader的tf.parse_single_example解析器。这个parse_single_example操作可以将Example协议内存块(protocol buffer)解析为张量
批处理
在数据输入管线的末端, 我们需要有另一个队列来执行输入样本的训练,评价和推理。因此我们使用tf.train.shuffle_batch 函数来对队列中的样本进行乱序处理
1 def read_my_file_format(filename_queue): 2 reader = tf.SomeReader() 3 key, record_string = reader.read(filename_queue) 4 example, label = tf.some_decoder(record_string) 5 processed_example = some_processing(example) 6 return processed_example, label 7 8 def input_pipeline(filenames, batch_size, num_epochs=None): 9 filename_queue = tf.train.string_input_producer( 10 filenames, num_epochs=num_epochs, shuffle=True) 11 example, label = read_my_file_format(filename_queue) #这里是单个reader在读文件,batch是当个reader读单个文件shuffle成batch 12 # min_after_dequeue defines how big a buffer we will randomly sample 13 # from -- bigger means better shuffling but slower start up and more 14 # memory used. 15 # capacity must be larger than min_after_dequeue and the amount larger 16 # determines the maximum we will prefetch. Recommendation: 17 # min_after_dequeue + (num_threads + a small safety margin) * batch_size 18 min_after_dequeue = 10000 19 capacity = min_after_dequeue + 3 * batch_size 20 example_batch, label_batch = tf.train.shuffle_batch( 21 [example, label], batch_size=batch_size, capacity=capacity, 22 min_after_dequeue=min_after_dequeue) 23 return example_batch, label_batch
tf.train.shuffle_batch()
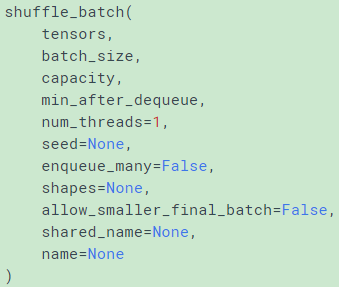
从上面函数定义看出shuffle_batch的输入是tensors,看代码发现不是直接从queue中获取batch,而是以一种自定义的方式读取tensor后再获取batch
如果你需要对不同文件中的样子有更强的乱序和并行处理,可以使用tf.train.shuffle_batch_join 函数. 示例:
1 def read_my_file_format(filename_queue): 2 # Same as above 3 4 def input_pipeline(filenames, batch_size, read_threads, num_epochs=None): 5 filename_queue = tf.train.string_input_producer( 6 filenames, num_epochs=num_epochs, shuffle=True)
7 example_list = [read_my_file_format(filename_queue) 8 for _ in range(read_threads)] #这里是多个reader,batch_join将是多个reader读多个文件然后构成batch 9 min_after_dequeue = 10000 10 capacity = min_after_dequeue + 3 * batch_size 11 example_batch, label_batch = tf.train.shuffle_batch_join( 12 example_list, batch_size=batch_size, capacity=capacity, 13 min_after_dequeue=min_after_dequeue) 14 return example_batch, label_batch
在这个例子中, 虽然只使用了一个文件名队列, 但是TensorFlow依然能保证多个文件阅读器从同一次迭代(epoch)的不同文件中读取数据,直到这次迭代的所有文件都被开始读取为止。(通常来说一个线程来对文件名队列进行填充的效率是足够的)
另一种替代方案是:使用tf.train.shuffle_batch 函数,设置num_threads的值大于1。 这种方案可以保证同一时刻只在一个文件中进行读取操作(但是读取速度依然优于单线程),而不是之前的同时读取多个文件。这种方案的优点是:
- 避免了两个不同的线程从同一个文件中读取同一个样本。
- 避免了过多的磁盘搜索操作。
创建线程并使用QueueRunner对象来预取
使用上面的tf.train.string_input_producer和tf.train.shuffle_batch_join等函数添加QueueRunner到你的数据流图中。在你运行任何训练步骤之前,需要调用tf.train.start_queue_runners函数,否则数据流图将一直挂起。tf.train.start_queue_runners这个函数将会启动输入管道的线程,填充样本到队列中,以便出队操作可以从队列中拿到样本。这种情况下最好配合使用一个tf.train.Coordinator,这样可以再发生错误的情况下正确下正确地关闭这些线程。如果对训练迭代数做了限制,那么需要使用一个训练迭代数计数器,并且需要被初始化。
1 # Create the graph, etc. 2 init_op = tf.initialize_all_variables() 3 4 # Create a session for running operations in the Graph. 5 sess = tf.Session() 6 7 # Initialize the variables (like the epoch counter). 8 sess.run(init_op) #没有初始化会报错 9 10 # Start input enqueue threads. 