什么是字典树?
字典树(又叫单词查找树、TrieTree),是一种树形结构,典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串,如01字典树)。主要思想是利用字符串的公共前缀来节约存储空间。很好地利用了串的公共前缀,节约了存储空间。字典树主要包含两种操作,插入和查找。
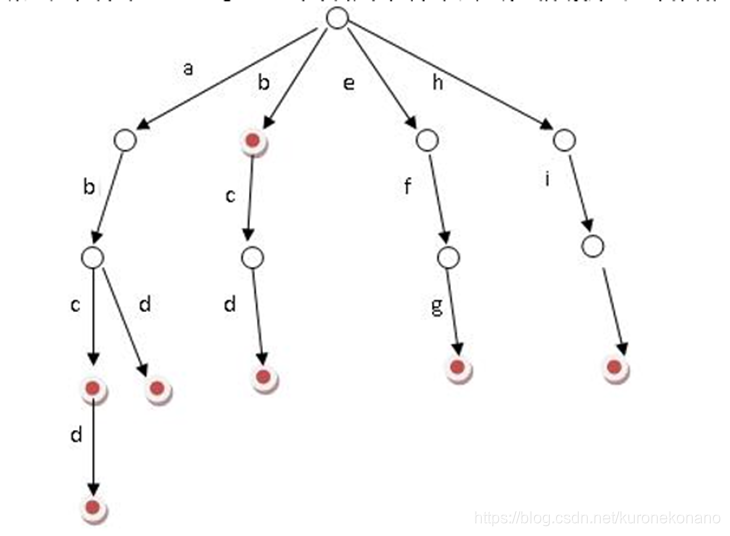
字典树的优点
- 节约空间
例如在现实生活中,我们需要存储很多URL(Uniform Resoure Locator:统一资源定位器)是WWW页的地址。
大多数以“http://www ”开头,若以字典树存储,则50亿个“http://www ”只需要10个存储单位即可,而非50亿*10个。
- 快速检索
字典树能很好地利用串的公共前缀,节约了存储空间,同时用它来检索同样有着比较高的效率。
我们需要将一个单词列表建出一棵单词查找树,满足:
(1)根结点不包含字母,除根结点外的每个都仅含一个大写英文字母;
(2)从根结点到某一节点,路径上经过的字母依次连起来所构成的单词,称为该结点对应的单词。单词列表中的每个词,都是该单词查找树某个结点所对应的单词;
(3)在满足上述条件下,该单词查找树的结点数最少,统计出该单词查找树的结点数目。

字典树的结构
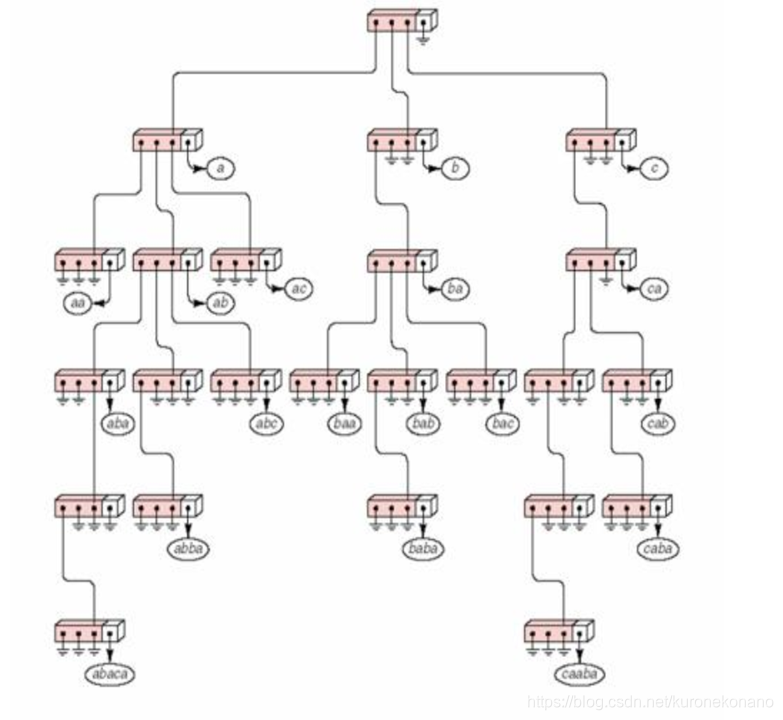
字典树可以解决以下问题:
在题目给出的输入字典中查询单词是否存在,以及以某单词为前缀查询字典中有多少符合条件的单词
例题:
题意:给出一些单词找出其中某些可以由另外两个单词拼接而成的单词
样例输入 样例输出
a ahat
ahat hatword
hat
hatword
hziee
word
分析:如果按最朴素的方法实现,即对于输入的每个单词依次进行遍历,如第二个单词‘ahat’,要查询其是否由输入的其他单词组合而成,就要将ahat拆开,变为a+hat,ah+at,aha+t,对输入的n个单词再查找一轮是否有一样匹配的字符。也就是n(个单词)*len-1(每个单词长度)*n(个单词) 的查询次数两两单词进行比对时用到strcmp函数又要花费len的查询次数。
若在查询过程中使用字典树进行查找。依然对每个单词进行遍历。然后将n个单词分别拆开,两段分开的单词进行字典树查询。
如果两段单词都在字典树中查询成功说明被查询单词即其中一个ans。
对字典树进行查询时,无须遍历n个单词,只用对被查询单词在树上走出len的查询次数。
字典树还有很多除了字符串之外的应用,如对数字的二进制01串构造字典树可以快速按位查询数字是否存在。当结合字符串匹配算法KMP时,利用KMP的利用失配信息思想快速继续匹配,可以实现AC自动机算法。只需给每个节点增加fail指针指向失配时快速指向的节点。
当对构造好的字典树进行BFS预处理并增加直达叶子节点的指针时,可以解决输入最小操作数的问题。
总之以字典树为基础可以改造出各种有用而高效的处理方法。
数组模拟字典树:
#include <stdio.h>
#include <string.h>
const int maxn=10000;//提前估计好可能会开的节点的个数
int tot; //节点编号,模拟申请新节点,静态申请
int trie[10000][26]; //假设每个节点的分支有26个
bool isw[10000]; //判断该节点是不是单词结尾
void insert(char *s,int rt)//投入的参数是一个字符串和节点数,建立字典树
{
for(int i=0; s[i]; i++)
{
int x=s[i]-'a';//假设单词都是小写字母组成
if(trie[rt][x]==0) //没有,申请新节点
{
trie[rt][x]=++tot;//每个字符的编号
}
rt=trie[rt][x];
