作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
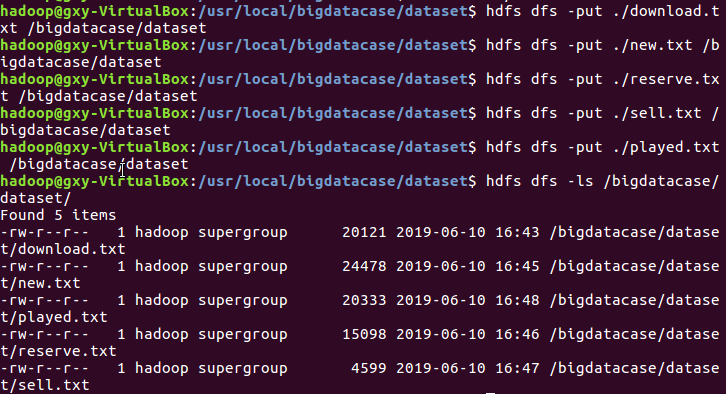
1.将爬虫大作业产生的csv文件上传到HDFS
先将要上传的文件放到指定文件夹
这里要上传download、new、played、reserve、sell5个表

命令 hdfs dfs -put ./*.csv 上传csv文件到hdfs
命令 hdfs dfs -put ./*.txt 为了后续方便这里上传的是txt文件
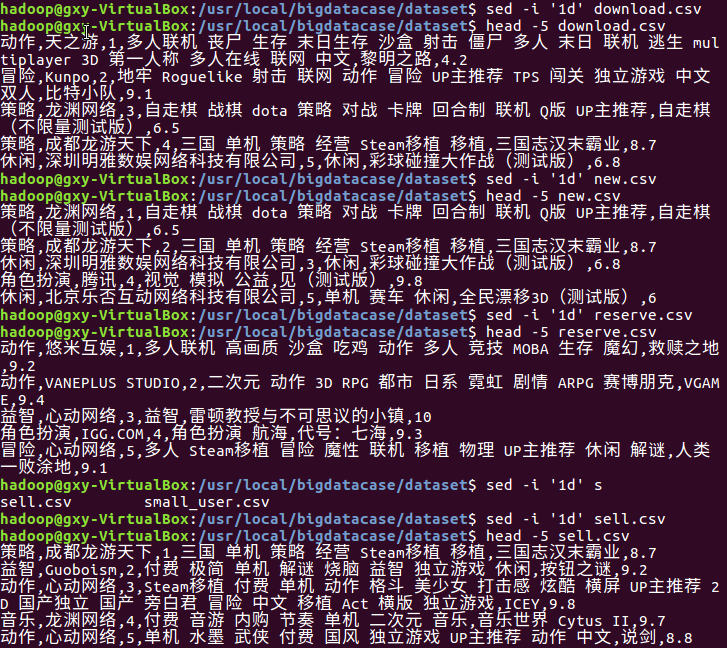
2.对CSV文件进行预处理生成无标题文本文件
命令 sed -i 'id' *.csv sed用于一些简单的文本替换 -i表示inplace edit,就地修改文件 1d表示删除第一行
命令 head -5 *.csv 显示csv前5行的内容
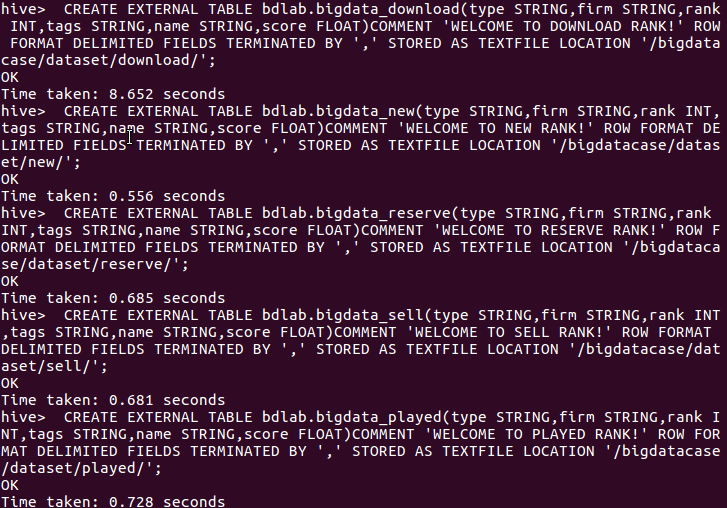
3.把hdfs中的文本文件最终导入到数据仓库Hive中
命令 把hdfs中的 /bigdatacase/dataset 目录的数据加载到hive数据仓库
