我相信很多人都知道《深入理解计算机操作系统》这本书,并且很多人都会对它研读。实际本人刚开始看的时候,只是加深了对操作系统的理解,别的到是没有感觉的到,
但是在看到公司的软件框架里面对于内存堆的管理,才发现和书上讲的异曲同工。于是乎,自己对利用隐式的空闲链表实现分配器做了总结,并且和自己想到的架构做了对比分析。
我们知道一个实际的分配器,不仅要考虑好吞吐率和内存利用率之间的平衡,还要考虑:
①空闲块组织:我们如何记录空闲块(一般刚开始会把一整段堆当做空闲块,然后再分割)
②放置:我们如何选择一个合适的空闲块来放置一个新分配的块?
③分割:在一个空闲块里面放置一个块后,剩余的空闲部分怎么处理?
④合并:我们如何处理刚刚释放的块?假如有两个块都是空闲的,需要合并吗 ?
管理:于是书中定义一个数据结构来区分块边界,用来记录空闲块,这个数据结构是:
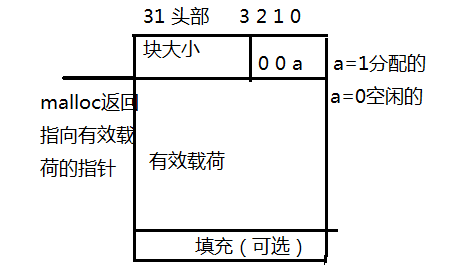
块大小包括头、有效负荷和填充部分,这样就可以记录出空闲和以分配的块,对应的隐式空闲链表如下图所示:

放置和分割:假如我们想要放置已经分配块时,分配器会搜索链表,寻求一个足够大的空闲块来放置,有首次放配的策略、下一次分配的策略和最佳适配的策略,为了方便起见,我们将使用首次分配,从堆头开始搜索空闲链表,选择第一个合适的空闲块,这样的优点是趋向于将大的空闲块放在最后,缺点是开始的地方有小空闲块的“碎片”。当你找到一个匹配的空闲块时,你要做决定是否需要分割,这样的话第一部分变成分配块,而剩下的部分还为空闲块,如下图所示:

合并:合并的问题最需要考虑的,当分配器释放一个分配块时,假如其他的空闲块于之相连,这个时候需要合并,我们假设是立即合并(实际快速的分配器不会是立即合并,会选择推迟合并)。如果是下一个块时空闲块,可以让释放掉的空闲块的头部,加上块大小,指向下一个块,然后读出下一个块的大小,就将它的大小简单的加到当前块头部的大小上。但是如果是前面的块时空闲块的话,就需要搜索整个链表,记录前面的块再进行合并,这样free需要的时间与堆的大小成线性关系,对于吞吐率是有很大的影响,这个时候Knuth记录提出了边界标记(boundary tag),在脚部添加一个头部的副本,这个脚部总是在距当前块开始位置一个字的距离。实际这样是牺牲了内存来实现吞吐率的。
当然了,为了我们结构的可读性更好,我们可以定义一个头部结构体,不用放脚部标记了
typedef struct
{
size_t sec_size;//块的大小,用于比较和申请内存的块,找到能放的下的空闲块(在已经分配的块上,这个值一般等于alloc_size)
size alloc_size;//有效负载的大小,由于知道结构体的大小,相当于上文中知道了块大小
size_t prev_sec_addr;//上一个块的起始地址,是从头部开始,用于和前合并
}