1.默认构造##
由于编译器会尽可能的为所有的警告和错误做出解释。但也因此导致了部分情况下的过度解析。
书中给的例子是编译器由于过度解析,使用了类型转换运算符的解析代码,导致隐藏了真正的错误。
cin << intval;
int temp = cin.operator int();
temp << intval;
分析一下:
- 程序员的目的是实现读取输入,但是误将 >> 写成了 <<,或者按照书中所说程序员本意是要写个cout的却写了个cin。无论如何,istream并没有重载 << 运算符,编译器一看这条路不通啊,于是只好按照 << 左移位来解析;,
- but,要想实现左移位,又必须将cin转成整型。那么编译器就去找istream有没有类型转换函数好将cin转成整型后再进行移位操作。如果找到了,那么,cin << intval; 正常执行了,并不报错。但不符合程序员的本意。
- 为了避免这种转换发生,istream中使用了operator void*()来替换operator int()。
如上体现了cin的int类型隐式转换可能造成的不良后果。
(1) 隐式类型转换###
隐式类型转换虽然会"暗地里"做一些转换操作,但这种机制的好处也是显而易见的。而且C++为了让这个"暗地里"的隐式操作能够被程序员察觉显形,提供了一个修饰符"explicit",类型转换构造函数和类型转换函数声明前加上explicit关键字将阻止编译器隐式类型转换操作。任何尝试隐式转换的操作都会报错。
如下:
#include<iostream>
using namespace std;
class A
{
public:
//explicit
A(int a):m_a(a)
{
cout << "construct A from int" << endl;
}
//explicit
operator int()
{
cout <<"convert A to int " << end;
return m_a;
}
public:
int m_a;
};
int main(void)
{
A a(5);//显式类型转换构造
A b = 5;//隐式类型转换构造
int i = a;//隐式类型转换函数
return 0;
}
- A a(5);总是正常的。
- 第一个explicit注释掉,A a(5);运行正常;打开该注释,编译提示:类型转换失败
- 第二个explicit注释掉,int i = a;运行正常。 打开该注释 编译提示:非法的存储类,即赋值失败。
(2) 默认构造函数###
讨论trivial和notirvial其实就是讨论构造函数存在的必要性。构造本质上要为对象的生成做一些辅助操作。
但如果对象生成的需求仅仅是分配空间就够了,那么构造函数其实也没有什么意义。
构造函数确实不是必须的,甚至于某些情况下,编译器连系统默认构造函数都不会提供。
比如有一个类就像C中结构体的一样,struct A* pa = new (sizeof(struct A));就足够,即定义式声明时不需要初始化成员变量和额外的代码调用操作,更不需要初始化虚函数表,或者虚基类表。那么编译器也没有必要提供一个默认构造多此一举了。
- 构造时先构造基类,再构造子类的非基类部分,析构时先析构子类的非基类部分,再析构基类。
- 初始化表用于指导基类子对象或者成员变量如何初始化,也包括类类型的成员变量。
- 基类子对象按照继承顺序必须在初始化表中指定构造方式,且必须在子类的非基类成员之前被构造出来
- 对于类类型成员变量,既可以按照初始化表中指示构造,也可以之后在构造函数中重新初始化对象成员。
- 子类构造函数执行时会先按照继承顺序插入调用各基类的构造函数的代码。再调用用户定义的子类的构造部分。
- 只要子类的基类子对象或者包含的类成员对象需要默认构造,子类就必须要提供默认构造除非基类连默认构造都不需要并且不含有需要默认构造的类成员对象。
- 如果有多个类成员对象都需要构造操作初始化操作,那么子类会在自己的构造函数中按照这些类类型对象的声明顺序依次调用各自的构造函数完成成员对象的构造,调用代码由编译器合成,而且即使在初始化表中有了其中某个成员对象的初始化,也不影响初始化顺序,只是编译器合成的代码会在顺序执行到该类的初始化时由初始化表中指定的该对象的构造形式进行构造,其他的类对象则依然由其类的默认构造形式进行构造。
class A
{
public:
A(){}
};
class B
{
public:
B(int b):m_b(b){}
B():m_b(0){}
private:
int m_b;
};
class C
{
public:
C(){}
};
class T
{
public:
T():b(3){ }
T(){}
private:
A a;
B b;
C c;
};
T():{}
这里编译器合成的伪码表示为
T()
{
A:A();
B:B();
C:C();
}
T():b(3){}
这里编译器合成的伪码表示为
T()
{
A:A();
B:B(3);
C:C();
}
- 基类如果是有参构造,则子类必须显式指定构造函数,因为要指示基类如何构造。提供的默认构造无法做到调用基类有参构造。故而需要自定义构造函数来指导基类构造方式。对于类的类类型成员变量也是如此。
综合来看,作者想要说明的是:在基类或者类成员没有自定义构造函数时默认构造函数的作用,在以下几种条件下会体现即:
- 有类类型成员变量需要被构造时,需要调用类类型成员的默认构造函数来调用该成员对象的默认构造。
- 有基类子对象需要被构造时,需要调用子类的默认构造函数来调用基类的默认构造
- 带有虚函数的类,需要其默认构造来初始化每个对象的vptr,注意:虚函数表和函数指针覆盖是在编译期完成的。
- 虚继承的类,需要其默认构造来初始化每个对象的虚基类表,注意:虚基类初始化表是在编译期完成的。
看作者总结的四种情况(没有自定义构造函数的情况下):
public class B
{
B(){}
};
class A
{
class B b;
};
- 类类型的成员变量需要调用默认构造,即B没有自定义构造时;
public class B
{
B(){}
};
class A:public class B
{
};
- 基类需要调用默认构造,即B没有自定义构造时
class A
{
virtual fun(){}
};
- 存在虚函数时需要通过默认构造函数来,即A::fun需要动态寻址时
class A : virtual public class B
{
};
- 存在虚基类时需要通过默认构造函数来,即A中的B子对象需要动态寻址时
2.默认拷贝构造###
(1)类需要执行拷贝构造的三种情形###
- 明确使用 = ;
- 对象作为实参;
- 作为返回值,不考虑编译器优化(部分编译器会把临时对象直接作为有名对象返回,从而减少一次拷贝构造)
注意:拷贝构造的本质是还是构造,本质操作是初始化操作,而非拷贝操作。
拷贝构造同样被分成了trivial和notirvial,是trivial还是notrivial和默认构造解释差不多。先理解下几个名词。
bitwise copy是编译器默认提供的位拷贝,即memcpy系列,以bit为单位。加个semantics(语意)引申意义后面讲。
memberwise init即基本类型成员的赋值,以成员为单位。
bitwise copy semantics:位拷贝语意,即一个类的拷贝构造过程中的初始化操作应该是固定且连续的memwise init,不能被安插子对象或者类类型的成员变量的拷贝构造(尽管子对象或者类类型的成员变量内部也是递归mmwise init的),另外也不能由于存在虚函数或者虚基类增加拷贝构造操作而在该类的拷贝构造中额外增加虚表指针或者虚基类表指针的重定位操作。
换句话说:bitwise copy semantics上只能有 POD数据类型C++ POD(Plain Old Data)类型
某些情况下对象不能有bitwise copy semantics,否则拷贝构造会出现问题。即上述的几个不能。
以下四种情况不应该表现出bitwise copy semantics,默认构造必须是notrivial的
- 含有拷贝构造的基类子对象
- 类类型成员变量有拷贝构造
- 类声明有虚函数时
- 类派生自虚基类时
notrivial的拷贝构造中涉及到类存在虚表指针的重新设定。
前两种,基类子对象或者类类型成员的拷贝构造必须被当前对象的拷贝构造调用。默认拷贝构造必须是notrivial。
类存在虚函数表vtbl时或者继承自虚基类时,需要重定虚表指针,默认拷贝构造必须是notirvial的。
也就是默认拷贝构造必须要有才行。
最终要回归trivial和notrivial,不要陷在bitwise copy semanstics里。
(2)拷贝构造时重定虚表指针###
虚函数表#####
vtbl虚函数表
vptr虚表指针
notrivial的拷贝构造中涉及到类存在虚表指针的重新设定。