CREATE EXTERNAL TABLE 表名(属性) COMMENT '欢迎语' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION '/bigdatacase/dataset';
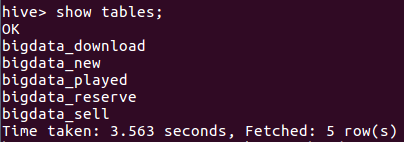
4.在Hive中查看并分析数据
(1)查看数据库的表
根据爬取的数据,在数据库中创建了下载榜、新品榜、预约榜、热卖榜和热玩榜5个表
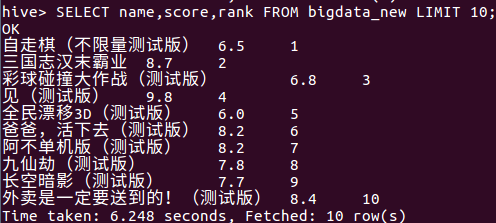
(2)查询新品榜排行前十的游戏,分别列出游戏名,评分,排行
从下图可以看出:
- 排行较前的新游戏评分基本居高
- 新品榜前5的游戏中有三个为6分游戏,可以得知游戏性一般的新游戏在大力宣传力度下可以短时间吸引大量玩家
- 新品榜大多为内测游戏,这样可以让游戏从制作中到公测期间不断地吸引玩家目光
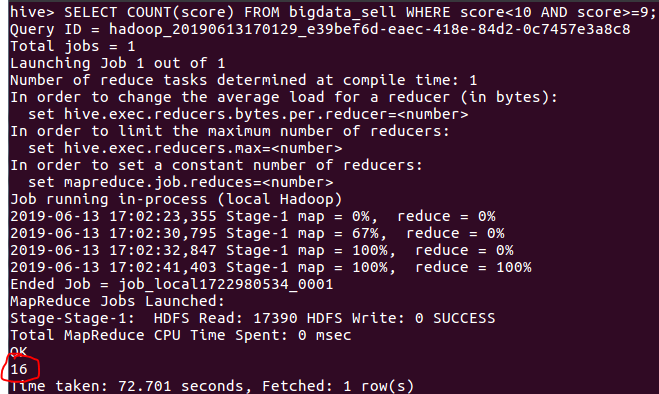
(3)查询热卖榜评分9分以上的游戏数量
从下图可以看出:
- 热卖榜共有35个游戏,获得9分高分的游戏有6个,高分率为17%,得知付费游戏质量远比免费游戏高
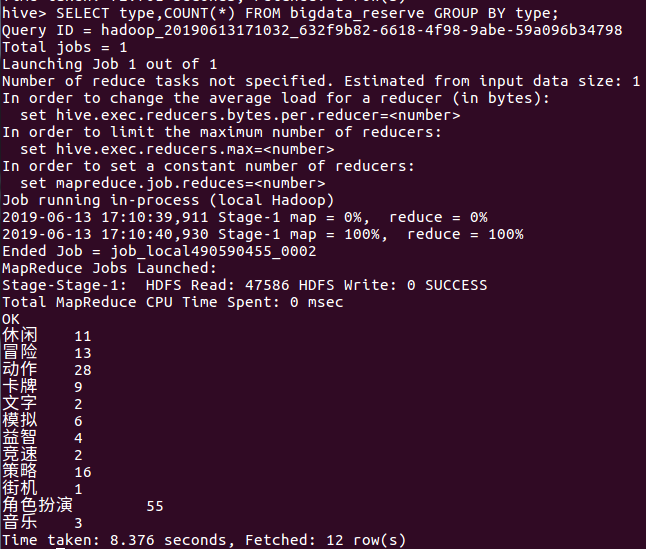
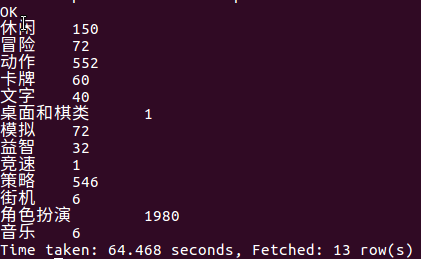
(4)查看预约榜的游戏分类数量,分别列出分类,数量
下图可以看出:
- 角色扮演的游戏类型占据榜单的1/3,是现在游戏市场的开发趋势
- 动作游戏和策略游戏虽然没有像角色扮演游戏那样大受期待,但不容易令玩家审美疲劳,也有很好的开发前景
- 像街机、文字、音乐、益智等游戏类型比较不受期待,但如果开发好的话会在该游戏类型当中独树一帜
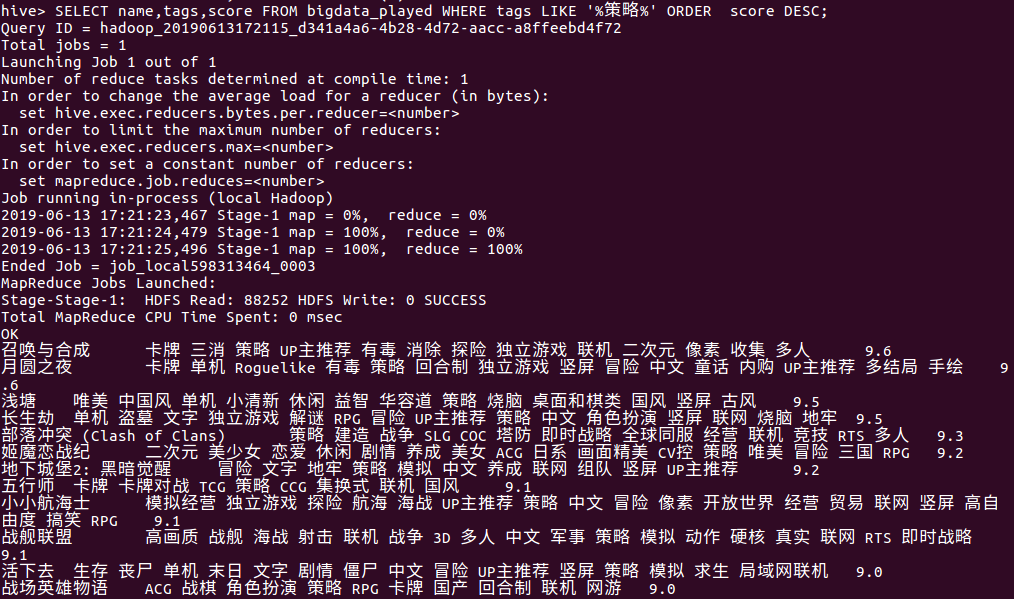
(5)按评分由高到低排序查看热玩榜含有“策略”标签的游戏,分别列出游戏名,标签,评分
下面可以看出:
- 带有“策略”标签的游戏占热玩榜1/3,看出策略游戏可玩性较高
- 带有“策略”标签的前十几个游戏皆有9分以上,证明策略游戏受玩家欢迎与其游戏的可玩性很大

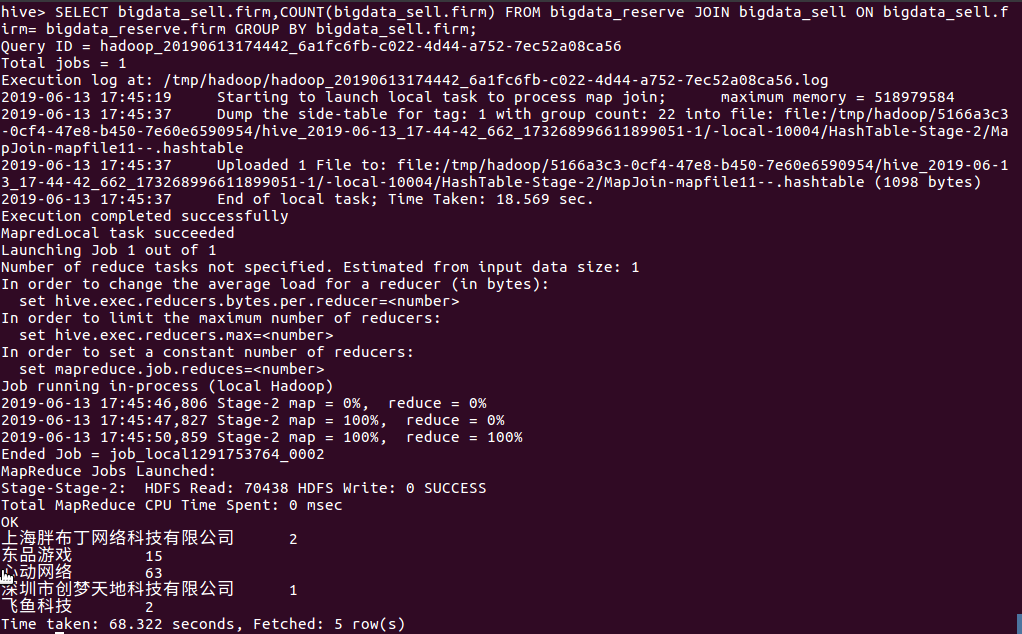
(6)查看下载榜所有厂商的数量,分别列出厂商,数量
下面可以看出:
- 网易游戏厂商的游戏占据下载榜的位置最多,有16个之多,而其他大多数厂商基本只有1个
