创建输出
当执行测试,创建多个输出文件和所有的 都以某种方式相关测试结果。 本节讨论什么 输出创建、如何配置创建,以及如何 调整他们的内容。
不同的输出文件
本节解释了不同可以创建和输出文件 如何配置创建。 输出文件配置 使用命令行选项,这让输出文件的路径 问题作为参数。 一个特殊的值 没有一个 (不区分大小写)可用于禁用创建一个特定的输出 文件。
输出目录
所有输出文件可以设置使用绝对路径,在这种情况下他们 创建指定的地方,但在其他情况下,路径是什么 认为相对于输出目录。 默认的输出 目录的目录执行开始,但它 可以改变的吗——outputdir(- d) 选择。 的路径 设置此选项,再一次,相对于执行目录, 但可以自然也被作为一个绝对路径。 无论如何 获得一个单独的输出文件路径,它的父目录 是自动创建的,如果它不存在了。
输出文件
输出文件包含所有测试执行结果以机器可读的XML 格式。 日志 , 报告 和 xUnit 生成文件通常是基于他们, 他们也可以结合起来,否则进行后期处理 Rebot 。
提示
从机器人框架2.8,生成 报告 和 xUnit 文件的一部分测试执行了不需要处理 输出文件。 禁用 日志 可以生成运行时测试 节省内存。
命令行选项 ——输出(- o) 决定了路径 相对于创建的输出文件 输出目录 。 默认的 输出文件的名称,当运行测试, output.xml 。
当 后处理输出 也没有创建,室内可容纳新的输出文件 除非 ——输出 选择是显式地使用。
可以禁用创建输出文件的运行时测试 给一个特殊的值 没有一个 到 ——输出 选择。 之前的机器人 Framework 2.8这也禁用自动创建日志和报告文件, 但现在不做了。 如果不需要输出,他们应该 明确残疾人使用 ——输出问题,报告没有日志 。
日志文件
日志文件包含在HTML细节执行测试用例 格式。 他们有一个层次结构显示测试套件,测试 情况和关键字的细节。 几乎每次需要日志文件 测试结果要详细调查。 尽管日志文件 也有统计,报告是最好的 得到一个更高层次的概述。
命令行选项 ——日志(- l) 决定了日志 文件被创建。 除非特殊价值 没有一个 使用, 创建日志文件总是和他们的默认名称 log.html 。
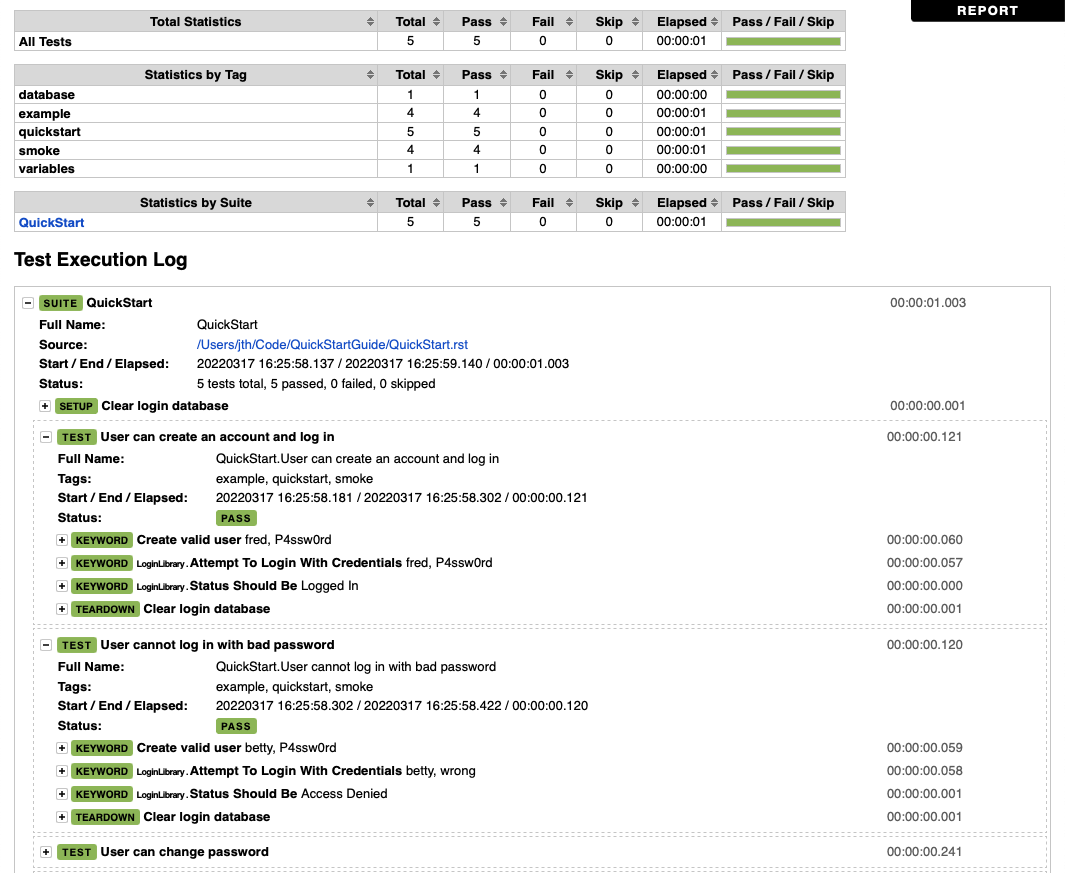
开始一个日志文件的一个示例
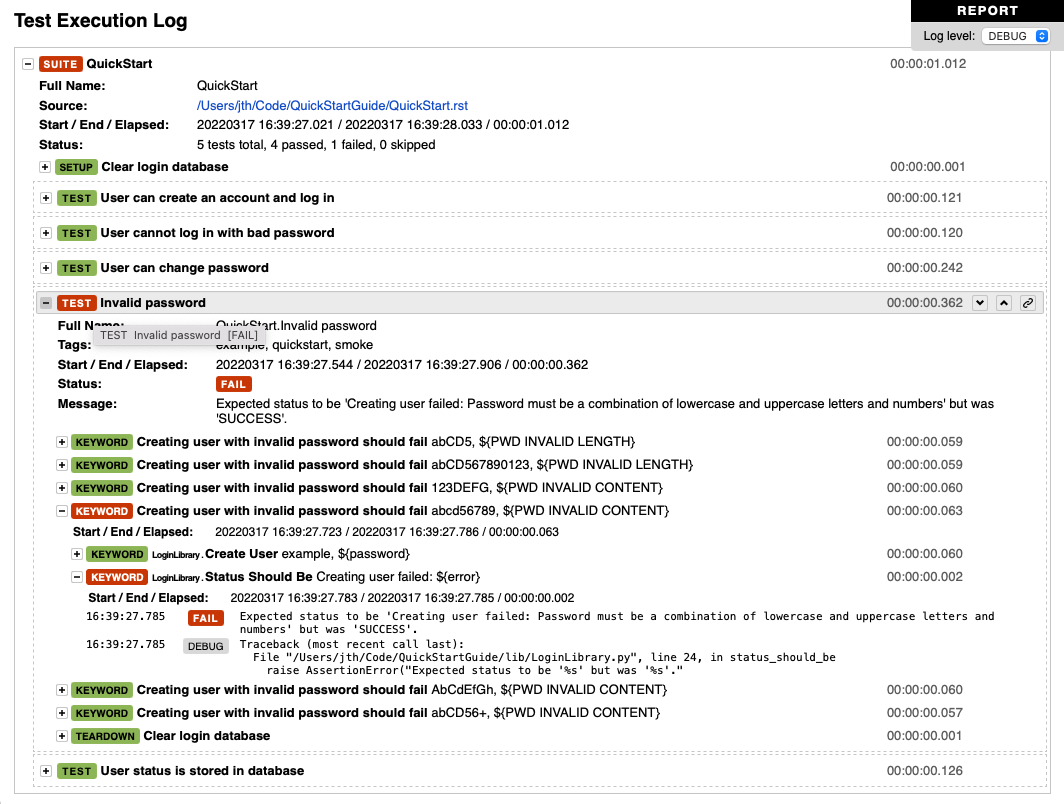
日志文件的一个例子与关键字细节可见
报告文件
报告文件包含HTML测试执行结果的概述 格式。 他们有统计数据基于标签和执行测试套件, 以及所有测试用例执行的列表。 当这两份报告, 生成日志,日志文件的报告链接容易 导航到更详细的信息。 它很容易看到 整体测试执行状态报告,因为它的背景 颜色是绿色的,如果所有 关键的测试 通过和明亮的红色 否则。