11 coord = tf.train.Coordinator() 12 threads = tf.train.start_queue_runners(sess=sess, coord=coord) 13 14 try: 15 while not coord.should_stop(): 16 # Run training steps or whatever 17 sess.run(train_op) 18 19 except tf.errors.OutOfRangeError: 20 print 'Done training -- epoch limit reached' 21 finally: 22 # When done, ask the threads to stop. 23 coord.request_stop() 24 25 # Wait for threads to finish. 26 coord.join(threads) 27 sess.close()
具体的数据输入流程如下图所示:
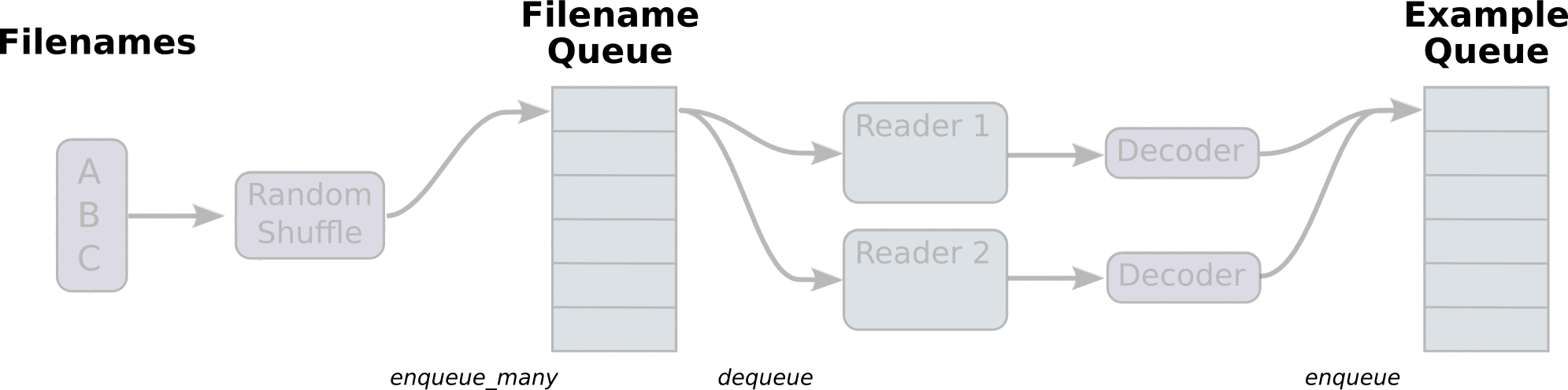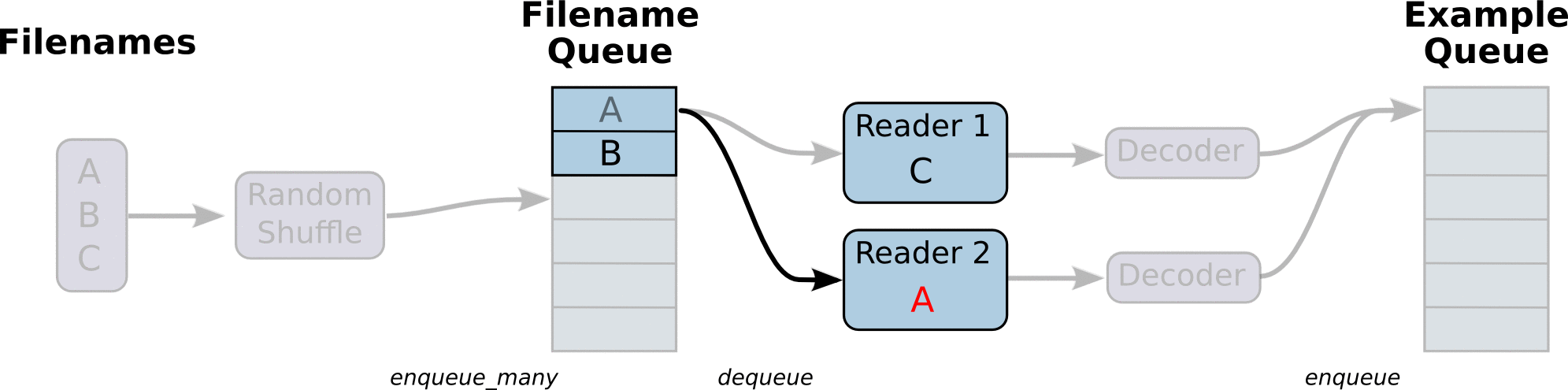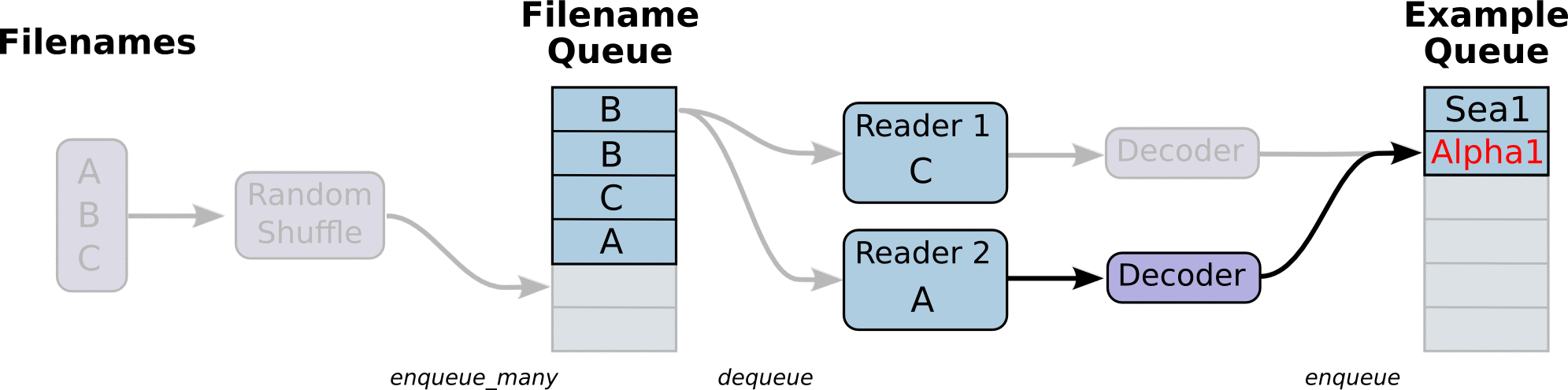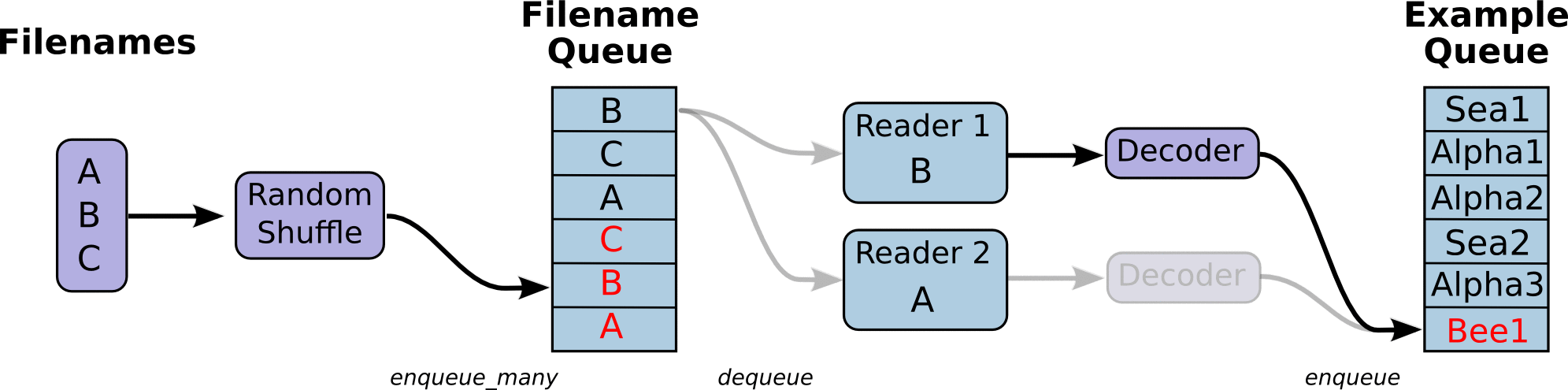
先单个线程构建文件名队列,然后用reader解析每个文件名中的数据,一个reader负责一个文件名中的数据,reader解析完数据样本后,tf.train.shuffle_batch构建样本队列,对于单个reader就是按顺序对每个文件中数据shuffle输入队列。多个reader就是同时对不同的文件中样本数据shuffle输入队列。
因为开始就运行了这些入队操作的线程,所以训练循环会使得样本队列中中的样本不断地出队。
在tf.train中要创建这些队列和执行入队操作,就要添加tf.train.QueueRunner到一个使用tf.train.add_queue_runner函数的数据流图中。每个QueueRunner负责一个阶段,处理那些需要在线程中运行的入队操作的列表。一旦数据流图构造成功,tf.train.start_queue_runners函数就会要求数据流图中每个QueueRunner去开始它的线程运行入队操作。
如果一切顺利的话,你现在可以执行你的训练步骤,同时队列也会被后台线程来填充。如果您设置了最大训练迭代数,在某些时候,样本出队的操作可能会得到一个tf.OutOfRangeError的错误。这其实是TensorFlow的“文件结束”(EOF) ———— 这就意味着已经达到了最大训练迭代数,已经没有更多可用的样本了。
最后一个因素是Coordinator。这是负责在收到任何关闭信号的时候,让所有的线程都知道。最常用的是在发生异常时这种情况就会呈现出来,比如说其中一个线程在运行某些操作时出现错误(或一个普通的Python异常)。
Queue
Queue是TF队列和缓存机制的实现QueueRunner是TF中对操作Queue的线程的封装Coordinator是TF中用来协调线程运行的工具
1 import tensorflow as tf 2 tf.InteractiveSession() 3 4 q = tf.FIFOQueue(2, "float") 5 init = q.enqueue_many(([0,0],)) 6 7 x = q.dequeue() 8 y = x+1 9 q_inc = q.enqueue([y]) 10 11 init.run() 12 q_inc.run() 13 q_inc.run() 14 q_inc.run() 15 x.eval() # 返回1 16 x.eval() # 返回2 17 x.eval() # 卡住
QueueRunner
Tensorflow的计算主要在使用CPU/GPU和内存,而数据读取涉及磁盘操作,速度远低于前者操作。因此通常会使用多个线程读取数据,然后使用一个线程消费数据。QueueRunner就是来管理这些读写队列的线程的。
QueueRunner需要与Queue一起使用(这名字已经注定了它和Queue脱不开干系),但并不一定必须使用Coordinator。
Coordinator
Coordinator是个用来保存线程组运行状态的协调器对象,它和TensorFlow的Queue没有必然关系,是可以单独和Python线程使用的。
1 import tensorflow as tf 2 import threading, time 3 4 # 子线程函数 5 def loop(coord, id): 6 t = 0 7 while not coord.should_stop(): 8 print(id) 9 time.sleep(1) 10 t += 1 11 # 只有1号线程调用request_stop方法 12 if (t >= 2 and id == 1): 13 coord.request_stop() 14 15 # 主线程 16 coord = tf.train.Coordinator() 17 # 使用Python API创建10个线程 18 threads = [threading.Thread(target=loop, args=(coord, i)) for i in range(10)] 19 20 # 启动所有线程,并等待线程结束 21 for t in threads: t.start() 22 coord.join(threads)
将这个程序运行起来,会发现所有的子线程执行完两个周期后都会停止,主线程会等待所有子线程都停止后结束,从而使整个程序结束。由此可见,只要有任何一个线程调用了Coordinator的request_stop方法,所有的线程都可以通过should_stop方法感知并停止当前线程。
将QueueRunner和Coordinator一起使用,实际上就是封装了这个判断操作,从而使任何一个现成出现异常时,能够正常结束整个程序,同时主线程也可以直接调用request_stop方法来停止所有子线程的执行。
Queue的使用都是配合了QueueRunner和Coordinator一起使用的
- 第一种,显式的创建QueueRunner,然后调用它的create_threads方法启动线程。
- 第二种,使用全局的start_queue_runners方法启动线程
在这个例子中,tf.train.string_input_produecer会将一个隐含的QueueRunner添加到全局图中(类似的操作还有tf.train.shuffle_batch等)。
由于没有显式地返回QueueRunner来用create_threads启动线程,这里使用了tf.train.start_queue_runners方法直接启动tf.GraphKeys.QUEUE_RUNNERS集合中的所有队列线程。这两种方式在效果上是等效的。
参考链接
http://honggang.io/2016/08/19/tensorflow-data-reading/ 解释的相当清楚,还有具体例子说明 必看{❤❤}
https://saicoco.github.io/tf3/ 解释的相当棒
http://www.jianshu.com/p/d063804fb272 理解tensorflow中的Queue