- 像网易游戏,腾讯这样的大厂商的游戏会吸引更多玩家下载

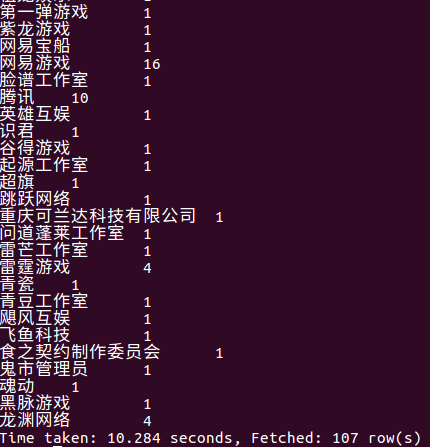
(7)查询同时存在于下载榜和热玩榜的游戏分类数量,分别列出分类,数量
下面可以看出:
- 比较吸引玩家的题材及可玩性高的游戏类型是角色扮演
- 竞速类、音乐类游戏即小众也很难有出众的游戏玩法

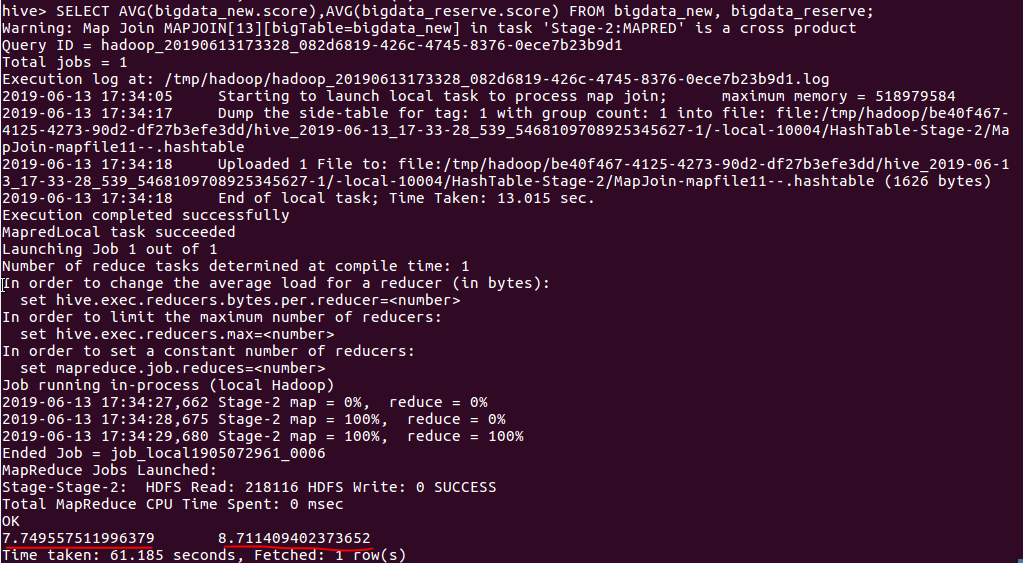
(8)查询新品榜和预约榜的平均分,分别列出新品榜平均分,预约榜平均分
下面可以看出:
- 预约榜的平均分比新品榜的平均分要高1分,可见玩家在游戏面世前和面世后会有一点落差
- 较少游戏能做到面世后符合玩家的期望
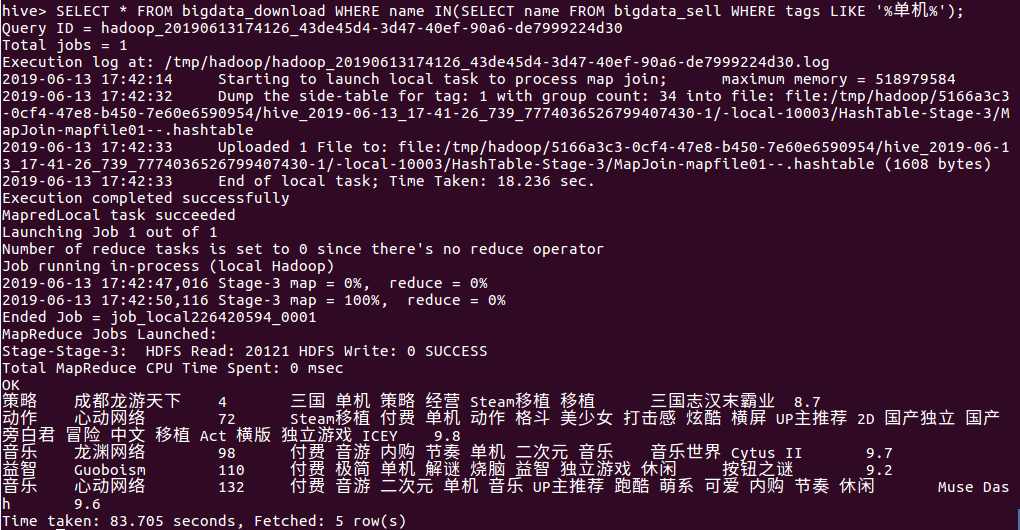
(9)查询同时存在于下载榜和热卖榜含有“单机”标签的游戏信息
下面可以看出:
- 热门的付费单机游戏比较少只有5个,玩家更倾向于免费的单机游戏
- 热门的付费单机游戏均取得较高的评分,如果不是非常好玩不会有大量玩家选择付费
- 心动网络厂商在其中占据两个位置,说明该厂商有较好能力做出热门的付费游戏
(10)查询同时存在预约榜和热卖榜的厂商,分别列出厂商,数量
下面可以看出:
- 能够做到宣传好、题材吸引且热卖的厂商不多,只有5个
- 其中心动网络厂商的游戏共有65,玩家想玩好玩又别出新意的游戏可以考虑该厂商
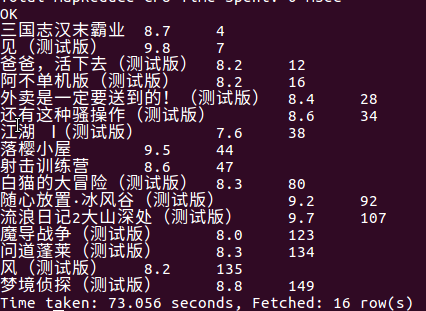
(11)查询在新品榜榜评分为8分以上,在下载榜中的游戏信息,分别列出游戏名,评分,排行
下面可以看出:
- 新品游戏评分8分以上的同时出现在下载榜的游戏有16个,可以看出高分新游戏在游戏流量市场里占比10%。
- 大多数是内测游戏,说明内测游戏的开放有利于提高游戏的质量与获取玩家的游戏取向
- 16个游戏之中的排名在排行榜分布均匀

5.总结
这次的数据分析主要运用到了hdfs上传数据文件和hive分析文本。而在数据文本处理的过程中也遇到一些困惑,下面是我总结的心得:
(1)由于在榜单上有一些游戏评分过少,导致该条排行无效,所以会有一个榜单的总量会少几条。
(2)因为我的数据文本都是有效数据,不存在空值等无效信息,所以没有进行预处理。
(3)对于预处理的方法并不是很熟悉,只知道sed、awk的含义,但实际应用还不熟练。
(4)关于中文乱码问题只要提前把文件转为utf8编码即可。
总体来说操作过程都比较顺利,也从sql语句的查询当中分析到了很多数据间的关联以及其代表的含义。