命令行选项 ——报告(- r) 决定了 创建报告文件。 总是同样的日志文件,报告 创建的,除非 没有一个 作为一个值,默认 的名字是 report.html 。
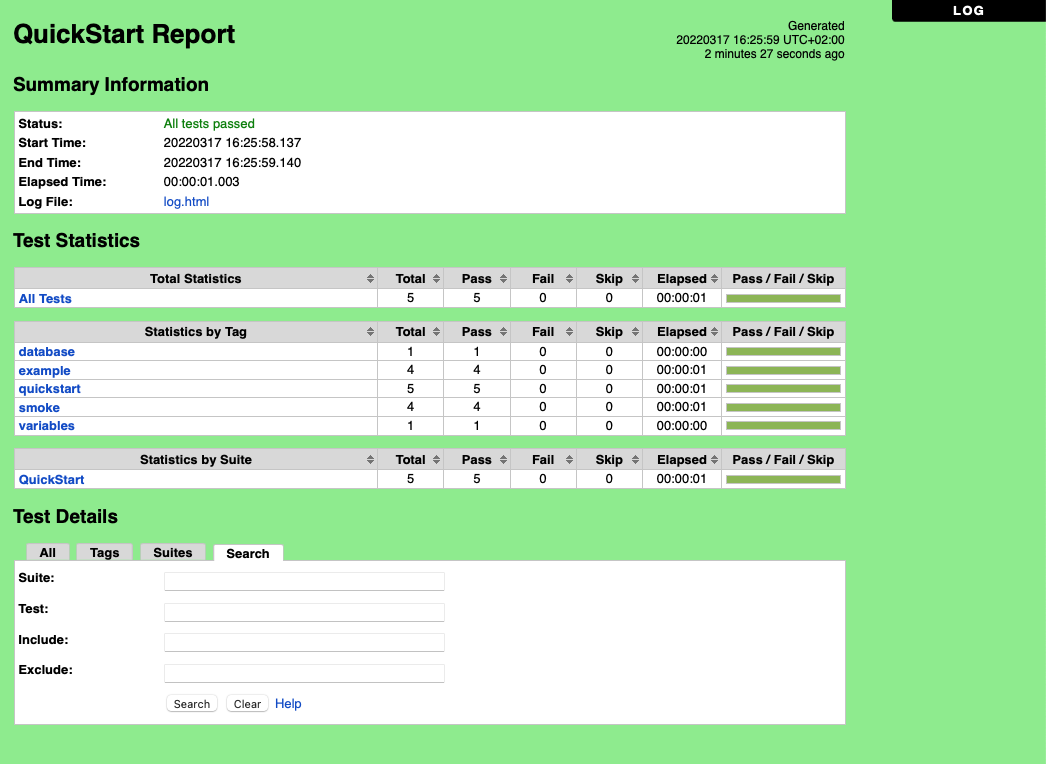
一个例子成功的测试执行报告文件
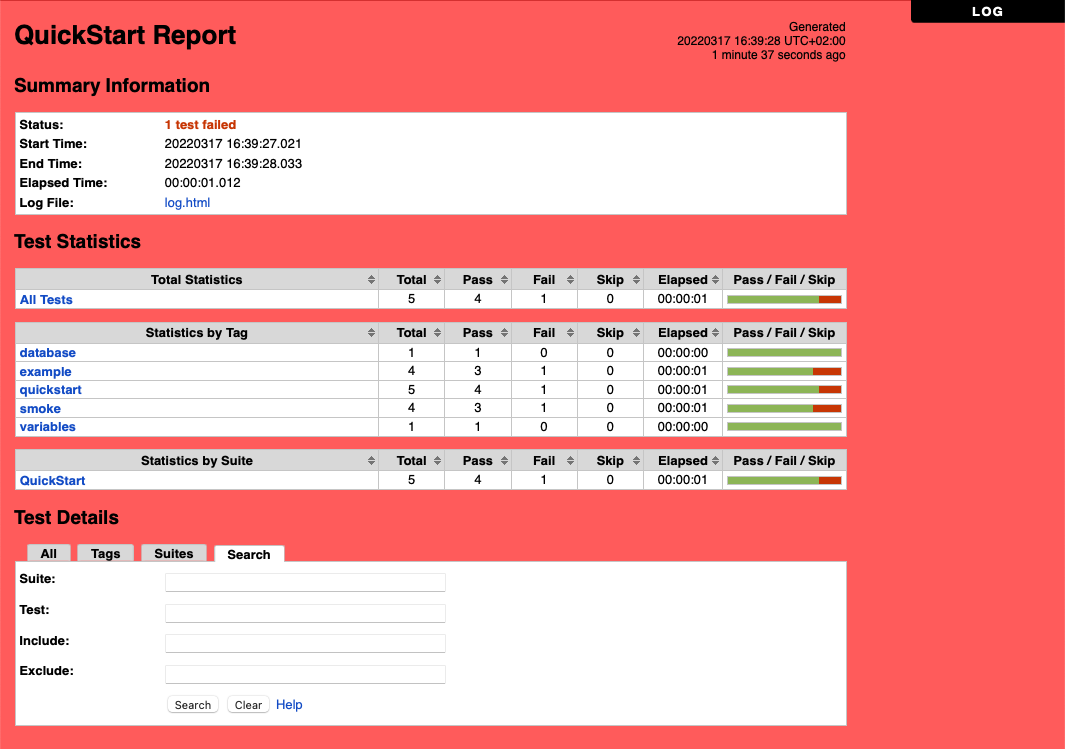
一个例子文件失败的测试执行报告
XUnit兼容的结果文件
XUnit测试执行结果文件包含总结 xUnit 兼容的 XML格式。 因此可以使用这些文件作为输入的外部工具 理解xUnit报告。 例如, 詹金斯 持续集成服务器 基于xUnit兼容支持生成统计数据 结果。
提示
詹金斯也有一个单独的 机器人框架插件 。
XUnit不能创建输出文件,除非命令行选项 ——xunit(- x) 显式地使用。 这个选项需要一个路径 生成的xUnit文件,相对的 输出目录 作为一个价值。
因为xUnit报告没有的概念 非关键测试 , xUnit中的所有测试报告将通过或失败了,没有 区分关键和非关键测试。 如果这是一个问题, ——xunitskipnoncritical 选项可用于非关键标记测试 跳过。 跳过测试会包含实际状态和消息 可能的消息格式的测试用例 失败:错误消息 。
请注意
——xunitskipnoncritical 是一个新选项在机器人框架2.8。
调试文件
调试文件是纯文本文件,在测试期间写的 执行。 从测试库编写所有消息, 以及信息开始和结束测试套件、测试用例 和关键词。 调试文件可用于监控测试 执行。 例如,可以使用一个单独的 fileviewer.py 工具,或者在类unix系统中,简单的 尾巴 - f 命令。
调试文件不是,除非创建命令行选项 ——debugfile(- b) 显式地使用。
时间戳输出文件
在本节中列出的所有输出文件可以自动时间戳 与选择 ——timestampoutputs(- t) 。 当使用该选项时, 时间戳的格式 YYYYMMDD-hhmmss 被放置在 扩展和每个文件的基本名称。 下面的例子, 例如,创建等输出文件 - 20080604 - 163225. - xml输出 和 mylog - 20080604 - 163225. - html :
robot --timestampoutputs --log mylog.html --report NONE tests.robot
设置标题
默认的标题 日志 和 报告 是由前缀 顶级测试套件的名称 测试日志 或 测试报告 。 自定义标题可以从命令行 使用的选项 ——logtitle 和 ——reporttitle , 分别。 强调了在给定的名称转换为空间 自动。
例子:
robot --logtitle Smoke_Test_Log --reporttitle Smoke_Test_Report --include smoke my_tests/
设置背景颜色
默认情况下, 报告文件 有一个绿色背景当所有的吗 关键的测试 通过和一个红色的背景。 这些颜色 可以通过使用定制的 ——reportbackground 命令行 选项,这需要两个或三个颜色与冒号作为分离 论点:
--reportbackground blue:red --reportbackground green:yellow:red --reportbackground #00E:#E00
如果指定两种颜色,第一个将代替 默认的绿色和第二而不是默认的红色。 这 允许,例如,使用蓝色而不是绿色背景 色盲的人容易分开。
如果你指定三种颜色,将使用第一个当所有的 测试成功,第二个当只有非关键测试失败了, 最后当有关键的失败。 这个特性从而允许 使用一个单独的背景颜色,例如黄色,当 非关键测试失败了。
指定的颜色值 身体 元素的 背景 CSS属性。 按原样使用和价值 可以是一个HTML颜色名称(如。 红色的 ),一个十六进制值 (如。 # f00 或 # ff0000 ),或者一个RGB值 (如。 rgb(255,0,0))。 默认的绿色和红色的颜色 指定使用十六进制值 # 9 e9 和 # f66 , 分别。
日志级别
可用的日志级别
消息 日志文件 可以有不同的日志级别。 的一些 消息是由机器人框架本身,但也执行 关键字可以 日志信息 使用不同的水平。 可用的 日志级别:
失败- 时使用一个关键字失败。 只可用于机器人框架本身。
警告- 用于显示警告。 他们也显示在 控制台和 测试执行日志文件错误部分 ,但他们 不影响测试用例的状态。
信息- 正常的默认级别信息。 默认情况下, 消息日志文件中没有显示低于这个水平。
调试- 用于调试目的。 有用的,例如,对于 内部日志库在做什么。 当一个关键字失败时, 回溯显示在代码中发生了错误在哪里 自动登录使用这个级别。
跟踪- 更详细的调试级别。 关键字参数和返回值 使用这个级别自动登录。
设置日志级别
默认情况下,日志消息下面 信息 水平不记录,但这个 阈值可以从命令行用改变 ——loglevel(- l) 选择。 这个选项需要的任何 可用的日志级别作为参数,变成了新的水平 阈值水平。 一个特殊的值 没有一个 还可以使用吗 完全禁用日志记录。
可以使用 ——loglevel 选择当 后处理输出 与。室内可容纳 例如,这使得 最初的运行测试 跟踪 水平,并生成更小 日志文件后与正常查看 信息 的水平。 默认情况下 所有的信息包含在执行期间也被包括 。室内可容纳 消息忽略执行期间无法恢复。