如上类定义,如果有如下类声明
Bear yogi;
Bear winnie = yogi;
Bear类因为存在虚函数在编译期的Bear::Bear构造中就必须由编译期合成对虚函数表中各函数指针的初始化,实际上虚表中存的是各个Bear继承后的覆盖实现函数的实际地址。在winnie执行拷贝构造的时候,同样的构造函数也必须在编译期合成对应的拷贝构造来拷贝虚表指针,这种拷贝是本身是安全的。
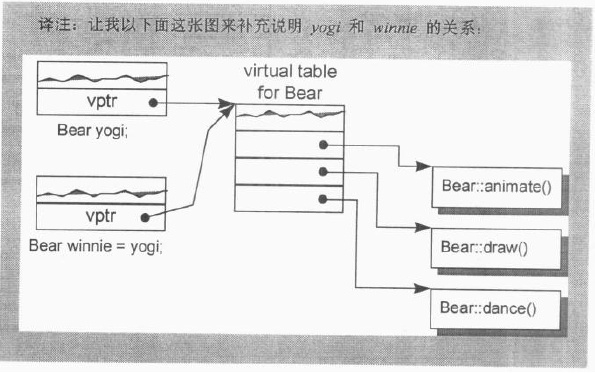
但是如果如下情况就不在安全
ZooAnimal franny = yogi;
franny非指针或者引用,由于类型的决定性,franny是ZooAnimal类型,其虚表指针指向的是ZooAnimal的虚表地址。
或者按照作者的表述如果直接用Bear的虚表指针覆盖ZooAnimal的虚表,则franny.Draw时会“炸毁”(blow up)...,作者归结为发生切割时yogi中的bear部分已经在franny拷贝构造时切割掉了。。。
否则franny.Draw()就会调用yogi.Draw()实现。
但franny.Draw()实际调用ZooAnimal::Draw();而如果virtual ZooAnimal::Draw()没有实现就会引发异常。
#include <cstdio>
#include <cstdio>
#include <iostream>
using namespace std;
class ZooAnimal
{
public:
ZooAnimal(){ }
virtual ~ZooAnimal(){}
virtual void animate(){}
virtual void draw() {cout << "ZooAnimal" << endl;}
//...
private:
//...
};
class Bear : public ZooAnimal
{
public:
Bear(){ };
virtual ~Bear(){ }
void animate(){ }
void draw(){ cout << "Bear" << endl;}
virtual void dance(){ }
private:
//...
};
int main()
{
Bear yogi;
Bear winnie = yogi;
winnie.draw();
ZooAnimal jenny = yogi;
jenny.draw();
ZooAnimal tonny;
return 0;
}
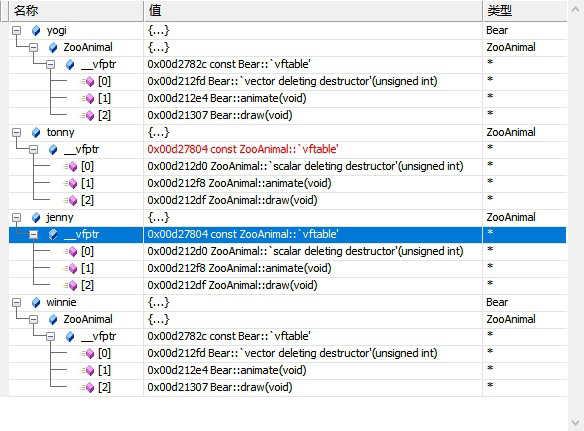
如上类型决定的虚表指针的值。通过jenny的虚表指针值可以看出,由编译器合成的默认拷贝构造函数会"明确设定"jenny对象的vptr的地址,并不是直接从yogi中拷贝过来的。
至于子类中关于扩展的虚函数dance没有出现时编译器隐藏了,实际可以通过打印调用进行展示,后续会有实例。
虚基类表####
#include <cstdio>
#include <iostream>
using namespace std;
class ZooAnimal
{
public:
ZooAnimal(){ }
virtual ~ZooAnimal(){}
virtual void animate(){}
virtual void draw() {cout << "ZooAnimal" << endl;}
//...
private:
//...
};
class Raccoon: public virtual ZooAnimal
{
public:
Raccoon(){}
Raccoon(int value){}
private:
///...
};
class RedPanda : public Raccoon
{
public:
RedPanda(){}
RedPanda(int value){}
private:
///...
};
int main()
{
RedPanda panda1;
RedPanda panda2 = panda1;
Raccoon raccoon = panda1;
return 0;
}
Raccoon虚继承ZooAnimal,在Raccoon中有自己的虚基类表,如果是相同类型的拷贝赋值则bitwise copy就好了,不会有问题,但是如果是Raccoon raccoon = panda1;将RedPanda类型切割赋值给Raccoon raccoon时就单纯的bitwise copy就无法满足要求了,所以Raccoon的拷贝构造函数必须要合成将RedPanda虚基类表指针重新指向Raccoon虚基类表的操作。
3.程序转化语意学##
(1)对象初始化###
类类型对象的初始化借助于 构造,拷贝构造,类型转换构造
(2)参数初始化###
void foo(X x0);
临时变量x0的构造和销毁,书中讲了两种方式,主要是编译时将临时变量的存储位置不同。
一种可以理解为栈中临时定义了一个X temp并拿实参进行初始化了,此时foo被改写成void foo(X& x0),而且x0 = temp;或者编译器能指示foo找到temp那么就不需要改写foo,直接将temp构建在其"应该的"位置。
(3)返回值初始化###

