GTID的作用
那么GTID功能的目的是什么呢?具体归纳主要有以下两点:
- 根据GTID可以知道事务最初是在哪个实例上提交的
- GTID的存在方便了Replication的Failover
这里详细解释下第二点。我们可以看下在MySQL 5.6的GTID出现以前replication failover的操作过程。假设我们有一个如下图的环境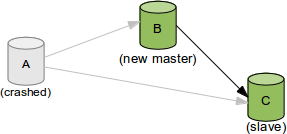
此时,Server A的服务器宕机,需要将业务切换到Server B上。同时,我们又需要将Server C的复制源改成Server B。复制源修改的命令语法很简单即CHANGE MASTER TO MASTER_HOST='xxx', MASTER_LOG_FILE='xxx', MASTER_LOG_POS=nnnn。而难点在于,由于同一个事务在每台机器上所在的binlog名字和位置都不一样,那么怎么找到Server C当前同步停止点,对应Server B的master_log_file和master_log_pos是什么的时候就成为了难题。这也就是为什么M-S复制集群需要使用MMM,MHA这样的额外管理工具的一个重要原因。
这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server C当前停止点的GTID就能唯一定位到Server B上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。 So easy不是么?