修改日志级别的另一种可能性是使用 内装式 关键字 设置日志级别 在测试数据。 需要相同的 参数的 ——loglevel 选项,并返回 旧的水平,以便它可以恢复后,例如,在一个 测试 拆卸。
可见的日志级别
2.7.2从机器人框架,如果日志文件中包含的消息 调试 或 跟踪 水平,可见日志级别下拉 在右上角。 这允许用户删除下面的消息选择 水平的观点。 这可以运行测试时特别有用 跟踪 的水平。
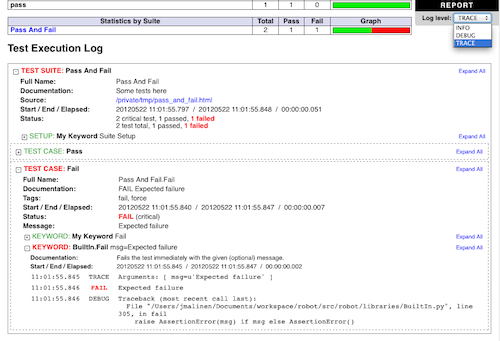
一个示例日志显示可见的日志级别下拉
默认下拉将在日志文件的最低水平 显示所有消息。 默认日志级别可以改变使用可见 ——loglevel 选择给正常后的默认日志级别 冒号隔开:
--loglevel DEBUG:INFO
在上面的示例中,使用水平运行测试 调试 ,但 默认的日志文件是可见的水平 信息 。
通常情况下,日志文件是一个HTML文件。 当他测试的数量 病例增加,文件的大小可以长得这么大,打开它 浏览器不方便,甚至是不可能的。 因此,可以使用 的 ——splitlog 选择登录外部文件的分割部分 在需要的时候,被透明地装载到浏览器。
劈柴的主要好处是如此之小,个人日志部分 ,打开和浏览日志文件是可能的,即使金额 的测试数据是非常大的。 一个小缺点是总体规模 日志文件的增加。
技术相关的测试数据保存到每个测试用例 一个JavaScript文件在同一文件夹作为主要的日志文件。 这些文件有 的名字,如 日志- 42. - js 在哪里 日志 的基本名称是 主日志文件和42 是一个递增索引。
请注意
复制日志文件时,你也需要复制的所有 日志- * . js 文件或将缺少某些信息。
配置数据
有几个命令行选项,可用于配置 和调整的内容 统计数据的标签 , 统计数据 的套件 和 测试细节标签 表中不同的输出 文件。 所有这些选项工作都当在执行测试用例 后处理输出。
配置显示套件统计
当一个更深层次的套件执行结构,显示所有测试套件 水平 统计的套件 表可能会让表 有点难以阅读。 默认情况下,所有套房所示,但是你可以 控制命令行选项 ——suitestatlevel 哪一个 以套件显示水平作为参数:
--suitestatlevel 3
包括和不包括标签数据
当许多标签, 统计数据的标签 表可以成为 很拥挤。 如果发生这种情况,命令行选项 ——tagstatinclude 和 ——tagstatexclude 可以 用于选择要显示的标签,同样 ——包括 和——排除 是用来 选择测试 情况下 :
--tagstatinclude some-tag --tagstatinclude another-tag --tagstatexclude owner-* --tagstatinclude prefix-* --tagstatexclude prefix-13
生成标记结合统计数据
命令行选项 ——tagstatcombine 可用于 生成聚合来自多个标签结合统计数据 标签。 使用指定的组合标签 标记模式 在哪里 * 和 吗? 支持通配符和 和 , 或 和 不 运营商可用于结合 个人标签或模式。
下面的示例说明了如何创建结合标记统计使用 不同的模式,下图显示了一个代码片段产生的 统计数据的标签 表:
--tagstatcombine owner-* --tagstatcombine smokeANDmytag --tagstatcombine smokeNOTowner-janne*

结合标记数据的例子
像上面的例子所示,添加的名称统计相结合 默认情况下,给定的模式。 如果这还不够好, 可以给一个自定义名字模式后将它们分开呢 用冒号( : )。 可能突显出名称的转换 空间:
--tagstatcombine prio1ORprio2:High_priority_tests
创建标记名称的链接
您可以添加外部链接 统计数据的标签 表的 使用命令行选项 ——tagstatlink 。 争论这个 选项给出的格式 标签:链接:名字 ,在那里 标签 指定链接的标签分配, 链接 是链接到 被创建,的名字 是给的链接。
标签 可能是一个单一的标签,但更常见的吗 简单的模式 在哪里 * 匹配任何东西, 吗? 匹配任何单个的 的性格。 当 标签 是一个模式,通配符的比赛可能吗 被用在 链接 和 标题 与语法 % N , “N”是匹配的索引从1开始。
下面的示例说明了如何使用这个选项,和 下图显示了一个代码片段产生的 统计 标签 表当例子测试数据执行这些选项:
--tagstatlink mytag:http://www.google.com:Google --tagstatlink jython-bug-*:http://bugs.jython.org/issue_%1:Jython-bugs --tagstatlink owner-*:mailto:%1@domain.com?subject=Acceptance_Tests:Send_Mail

标签名称的链接的例子
删除和压扁的关键词
大部分的内容 输出文件 来自关键字和他们 日志消息。 在创建更高级别的报告时,日志文件不一定是 需要,在这种情况下关键字和他们的信息只需要空间 不必要的。 日志文件本身也可以长得过于大,特别是 它们包含 for循环 或其他结构重复某些关键词 很多次了。
在这些情况下,命令行选项 ——removekeywords 和 ——flattenkeywords 可以用来处理或平不必要的关键词。 时都可以使用 执行测试用例 当 后处理 输出 。 使用时,在执行期间,他们只影响到日志文件,不是 XML输出文件。 与 rebot 他们甚至影响日志 生成新的输出XML文件。
删除关键字
的 ——removekeywords 选择删除关键字和他们的消息 完全。 它具有以下的操作模式,可以使用它 多次启用多个模式。 包含的关键字 错误 或警告 不删除除非使用 所有 模式。
所有- 无条件删除数据从所有关键词。
通过了- 删除关键字的数据通过的测试用例。 在大多数情况下,日志文件 使用这个选项创建包含足够的信息来调查 可能的失败。
为- 删除所有通过迭代 for循环 除了最后一个。
WUKS- 删除所有失败的关键字 内装式 关键字 等到关键词成功 除了最后一个。
模式名称:< >- 删除数据匹配给定的模式无论从所有关键词 关键字状态。 的模式是 匹配关键字的全名,前缀 可能的库或资源文件的名字。 模式的情况下,空间, 强调不敏感,它支持 简单的模式 与
*和吗?作为通配符。 标记:<模式>- 删除数据从关键词标签匹配给定的模式。 标签是 情况和空间不敏感,他们可以指定使用 标记模式 在哪里
*和吗?支持通配符和和,或和不运营商可用于结合个人标签或模式。 可以使用这两个 库关键字标签 和 用户关键词标签 。
例子:
rebot --removekeywords all --output removed.xml output.xml robot --removekeywords passed --removekeywords for tests.robot robot --removekeywords name:HugeKeyword --removekeywords name:resource.* tests.robot robot --removekeywords tag:huge tests.robot
删除关键字解析后完成 输出文件 和生成 一个内部的模型基于它。 因此它不减少内存使用量 作为 压扁的关键词 。
请注意
支持使用 ——removekeywords 当执行测试 以及 为 和 WUKS 模式中加入了机器人 2.7框架。
请注意
模式名称:< > 模式是在机器人框架2.8.2和补充道 标记:<模式> 在2.9。
压扁的关键词
的 ——flattenkeywords 选择趋于平缓匹配的关键字。 在实践中 这意味着匹配关键字得到所有日志消息从他们的孩子 关键字、递归和孩子关键词被丢弃。 压扁 支持以下模式:
为- 平 for循环 完全。
FORITEM- 平个人for循环迭代。
模式名称:< >- 平关键词匹配给定的模式。 模式匹配规则 时一样 删除关键字 使用
模式名称:< >模式。 标记:<模式>- 平与标签关键字匹配给定的模式。 模式匹配 规则时一样 删除关键字 使用
标记:<模式>模式。
例子:
robot --flattenkeywords name:HugeKeyword --flattenkeywords name:resource.* tests.robot rebot --flattenkeywords foritem --output flattened.xml original.xml
压扁的关键词时,已经完成 输出文件 解析 最初。 这可以节省大量的内存尤其是 深度嵌套关键字结构。
请注意
压扁的关键词是2.8.2机器人框架中的一个新特性, 为 和 FORITEM 被添加在2.8.5和模式 标记:<模式> 在2.9。
设置开始和结束时间执行
当 结合输出 使用,室内可容纳可以设定开始 和结束时间的测试套件使用选项 ——开始时间 和 ——endtime ,分别。 这是方便的,因为默认情况下, 组合套件没有这些值。 当开始和结束时间 ,时间也计算。 否则运行 时间是通过增加了运行时间的孩子一起测试套件。
还可以使用上述选项设置开始和结束 时间一个套件当使用。室内可容纳 使用这些选项 单输出总是影响套件的运行时间。
次必须有时间戳的格式 YYYY-MM-DD hh:mm:ss.mil ,所有分隔符是可选的部分 毫秒时间可以忽略。 例如, 2008-06-11 17:59:20.495 是等价的, 20080611 - 175920.495 和 20080611175920495 ,也仅仅是 20080611 是可行的。
例子:
rebot --starttime 20080611-17:59:20.495 output1.xml output2.xml rebot --starttime 20080611-175920 --endtime 20080611-180242 *.xml rebot --starttime 20110302-1317 --endtime 20110302-11418 myoutput.xml
编程式的修改结果
如果提供的内置功能修改结果是不够的, 机器人Framework 2.9定制修改和更新提供了可能 以编程方式。 这是通过创建一个模型修改和完成 激活使用 ——prerebotmodifier 选择。
这个功能工作几乎完全一样 编程式的修改 测试数据 可以启用的 ——prerunmodifier 选择。 最明显的差别是,这一次修饰符的操作 结果模型 ,而不是 运行模型 。 例如,下面的修饰符 是所有通过测试时间已经超过允许失败:
from robot.api import SuiteVisitor
class ExecutionTimeChecker(SuiteVisitor):
def __init__(self, max_seconds):
self.max_milliseconds = float(max_seconds) * 1000
def visit_test(self, test):
if test.status == 'PASS' and test.elapsedtime > self.max_milliseconds:
test.status = 'FAIL'
test.message = 'Test execution took too long.'
如果上面的修饰符将在文件 ExecutionTimeChecker.py ,它 可以被使用,例如,像这样:
# Specify modifier as a path when running tests. Maximum time is 42 seconds. robot --prerebotmodifier path/to/ExecutionTimeChecker.py:42 tests.robot # Specify modifier as a name when using Rebot. Maximum time is 3.14 seconds. # ExecutionTimeChecker.py must be in the module search path. rebot --prerebotmodifier ExecutionTimeChecker:3.14 output.xml
如果需要多个模型修改器,他们可以通过使用指定 的 ——prerebotmodifier 多次选择。 在执行测试时, 可以使用 ——prerunmodifier 和 ——prerebotmodifier 选择在一起。
系统日志
机器人有自己的纯文本框架系统日志写到 信息
- 和跳过测试数据文件进行处理
- 导入测试库、资源文件和变量文件
- 执行测试套件和测试用例
- 创建输出
一般用户不需要此信息,但并不是不可能 有用的机器人当调查问题测试库或框架 本身。 创建一个系统日志不是默认情况下,但它可以启用 通过设置环境变量 ROBOT_SYSLOG_FILE 所以 它包含一个路径选择的文件。
一个系统日志一样 日志级别 作为一个正常的日志文件, 例外,而不是 失败 它有 错误 的水平。 阈值水平使用可以改变使用 ROBOT_SYSLOG_LEVEL 环境变量如所示 下面的例子。 可能的意想不到的错误和警告 是 写入系统日志除了控制台和正常 日志文件。
#!/bin/bash
export ROBOT_SYSLOG_FILE=/tmp/syslog.txt
export ROBOT_SYSLOG_LEVEL=DEBUG
robot --name Syslog_example path/to/tests