这里临时变量除了xx还有匿名对象返回值,先给个名字假如叫result
那么转换有如下预处理,即X& __result = result 。再看下面的代码就比较清晰了

相应的设计嵌套调用的



其中__temp0完成在bar函数中被拷贝构造,并借助()运算符重新返回右边的__temp0,然后继续调用X对象的memfunc()函数。
如果有函数指针,也需要在指针调用时作同样的转换

(4)返回值优化###
首先是传值(by value),即return局部变量必须是值类型,才能被优化。后续有对int类型的验证),
如:
X bar();
X result = bar();
X& __result = result;//忽略result的构造由伪码中的拷贝构造完成初始化

如上即编译器的返回值优化(NRV),编译器执行此优化的前提是存在拷贝构造。
#include <cstdio>
class Integer
{
public:
Integer(int i): m_i(i)
{
printf("构造函数
");
}~Integer()
{
printf("析构函数
");
}
Integer(const Integer &rhs)
{
printf("拷贝构造
");
m_i = rhs.m_i;
}
private:
int m_i;
};
Integer getInteger()
{
Integer inter(10);
return inter;
}
int main(void)
{
Integer inter = getInteger();
printf("--------------
");
return 0;
}

这里断点只执行到printf,其中构造函数为getInter局部的Integer inter(10);触发调用,拷贝构造为返回值优化调用,析构函数由getInteger函数的结束 } 调用,程序main的 } 会再次调用析构函数析构掉main中的局部inter(由getInter函数中常量优化拷贝构造的)。执行过程如下:


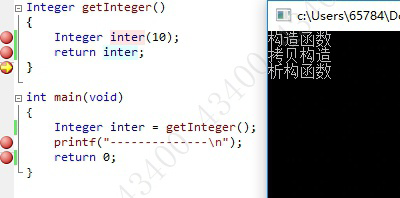
除了编译器可设定是否支持返回值优化,返回值优化是否是必要的?
如果用户没有显示声明拷贝构造函数,或者类是trivial(非四种必需要拷贝构造)的情况下,即使编译器参数指定返回值优化,会优化吗?
如上述示例实际上就是trivial类型但显示指定了拷贝构造函数的,可以看出是进行了返回值优化。进一步看看notrivial系统合成的拷贝构造会引发返回值优化。
#include <cstdio>
#include <string>
using namespace std;
class Integer
{
public:
Integer(int i): m_i(i)
{
printf("构造函数
");
}
~Integer()
{
printf("析构函数
");
}
//Integer(Integer& inter)
//{
// printf("空的拷贝构造
");
//}
private:
int m_i;
string m_str;
};
Integer getInteger()
{
Integer inter(10);
return inter;
}
int main(void)
{
Integer inter = getInteger();
printf("--------------
");
return 0;
}
注释掉显示的拷贝构造,但是增加类类型成员string,已知该类型包含拷贝构造且必将引发编译器对Integer类合成拷贝构造。
通过VS的反汇编验证下:

构造跳转位置

拷贝构造跳转位置

构造实现

合成的拷贝构造实现
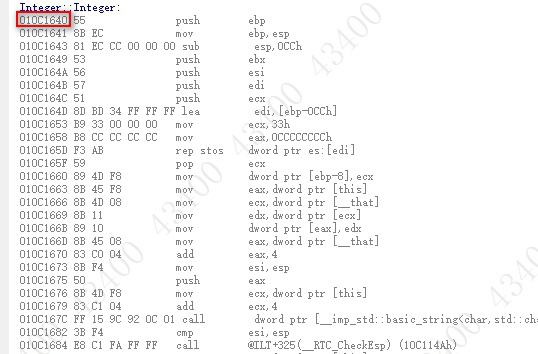
故而可以断定,触发了拷贝构造,确认进行了返回值优化。
综上,可以确定,返回值优化,只要有拷贝构造函数就会触发,不管是自己定义的还是系统合成的。
那么对于普通数据类型是否有返回值优化呢?
简单测试一下,
#include <cstdio>
#include <string>
using namespace std;
int getInteger()
{
int a = 10;
return a;
}
int main(void)
{
int i = getInteger();
return 0;
}
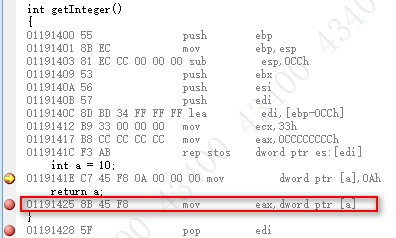
返回时只是将临时变量存入寄存器eax
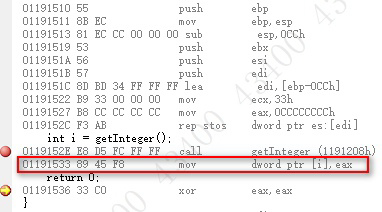
再将寄存器的值拷贝到外部变量。
可见基本类型变量并没有返回值优化,类似返回指针和引用类型也无法优化。
(5)深拷贝####
类似于类中存在指针类型数据需要深拷贝一样,在自定义拷贝构造需要额外考虑存在虚表指针的情况。如下
如下shape包含隐藏的虚表指针:

编译器自动合成的拷贝构造bitwise copy会直接拷贝虚表指针,但不会考虑深拷贝。
用户自定义拷贝构造函数时涉及虚表时既需要注意深拷贝,同时不要破坏原有的虚表指针(同类型拷贝)。
4.初始化表###
必须使用初始化表的4中情况
(1)初始化一个引用类型成员时
(2)初始化一个常量类型成员时
(3)基类的构造,而且拥有一组参数时
(4)类成员的构造,而且拥有一组参数时
初始化表指示成员在定义的时候如何初始化,而非在用户代码中重新进行初始化操作,从而节省一次构造操作,从而增加效率。
陷阱1:初始化表中书写顺序并非真实成员变量的初始化顺序。