}
isw[rt]=true;//整个字符串读完后,在isw数组中记录第rt层为单词结尾
}
bool find(char *s,int rt)
{
for(int i=0; s[i]; i++)
{
int x=s[i]-'a';//假设单词都是小写字母组成
if(trie[rt][x]==0)
{
return false;
}
rt=trie[rt][x];
}
return isw[rt];
}
char s[22];//单词读入
int main()
{
tot=0;//一开始没有节点
int rt=++tot;//申请一个根节点
memset(trie[rt],0,sizeof(trie[rt]));//初始化根节点
memset(isw,false,sizeof(isw));
while(scanf("%s",s),s[0]!='#') //新建字典,以一个'#'结束
{
insert(s,rt);
}
while(scanf("%s",s),s[0]!='#') //查单词,以一个'#'结束
{
if(find(s,rt))//从字典中查找单词
printf("%s 在字典中
",s);
else
printf("%s 不在字典中
",s);
}
return 0;
}
指针型字典树:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
struct trie//trie型结构体,建立树
{
int cnt;//用作标记查找
trie *next[26];//连接树与节点的指针
bool flag;///单词结尾节点标记
};
trie *root=new trie;//建立根节点
void insert(char ch[])
{
trie *p=root,*newnode;
for(int i=0; ch[i]!='�'; i++)
{
if(p->next[ch[i]-'a']==0)//这里以所有的字符全部为小写字母为例
{
newnode=new trie;///创建新节点
newnode.flag=false;///初始化新节点结尾标记
for(int j=0; j!=26; j++)
{
newnode->next[j]=NULL;///初始化所有孩子
}
newnode->cnt=1;///新节点次数初始化
p->next[ch[i]-'a']=newnode;
p=newnode;
}
else
{
p=p->next[ch[i]-'a'];
p->cnt++;///对走过的节点次数进行计数
}
}
p->flag=true;///标记结尾
}
int find(char ch[])///查询
{
trie *p=root;
for(int i=0; ch[i]!='�'; i++)
{
if(p->next[ch[i]-'a']!=NULL)
p=p->next[ch[i]-'a'];
else
return 0;
}
return p->cnt;
}
int deal(trie* T)//递归将字典树清空
{
int i;
if(T==NULL)
return 0;
for(i=0;i<10;i++)
{
if(T->next[i]!=NULL)
deal(T->next[i]);
}
free(T);
return 0;
}
int main()
{
char ch[20];
for(int i=0; i!=26; i++)
{
root->next[i]=NULL;
}
root->cnt=0;
while(gets(ch))
{
if(!strcmp(ch,""))
break;
insert(ch);
}
while(scanf("%s",ch)!=EOF)
{
printf("%d
",find(ch));
}
deal(root);
return 0;
}