元数据
数据字典
数据字典描述的是数据的结构信息
数据血缘
数据血缘是指一个表是直接通过哪些表加工而来
数据特征
而数据特征主要是指数据的属性信息,比如储存空间,访问热度,主题域
业界元数据中心产品
开源的有Netflix的Metacat、Apache Atlas;
商业化的产品有Cloudera Navigator。
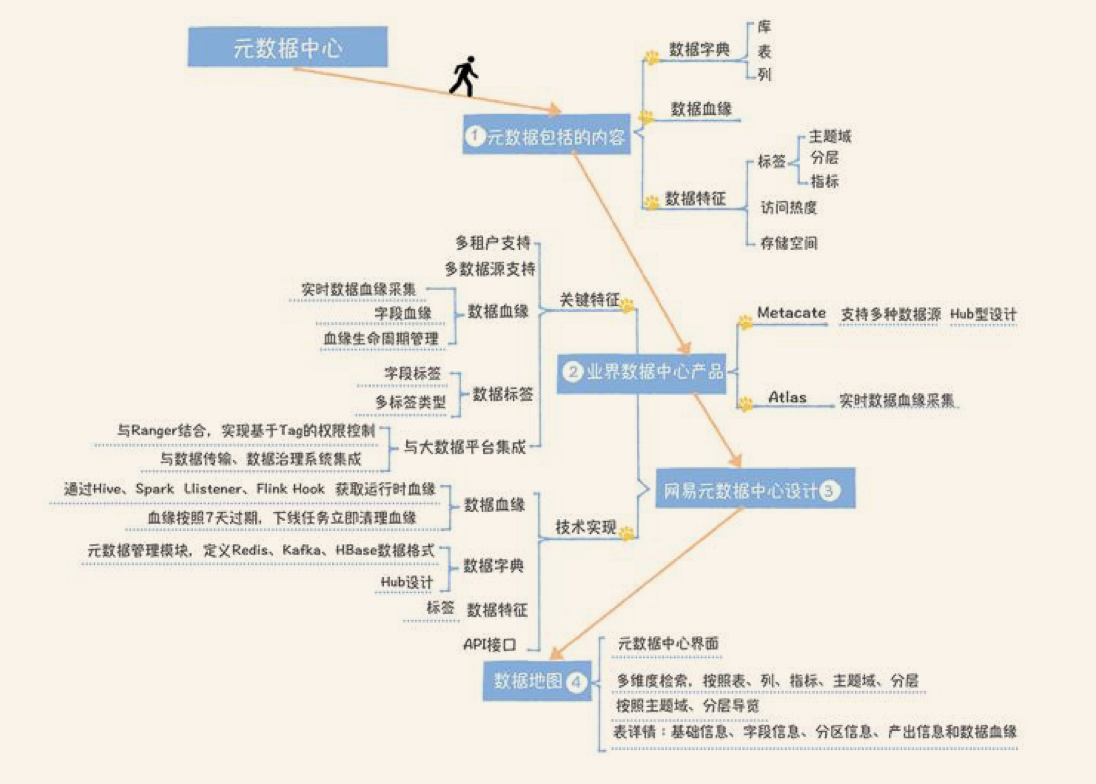
Metacat
多数据源集成型架构设计
从上面Metacat的架构图中,你可以看到,Metacat的设计非常巧妙,它并没有单独再保存一份元数据,而是采取直连数据源拉的方式,一方面它不存在保存两份元数据一致性的问题,另一方面,这种架构设计很轻量化,每个数据源只要实现一个连接实现类即可,扩展成本很低。
Apache Atlas 实时数据血缘采集
血缘采集,一般可以通过三种方式:
- 通过静态解析SQL,获得输入表和输出表;
- 通过实时抓取正在执行的SQL,解析执行计划,获取输入表和输出表;
- 通过任务日志解析的方式,获取执行后的SQL 输入表和输出表。
第一种方式,面临准确性的问题,因为任务没有执行,这个SQL对不对都是一个问题。第三种方式,血缘虽然是执行后产生的,可以确保是准确的,但是时效性比较差,通常要分析大量的任务日志数据。所以第二种方式,我认为是比较理想的实现方式,而Atlas 就是这种实现。对于Hive 计算引擎,Atlas 通过Hook方式,实时地捕捉任务执行计划,获取输入表和输出表,推送给Kafka,由一个Ingest 模块负责将血缘写入JanusGraph图数据库中。然后通过API的方式,基于图查询引擎,获取血缘关系。对于Spark,Atlas 提供了Listener的实现方式,此外Sqoop、Flink 也有对应的实现方式。
元数据中心
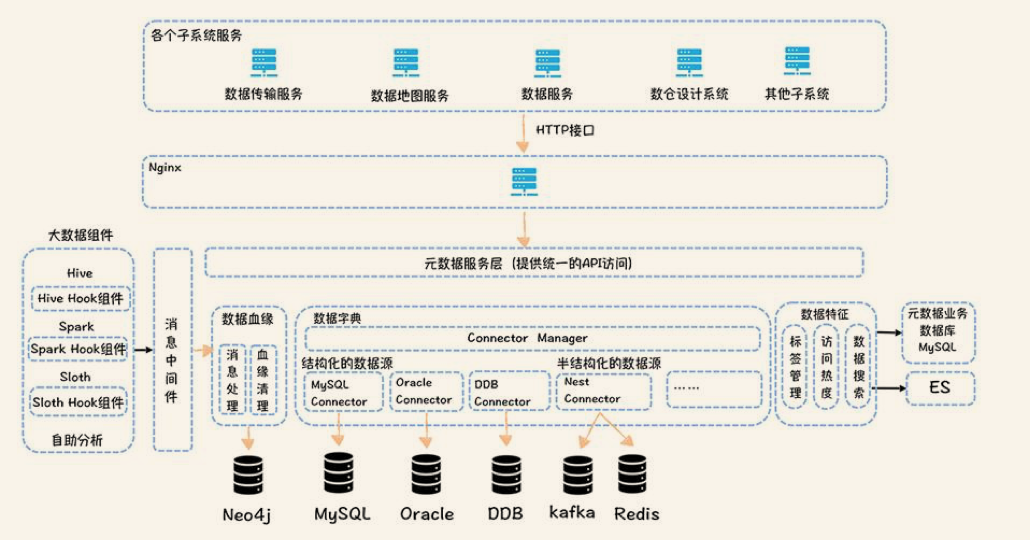
总结
元数据中心设计上必须注意扩展性,能够支持多个数据源,所以宜采用集成型的设计方式。数据血缘需要支持字段级别的血缘,否则会影响溯源的范围和准确性。数据地图提供了一站式的数据发现服务,解决了检索数据,理解数据的“找数据的需求”。