成员变量的定义顺序是按照声明顺序进行分配内存空间的,但是并没有初始化。
构造函数的中的初始化表仅仅用来指示如何初始化,不影响定义顺序。
构造函数中的用户代码,用于进一步指定部分成员变量的如何初始化。
陷阱2:在构造函数中通过成员函数进行成员初始化,不要引入初始化表中的成员,不建议这样写,即使能够确保初始化表中成员一定先于在该函数调用之前被初始化。本质原因还是因为初始化表并非真实的初始化顺序。

当其被扩充后,如下

如果xfoo使用到了j,而成员i,j定义顺序为先i后j则在调用xfoo初始化i的时候实际上j还没有被初始化,如果仅仅看了初始化表会误以为j已被val正常初始化了。
下面通过始化表对类成员的构造顺序影响。
#include <cstdio>
#include <string>
using namespace std;
class Integer
{
public:
Integer()
{
m_i = 3;
printf("Integer构造函数
");
}
~Integer()
{
printf("Integer析构函数
");
}
private:
int m_i;
};
class Floater
{
public:
Floater(float f): m_f(f)
{
printf("Foater构造函数
");
}
~Floater()
{
printf("Floater析构函数
");
}
private:
float m_f;
};
class Doubler
{
public:
Doubler()
{
m_d = 0.0f;
printf("Doubler构造函数
");
}
~Doubler()
{
printf("Doubler析构函数
");
}
Doubler& operator= (const Doubler& rhs)
{
m_d = rhs.m_d;
printf("Doubler赋值函数
");
return *this;
}
Doubler(const float& f)
{
m_d = f;
printf("Doubler类型转换构造函数
");
}
private:
double m_d;
};
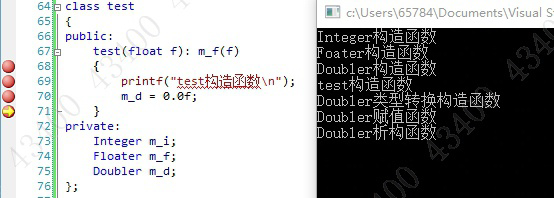
class test
{
public:
test(float f): m_f(f)
{
printf("test构造函数
");
m_d = 0.0f;
}
private:
Integer m_i;
Floater m_f;
Doubler m_d;
};
int main(void)
{
test t(0.03f);
getchar();
return 0;
}
如下,初始化列表起指示作用,并没有真正的执行定义式声明操作。
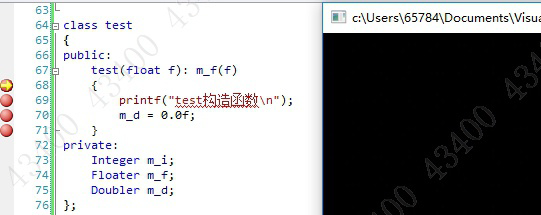
执行到左花扩号后按照声明顺序和初始化表的指示进行了构造,
即在用户代码被执行前由编译器合成了按照声明顺序进行定义的代码
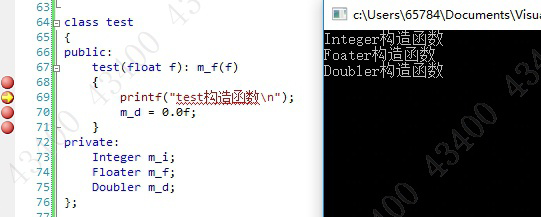
通过初始化表直接指定初始化方式属于构造,而通过用户代码进行初始化,属于拷贝构造,或者赋值。
需要考虑对程序性能的影响。
陷阱3:存在继承关系的时候,子类对象先构造基类,如果构造基类的过程中依赖的子类未被初始化的成员,引入风险

扩展后的伪码表示:
