结对作业 (二)
结对情况
- 自己
- 228
- 友林
- 小伙伴
- 226
- 锃
博客链接
项目链接
设计说明
-
接口设计(API)
class match { void Readjs();//读取输入文件 void heatmatch();//第一种匹配算法 void make_distribution_bytags();//第二种匹配算法 void Print();//输出 } -
内部实现设计(类图)
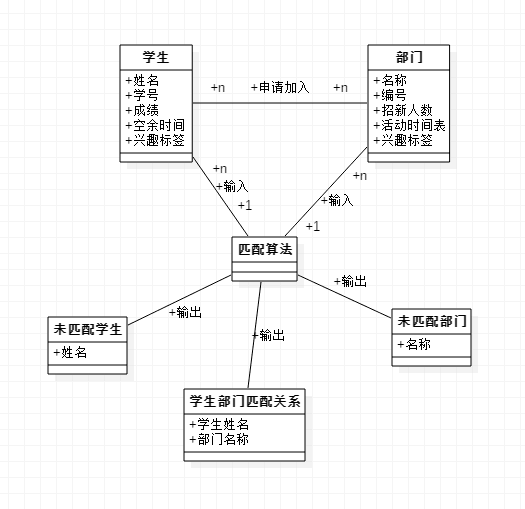
-
匹配算法思路
我们在设计这道题时设想了两种处理方式,一种是通过生成的兴趣标签,通过学生与部门之间互相匹配的兴趣标签的数量,来匹配学生与部门。首先先根据学生的成绩进行排序,成绩高的学生优先进行选择。通过时间匹配先把不满足时间要求的部门剔除,再选一个兴趣标签匹配最多的部门加入,然后取下一个学生进行同样的操作。这样进行两轮,每轮每个学生只能加入一个部门。
另一种是为了保证学生能够尽可能的加入部门,计算每个学生的志愿中最“空闲”的部门,然后如果学生自身有空余时间参与部门活动,则该学生进入该部门。在学生中,通过每个学生志愿中“最闲”部门的“空闲”程度比较,得出最“空闲”的学生,是他先选择部门,这样就可以尽可能保证学生能够进入志愿中的某个部门了。
测试数据生成
输入的数据,另外写生成程序随机实现。
部门与学生姓名:生成数据时,为了保持美观,在网上复制了100个和5000个学生名字,通过随机数的方法,从这些姓名中挑出足够的数量去生成数据(对不起是我偷懒了...)
部门与学生时间:一开始生成的时候我将所有时间都设置成了随机形成,结果发现这样的后果是时间太零散,且部门与学生之间可能匹配到的几率非常低,所以修改之后,设置了几个时间段,通过随机选取时间段的方法,产生学生空闲时间以及部门活动时间(为了靠近现实,我们将学生空余时间调的比较多,便于匹配)
部门与学生标签生成: 我们通过随机生成固定种数的标签后,对部门以及学生随机分配,保证学生或部门不会出现一个人或者一个部门有重复标签,同时保证部门标签数量上限高于学生标签数量。
遇到的困难及解决办法
1.在对学生以成绩进行排序的时候比较头疼吧,一开始想用简单冒泡之类的,后面发现实在不好用,于是使用了大堆实现。
2.尝试使用了Hash来解决部门到名字的映射吧,但是使用的不太好,后面还耍了一些小手段,对于个别几个冲突我们直接通过具体名字去解决了,很尴尬。。。
3.时间匹配一开始用字符串进行处理,十分麻烦。改用数组表示学生的每个时间段是否有空,操作更为简单了。
4.jsoncpp库不懂如何使用。去网上查找解决办法。
对队友的评价
优点和值得学习的地方
1.值得信赖
2.做事认真
不好或需要改进的地方
1.思想顽固,喜欢钻牛角尖
运行结果及展示
- 测试200位同学,20个部门的情况
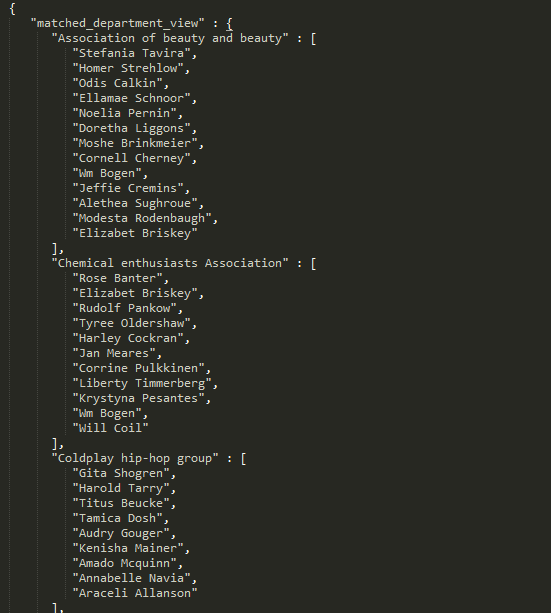
- 测试500位同学,30个部门的情况
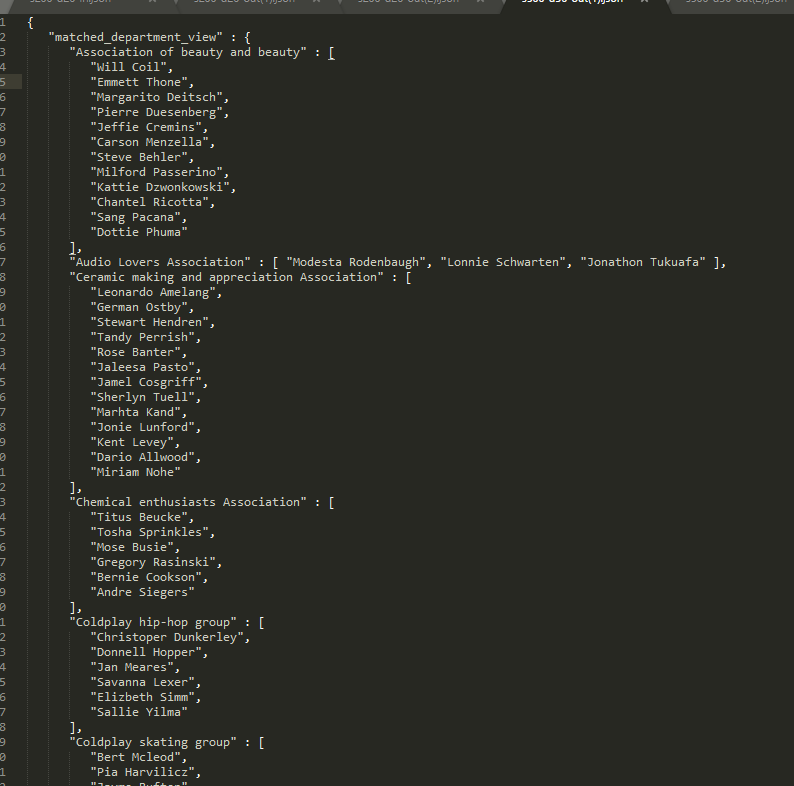
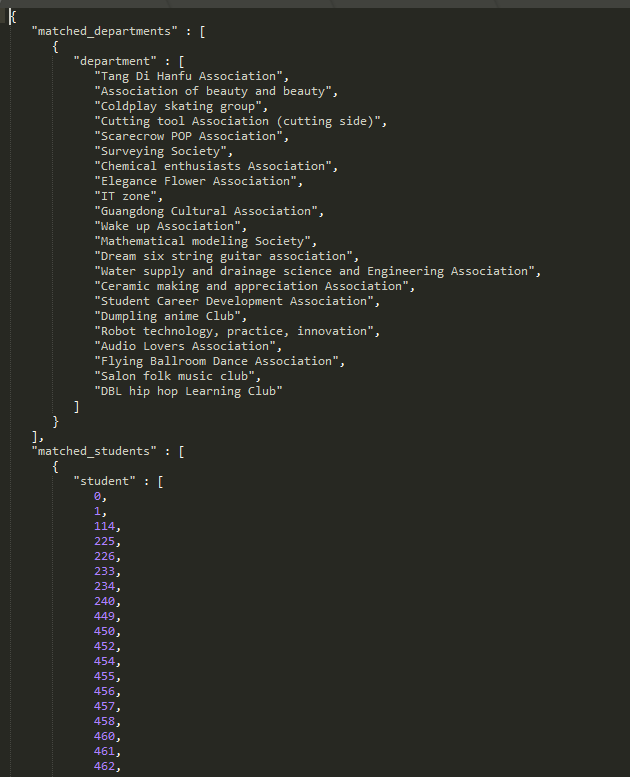
- 测试1000位同学,50个部门的情况
- 测试5000位同学,100个部门的情况

关键代码
int stu=DeleteMin(s_MaxHeap,s_score);//取出堆中成绩最好的学生
Json::Value stu_students = jsroot["students"][stu];
int max_s_d=find_Max_tags(s_d_tags[stu],5);//得到该学生最感兴趣的部门在学生意愿中的位置
int max_d = d_NameHash(stu_students["departments_wish"][max_s_d].asString());//获得该部门的在全部部门中的位置
max_d = d_hash_map[max_d];
int d_member_limit = jsroot["departments"][max_d]["member_limit"].asInt();
while (matched_department[max_d] >= d_member_limit && d_member_limit&&s_d_tags[stu][max_s_d])
{//当部门人数满是查找下一个最感兴趣的部门
s_d_tags[stu][max_s_d] = 0;
max_s_d = find_Max_tags(s_d_tags[stu], 5);
max_d = d_hash_map[d_NameHash(stu_students["departments_wish"][max_d].asString())];
d_member_limit = jsroot["departments"][max_d]["member_limit"].asInt();
}
if (s_d_tags[stu][max_s_d] == 0 || d_member_limit==0) //没有找到匹配的部门,该学生加入为匹配的学生中
matched_student[stu] = 0;
else
{//找到匹配的部门,并更改部门已招人数,以及修改学生时间表
matched_department[max_d]++;
s_d_tags[stu][max_s_d] = 0;//防止下一轮循环中被取中
sTimeOperation(s_time0[stu], d_event_schedules[max_d], jsroot["departments"][max_d]["event_schedules"].size());
matched_student[stu] = 1;
//输出匹配的部门和学生
string d_name= jsroot["departments"][max_d]["department_name"].asString();
string s_name = stu_students["student_name"].asString();
jsout["matched_department_view"][d_name].append(s_name);
jsout["matched_student_view"][s_name].append(d_name);
}
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 20 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 30 | 50 |
| · Coding | · 具体编码 | 100 | 120 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 30 | 40 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 325 | 465 |
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 0 | 226 | 226 | 10 | 10 | 学会了vs基本操作以及代码的测试方法 |
| 1 | 100 | 326 | 6 | 16 | 了解了原型设计的相关知识与设计方法 |
| 5 | 423 | 749 | 12 | 28 | 了解了json文件的解析方式 |